

Архив недели @siberianpython
Вторник
Всем привет!
Меня зовут Дима, я работал дата саентистом и разработчиком в области биоинформатики. То есть, я "программист", который общается с врачами и биологами. В России работал в двух биологических стартапах, потом переехал в Данию, где только что закончил PhD 🥳 1/2
На этой неделе пообщаюсь с вами про дата саенс в биологии и медицине: про технологический стек, про политику и бюрократию, про отличия коммерческой компании и университета, России и Дании, про особенности рынка труда в этой области, и про её (области) прекрасное будущее. 2/2
P.S. Прошу прощения за опоздание к началу недели 😅
Давайте спросим вас, про что бы вы хотели послушать?
🤔
24.9% Что такое биоинформатика?🤔
41.0% Великая война R и python🤔
20.2% Политика в медицине🤔
13.9% Университет vs коммерцияА пока, предлагаю такое расписание:
вт: знакомимся, я коротко расскажу что такое биоинформатика, и почему она в твиттере data science underhood
ср: обсудим, что это за рынок труда, какие у него особенности, чем отличается, и что в биоинформатике классного
чт: поворчим о проблемах: разрыв между CS и domain knowledge экспертами, политика, нерелевантное обучение
пт: заглянем в технологический стек, python vs R, откуда это различие берётся, и что лучше учить
сб: поговорим о будущем, куда эта область движется
вс: концерт по заявкам
Как что учить? Матлаб, конечно twitter.com/dsunderhood/st…
Матлаб топчик! Лучше него может быть только матлаб с сишной библиотекой для симуляций химической кинетики, над которой я один раз работал. Если не забуду - будет кулстори для выходных, о том как я эту симуляцию в 3 раза ускорил одним if-ом. twitter.com/kingofpewpew/s…
Биоинформатика - это очень обширная область. Сюда входят: - математики, которые делают сложные алгоритмы биологам (популярность падает) - программисты, которые делают ПО для биомедицинских устройств - data scientist'ы, которые анализируют данные и пр.
Кто такой биоинформатик
Говоря просто, я DS/программист, который приходит к биологам и врачам и делает их работу в 10 раз проще и в 100 раз быстрее.
[описание честно украдено у самого себя из прошлого - twitter.com/abroadunderhoo…]

В области DS биоинформатики занимаются:
- пре-процессингом research-use only данных с приборов (и его автоматизации)
- построением дашбордов "про биологию / медицину"
- статистическим анализом результатов (от регрессий до навороченных библиотек)
- построением банков данных
- etc.
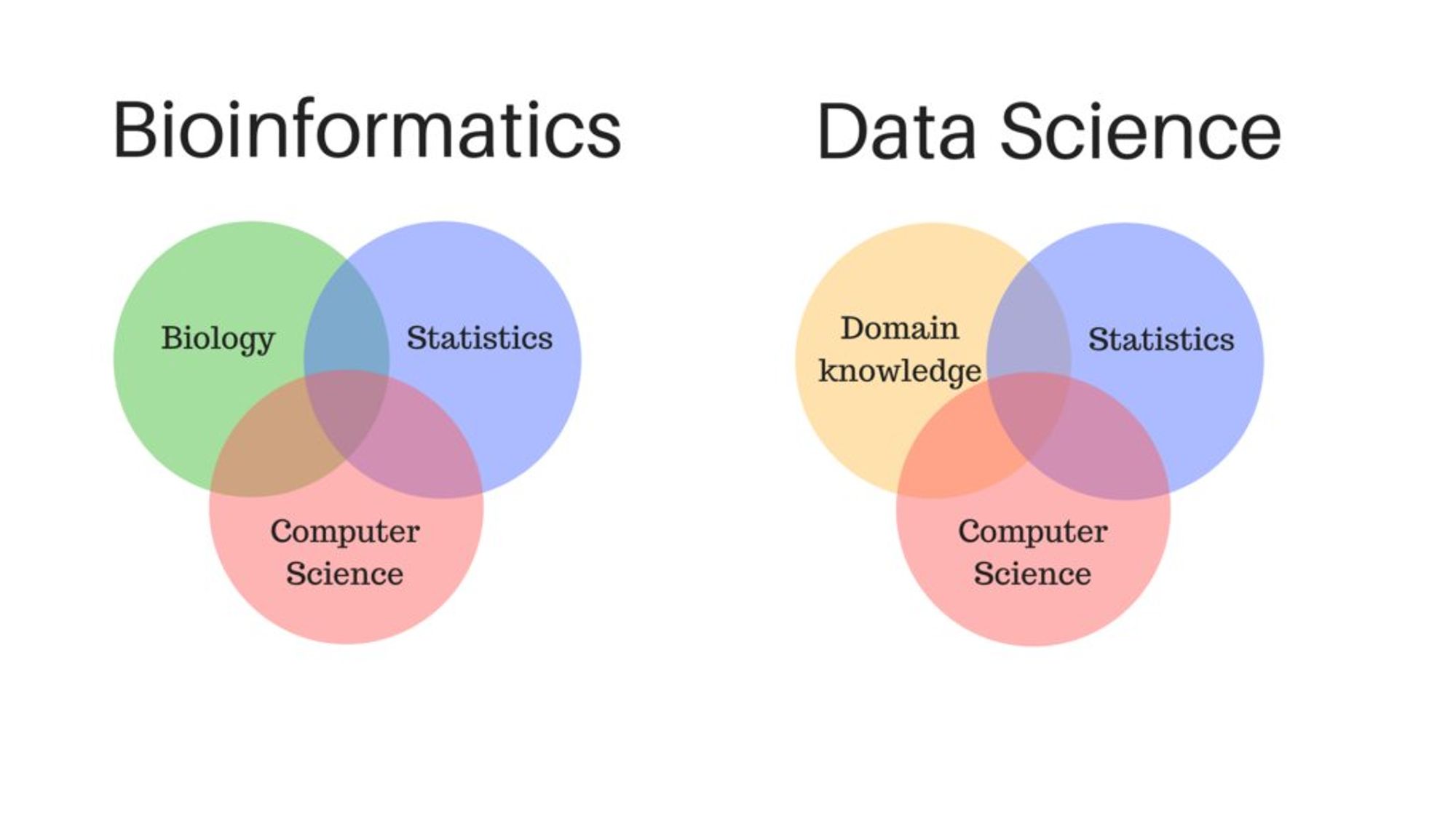
Есть очень много разных областей, которые называют "биоинформатика", "системная биология", "вычислительная биология", "биостатистика" и т.п. Я называю биоинформатикой любое сочетание биологии/медицины и DS/программирования и/или статистики/математики (обязательная картинка)
На английском языке могу порекомендовать вот этот замечательный и совершенно недооценённый канал про биоинформатику - youtube.com/watch?v=MuZAsI…
Люди, которые сделали интерактивный дашборд с числом случаев короны в Дании - ssi.dk/covid19data - в каком-то смысле биоинформатики.
Люди, сделавшие каталог результатов GWAS исследований ebi.ac.uk/gwas/ - тоже.
Пример пре-процессинга и анализа данных визуализировать сложнее, но именно на эти позиции нанимают большинство биоинформатиков. Вот, например, очень хороший и стабильный, и в целом считающийся простым, пайплайн анализа данных секвенирования:
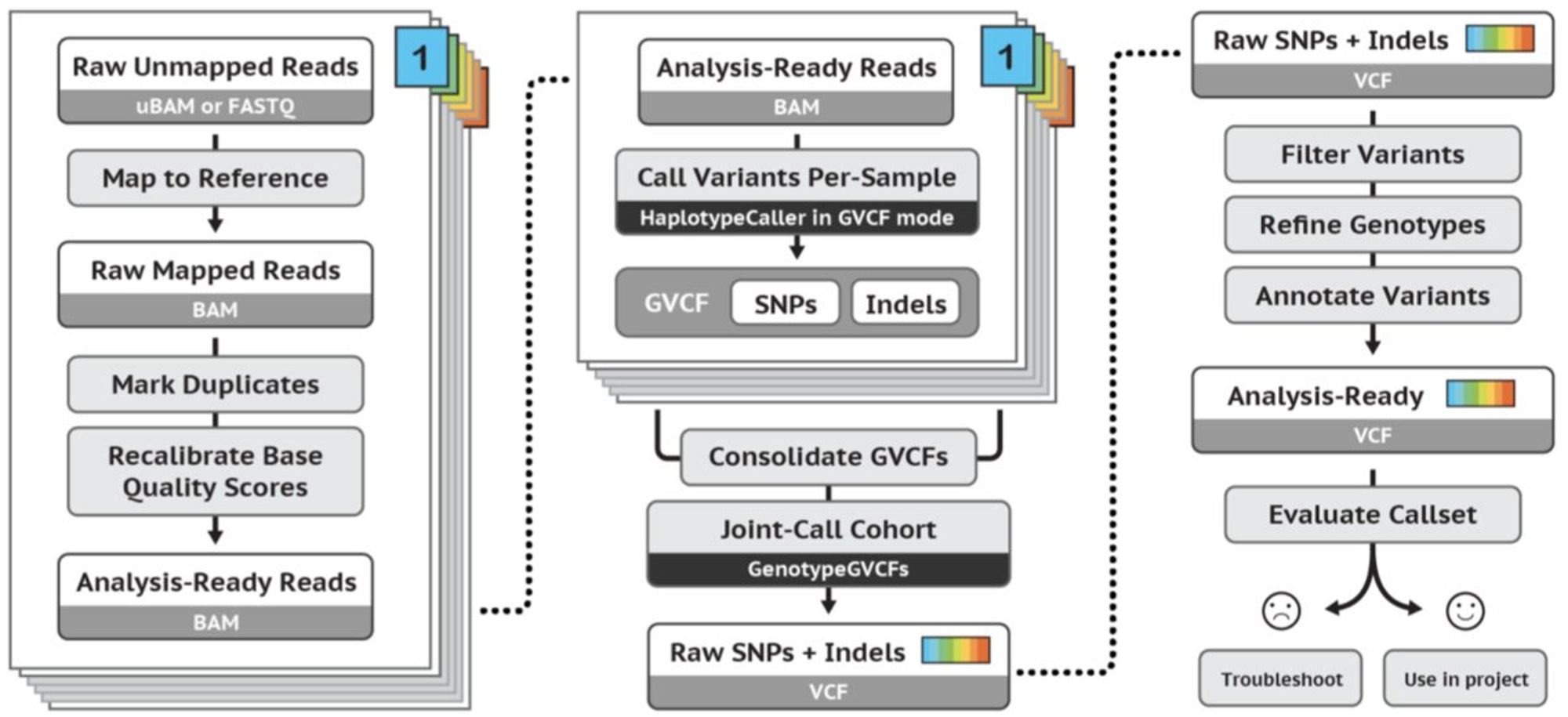
Я пришел в биоинформатику с математическим+программистским бэкграундом, но это скорее исключение. Чаще биологи начинают заниматься анализом своих данных, и приходят к биоинформатике. Поговорим о том, почему так, когда будем обсуждать рынок труда.
Тред (Дима Борисевич)
Среда
Всем доброе утро 😅 поотвечаю на ваши вопросы, пока просыпаюсь :-)
@dsunderhood Биоинформатики чувствуют свою важность? Т.е. они могут видеть результаты своего труда в решение каких-то проблем?
Зависит от человека, но я бы сказал, что конечно да. Многие вообще говорят что-то вроде "Мы тут спасаем жизни и здоровье, а не цвет кнопки меняем", что по-моему снобство, но хорошо показывает убеждение в собственной важности :-) twitter.com/gopherizer/sta…
@dsunderhood Когда биоинформатика перестанет быть "the next big thing" и станет "the big thing"? :)
Аххахахахаххха twitter.com/TEarth42/statu…
Поговорим серьёзно на выходных :-) моё личное убеждение - у этого есть возможность произойти в течение 10 лет максимум. Произойдёт ли - 🤷♂️
Давайте спросим вас, про что бы вы хотели послушать?
В опросе побеждает вариант про языки и был вопрос про стек, поэтому давайте сегодня поговорим про технологии! twitter.com/dsunderhood/st…
Идеи на сегодня:
- кластер или cloud (или макбук)
- R, python, и другие
- B2B биоинфо сервисы - существуют ли они
- примеры стека в отдельных областях
"DSL" в биоинформатике
Исторически, биоинформатики используют много языков. Как правило это происходит так: кто-то написал важную для масс спектрометристов / генетиков / пр. библиотеку, которая не запускается как отдельный тул из консоли.
1/n
Все в этой области вынужденно начинают использовать этот язык и писать следующие библиотеки на этом же языке. И через 5 лет целая область имеет свой собственный почти DSL, состоящий из какого-то язык программирования (не всегда популярный) + 200 библиотек.
2/n
Я говорю "DSL", потому что использующий эти библиотеки код будет как правило на 80% состоять из вызовов очень узко-специальных библиотек. Такой код будет непонятно выглядеть для DS-универсала, но будет абсолютно понятен биоинформатику
3/n
Именно это произошло с языком R. Много математиков, которые заинтересовались геномикой, транскриптомикой, и другими т.н. -омиками, начали писать пакет за пакетом на R, и в итоге сейчас эти области должны использовать R и bioconductor - репозиторий с >2K специализированных пакетов
Слышал, что в физике такая же история с упомянутых вчера матлабом
5/n
Как правило эти пакеты реализуют какой-то хитрый собственный алгоритм, который нельзя за 5 минут переписать на sklearn, поэтому варианта перехода на другой язык не остается.
6/6
Тред (Дима Борисевич)
"DSL" в биоинформатике Исторически, биоинформатики используют много языков. Как правило это происходит так: кто-то написал важную для масс спектрометристов / генетиков / пр. библиотеку, которая не запускается как отдельный тул из консоли. 1/n
Кстати, написание своих алгоритмов и пакетов - это ещё один пример того, чем занимаются биоинформатики. Но это скорее дизайн алгоритмов и разработка, чем DS. twitter.com/dsunderhood/st…
R, python, или просто bash?
Если вы работаете в биоинформатике, то 90%, что вы пишете скрипты на баше, питоне, или R. Много тулов также написано на Java и меньше на C, но они как правило написаны хорошо один раз и запускаются из консоли, поэтому знать эти языки не нужно.
1/

Еще лет 5-10 назад был популярен perl, но его, слава богу, вытеснил python, и мы можем о нем забыть.
Последние 2-3 года люди тут и там говорят о языке Julia, который позволять импортировать пакеты прямо из python и R, но пока он стал популярен (и, лично надеюсь, не станет)
2/
Страшный "секрет" состоит в том, что на самом деле, у вас нет выбора, на чем писать. Язык определяется той областью биологии, в которой вы будете работать. Упомянутые выше -омики? R ваш выбор. Собираете пайплайн из вчерашнего треда? bash. Анализ изображений? python.
3/
Общие тренды такие:
- автоматизация анализа - bash, python, snakemake, airflow
- пре-процессинг сырых данных - либо есть тул для bash, либо это код на R
- визуализация - часто shiny R, Jupiter, и др. способы сделать html-отчёт
- анализ результатов - R и python
- ML - python
4/
В целом, ценность узко-специальных пакетов вкупе с невозможностью (пока) легко портировать код между языками определяет, какой язык будет доминировать в той или иной области биоинформатики
5/5
Тред (Дима Борисевич)
Языки и люди
Я заметил, что часто биоинформатики, пишущие на python - это люди с бэкграундом в CS, DS, и т.п., на R - в основном переучившиеся биологи + математики / статистики. Это отчасти определяет немного разное коммьюнити.
1/
Тулы на python часто запускаются как stand-alone, а их туториалы подразумевают, что вы программист и фокусируются на деталях.
Пакеты на R часто требуют написания своего кода на R, который соберёт вместе 5 функций из пакета, туториалы простые и ориентированы на биологов.
2/2
python
Я могу рассказать про свой личный выбор стека. Я работаю с генетическими данными 80% времени, остальные 20% - с различными данными о пациентах, которые приходят ко мне в виде таблиц Excel
1/
Тулы для генетики написаны в 1990-2010-х, запускаются stand-alone, и работают с отдельными файлами. Их я собираю вместе либо в bash, либо (если больше трех строчек) - кодом на python (в смысле, что я вызываю тул на баше, но отслеживаю файлы и порядок вызова в python).
2/
Результаты из этих тулов + данные Excel собираю вместе и анализирую в python. Основные пакеты, которые все используют (кроме отмеченных ):
- numpy, pandas для быстрых структур данных
- scipy, sklearn, statsmodels для анализа
- seaborn, plotly для визуализации
3/3
R, python, или просто bash? Если вы работаете в биоинформатике, то 90%, что вы пишете скрипты на баше, питоне, или R. Много тулов также написано на Java и меньше на C, но они как правило написаны хорошо один раз и запускаются из консоли, поэтому знать эти языки не нужно. 1/ pic.twitter.com/mLIvIEj1Pd
Ах да, самый важный DSL биоинформатики- это, конечно, MS Excel! twitter.com/dsunderhood/st…
Hardware
Удивительно, но большинство анализов в биоинформатике не используют облако! Как правило анализ идёт либо на макбуке биоинформатика, либо на изолированном от мира кластере.
1/
Кластер популярен для а. приватных индивидуальных данных людей или б. больших наборов данных.
Макбук популярен, потому что позволяет писать код, не задумываясь о том, заработает ли он на другом компьютере (это плохо сказывается на воспроизводимости науки =/)
2/
По мере того, как больше программистов приходит в биоинформатику, слава богу, облако медленно завоёвывает популярность.
3/
@dsunderhood по собесам этим летом мне показалось, что большинство стартапов используют облако, изолированные кластеры остались только в академии?
Пока не успел эту тему затронуть, но полностью согласен, что стартапы предпочитают облако. Потому, что можно с инвестиций в 0 рублей начать использовать машины на 64 процессора и много Гб памяти. А в академии и правда часто используют "крутой" (купленный 10 лет назад) кластер. twitter.com/overshare_et_a…
Впрочем, как мне кажется, стартапы бывают с разным менеждментом. И код, который работает только на одном ноутбуке аналитика, я видел и в академии, и в стартапах, куда выпускники академии приходят и продолжают воспроизводить привычные им практики =/
Давайте вас спросим, какой у вас бэкграунд относительно академии и не-академической науки?
🤔
12.0% Я и сам биоинформатик🤔
14.7% Я DS в академии но не био🤔
38.7% Я DS в коммерческом R&D🤔
34.7% Я DS не в R&D@dsunderhood Но в облаке нет HPC. Или биоинформатикам это не нужно?
По моему опыту, в целом скорее нет. Поскольку у биологов исторически не было суперкомпьютеров, и людей, способных под них программировать, то они пользовались простыми компьютерами. Делали алгоритмы исходя из этих требований к железу. И не нуждались в железе, и круг замкнулся. twitter.com/gopherizer/sta…
Кластеры существуют (скорее в академии, см. твиты ниже), но я не уверен, что они входят в определение HPC?
Ну и понятно, что всегда можно найти научную задачу, которой нужен и суперкомпьютер и два, но на массовом рынке труда в биоинфо это скорее исключение, кмк.
@dsunderhood В академии вы едва ли сможете официально оплатить облачные мощности, кроме как из зарплаты. Плюс, не всё можно тащить в облако (персональные данные, секретность итп). И это не только и не столько в академии.
Про деньги, ну, хорошо ли это для развития науки? :-)
Про данные согласен и написал в другом твите. twitter.com/VorontsovIE/st…
@dsunderhood В Гугл облаке уже есть возможность для HPC оказывается cloud.google.com/blog/topics/hpc
Космически! Я и не знал twitter.com/gopherizer/sta…
Пятница
Прошу прощения, что пропустил вчера, дела затянули. Нагоняем сегодня =)
В комментариях развернулась дискуссия об академическом DS против коммерческого, а большинство из вас в опросе ответили, что вы не из академии. Поэтому предлагаю сегодня пофлудить об академии.
В академической биоинформатике, на мой взгляд, всё очень и очень плохо =/
Академические биологи (и тем более врачи), с которыми я работал, почти никогда не изучали программирование, CS и алгоритмы, математику и т.п. Можно понять - курсы по биологии и медицине и так огромные.
Но в результате получается неосознанная некомпетентность (это когда ты так мало знаешь, что даже не понимаешь насколько мало). Я видел тонны PhD и постдоков, которые тратят месяцы своей работы на то, что при хорошо выстроенных DS процессах, должно считаться за дни или даже минуты
Дальше это подстёгивается сломанной системой поощрений. В биологии существует представление о том, что учёный должен делать всё сам. Бюрократы в HR биологических институтов и в фондах с деньгами как правило ориентируются на статьи (в отличие, может быть, от других областей науки)
Порядок авторства имеет значение. Считается круто быть первым автором статьи (если ты исполнитель), или последним (если ты босс). Всё остальное - это так себе, мимо проходил. Такой взгляд на KPI совсем не помогает здоровой совместной работе.
В результате биологи не хотят давать совместное первое авторство биоинформатикам ("я месяцы в лабе был, а он просто что-то посчитал"), а крутые биоинформатики не хотят работать с такими биологами ("столько времени потрачу, а они мне первого автора не дадут").
Тред (Дима Борисевич)
С точки зрения одного человека, такая система в академии может быть и хорошо - этот человек будет много знать и уметь, и, как ему кажется, дорого стоить (имо, нет). Но с точки зрения системы, отсутствие разделения труда - это катастрофа.
Именно поэтому я уверовал больше в коммерческую науку, причем именно в маленькой компании или стартапе (потому что в большой компании похожие на академию бюрократические и политические проблемы). Маленькая компания не может позволить себе работать в 1% от своего потенциала.
А академия может. Она вообще направлена на то, чтобы "впустую" тратить деньги, потому что "святые" фундаментальные исследования, как известно, отличаются от "грязной" коммерции тем, что ищут истину, а не на чём бы заработать.
И опять же, можно сказать, что это плюс академии, потому что человек с крутой, но выглядящей безумной, идеей, может её годами изучать без коммерческого выхлопа. Например Каталин Карико изучает 30 лет мРНК, а потом бац - и на основе её исследований делают вакцину от коронавирус.
Но по-моему это не так. По-моему, академическая система отбирает политиков и бюрократов, а не профессионалов или хотя бы визионеров =/
(заканчиваю ворчание, и возвращаюсь к теме "компании vs академия")
А маленькая компания за это время будет работать над выхлопом, и в результате индивидуальный DS-биоинформатик в компании будет чувствовать, что он делает гораздо более крутые штуки, чем он/она же в академии.
К тому же, возвращаясь к статьям, индивидуальный биоинформатик довольно сильно зависим от тех, у кого есть данные.
В итоге, конкретно взятый биоинформатик в академии будет рано или поздно ощущать, что занимается какой-то фигней, а его технологические навыки, ввиду отсутствия здоровой конкуренции, застряли 10 лет назад. Как мне кажется.
Тред (Дима Борисевич)
В работе в академии есть ещё одна проблема - зарплата. Если вы достаточно крутой DS, чтобы работать с данными от которых зависит человеческое здоровье и жизнь, то и в условный FAANG вы устроитесь. В результате, возникают ситуации, когда люди уходят из академии за деньгами.
Я знаю человека, который 10 лет работал в академии, получил самый крутой оффер на продление контракта во всём университете, и всё равно ушел работать в банк, т.к. зп там была на 30% больше (дело было в Дании).
Три причины разрыва в зп. Во-первых, считается, что в учёные идут люди мотивированные (а значит им можно платить поменьше). Во-вторых, в бюджетно-финансируемых университетах (а их много) как правило зп фиксировано и не очень высокое. В-третьих, есть интересный конфликт наук ⬇️
Большинство лидеров команд и групп в биологии - биологи. Для них на рынке труда просто нет альтернативы, кроме, места в "большой фарме" или "биотехе" - речь о крупнейших фарм-компаниях типа Pfizer, Novo Nordisk, пр., это как FAANG, только в биологии.
Но в отличие от FAANG, большая фарма не нанимает много опытных биологов. У этих фирм бОльшая часть бизнеса - это производство + продажи, и только маленькая R&D, в отличие от продуктовых софтверных компаний. Поэтому фармы на всех не хватит.
В итоге биологи в Европе часто довольны своей зарплатой в науке (и поменьше в Штатах). И вот они стали руководителем группы спустя 10 лет тяжелой работы, получили крутую, как им кажется зп.
И приходит к такому руководителю на собеседование на биоинформатика два кандидата - неуверенный в себе студент из университета, и DS из частного бизнеса. И второй, "непонятно за что", хочет зарплату вдвое выше, чем студент, и на 20% выше, чем у самого руководителя.
И в этом, как мне кажется, и есть самое главное зло в современной академии в биоинформатике. Самые крутые профессионалы уходят в FAANG, просто потому, что там лучше оффер.
Ведь в академии (биологии) как считается - да, зп у нас не очень, карьерные перспективы отсутствуют (отдельная боль). Но зато есть свобода делать, что хочешь; умные и воспитанные коллеги; интересная работа. Так в FAANG, считается, что это тоже есть + зп и карьерные перспективы.
Я прошу прощения, что опять ворчу, но это моя личная глубокая боль. Из научной группы, где я работал, ушло двое гениальных DS, оба мои менторы, а с наймом новых были долго проблемы. И у меня теперь искажение: мне (не только мне) кажется, что из академии все крутые уходят.
Тред (Дима Борисевич)
@dsunderhood Учёный должен быть голодным?
Закончу ворчание этим ретвитом. Конечно нет. Конечно же учёный должен быть в топ-5% по зарплате, потому что этот человек впитал в себя образования за долгие годы, которое стоило миллионы рублей. Но на практике, всё не совсем так, потому что рынок труда жесток и беспощаден. twitter.com/ivn_finaev/sta…
Хотя, имо, рынок труда вполне себе норм, а проблема в неготовности и неумении "гениальных" ученых торговаться за оффер. Я сам был одним их них, но потом опыт в коммерции прострелил мне колено.
Давайте разбавим мой гнев нейтральным разговором о рынка труда в биоинформатике.
Как мне кажется, в целом, всё как в любом DS. Очень зависит от области, и от страны + конкретного места.
В коммерции можно зарабывать 10 Козуль в наносекунду, а можно посредственные деньги. В академии - зависит от места, но обычно зп будет выше медианы по стране, но ниже, чем в коммерции (под медианой я имею ввиду по всем профессиям вообще, не только биоинформатику).
Интересный момент - слова в вакансии влияют на позицию и зарплату. В Дании так: если ищут bioinformatician, computational biologist, то часто это будет позиция рутинного ручного анализа, выполнение известных анализов без изобретения собственных, с з/п пониже; либо B2B консалтинг.
Если слова data engineer [пусть даже in bioinformatics], data scientist, machine learning engineer, то как правило речь именно об автоматизации, большем фокусе на исследования и открытие своих анализов, и з/п повышается.
Кажется дело в том, откуда пришел менеджер, написавший вакансию, какой у него/неё бэкграунд, и соответственно, ожидания от работы, которую будут делать сотрудники.
Вообще, чем больше фокус на биологию в вакансии, тем ниже зарплата в оффере 💔
Тред (Дима Борисевич)
Кстати, про разницу стран. Я уже очень подробно писал про Данию в аброаде тут - abroadunderhood.ru/siberianpython/ , и успел даже про культуру и работу поговорить. Могу вот ещё что акцентировать: в Дании (и северной Европе вообще) нет гигантского разрыва в зарплатах между IT и остальными.
Разрыв, конечно, есть, но не такой огромный. Пока в России кто-то получает 20К, а кто-то 400К, в Дании самый крутой DS будет получать максимум вчетверо больше, чем продавец в ларьке, до налогов. Скорее вдвое-втрое, а эту разницу ещё и подъест прогрессивный налог.
Это не значит, что денег не хватает (хотя кому как, конечно). Жить можно в удовольствие на зарплату DS в Дании, наверное даже и вдвоем на одну зарплату (я лично не пробовал, но выглядит реально).
Но давайте я лучше вас спрошу, есть ли у вас про работу DS именно в Дании вопросы? Задавайте их под этим твитом, я отвечу на все. Я большой сторонник переезда, и северная Европа - прекрасное место, но мне не хочется твиттер DSunderhood забивать Данией =)

Но давайте я лучше вас спрошу, есть ли у вас про работу DS именно в Дании вопросы? Задавайте их под этим твитом, я отвечу на все. Я большой сторонник переезда, и северная Европа - прекрасное место, но мне не хочется твиттер DSunderhood забивать Данией =) pic.twitter.com/YPLt9dHool
P.S. Кстати, если кто сам живёт в Дании или поблизости - напишите мне в личный аккаунт, сходим пива попьем. twitter.com/dsunderhood/st…
Я так долго говорил о проблемах академии, что могло сложиться ощущение, что вся биоинформатика - хреновая область DS. Это совсем не так, и на выходных мы обязательно поговорим о том, почему это самая крутая и перспективная область DS!
Давайте я вам расскажу о примерах каких-то крутых биоинформатических открытий / разработок последнего времени.
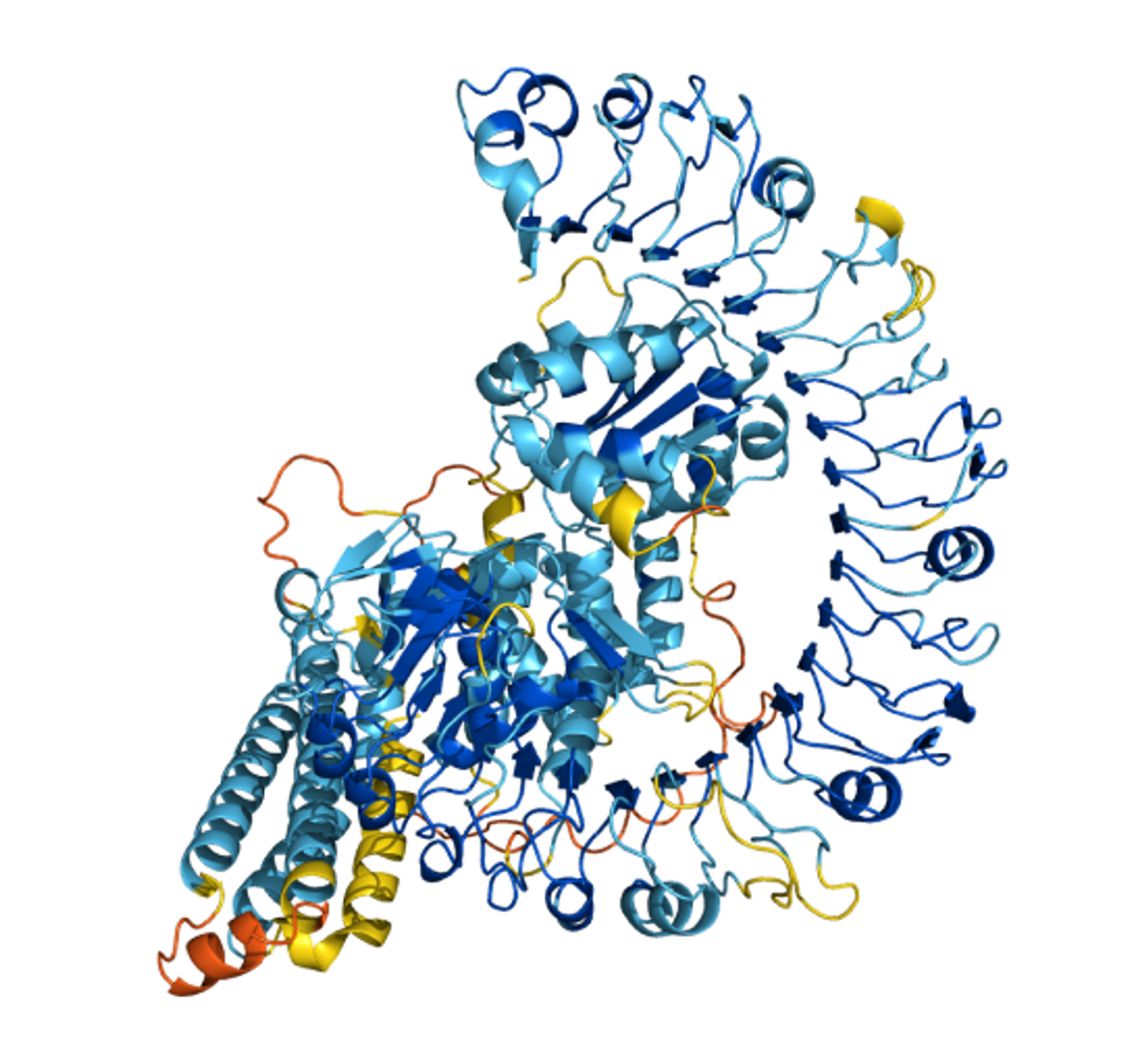
AlphaFold - deepmind.com/research/case-…, alphafold.ebi.ac.uk
Просто невозможно пройти мимо. Нейросеть для предсказания фолдинга белков.
О чем речь - в наших клетках организма (почти) все функции выполняют сложные наномашины - белкИ. Но мы не знаем, как многие из них выглядят, а те что знаем - знаем плохо. Хотя в теории, последовательность аминокислот (букв) белка почти полностью определяет его 3D-структуру.
Алгоритмы предсказания структуры по последовательности работают только для простых белков. Прогресс измеряет бенчмарк CASP, который регулярно берёт новейшие, не опубликованные, экспериментально полученные структуры, и оценивает алгоритмы. AplhaFold сделал хороший скачок в AUC.
AlphaFold, как мне кажется, немного перехайплен. Но в целом, область предсказания структуры белков и других биомолекул (и близкая к ней "молекулярная динамика", предсказывающая движение этих молекул) - это несомненно крутая и очень сложная область биоинформатики, за ней будущее.
Посмотрите на эту красоту!
Тред (Дима Борисевич)
@dsunderhood Можно ли ездить пьяным на велосипеде?
По закону не знаю, но все ездят! twitter.com/gopherizer/sta…
Полигенные скоры (polygenic risk scores)
Тема моего PhD. Хорошее введение на английском - тут: genome.gov/Health/Genomic…
Метод, который должен был появиться 10 лет назад, наконец-то появился, и теперь позволяет нам лучше понимать генетику. Много текста.

О чем речь - наши тела "запрограммированы" в последовательности нашего генома, в молекулах ДНК. ДНК папы из сперматозоида попадает в яйцеклетку, смешивается с ДНК мамы, и из этой клетке, как по программе, вырастаем мы (конечно, всё сложнее, но я опущу историю про эпигенетику).
Соответственно, последовательность генома определяет нашу "судьбу" в плане того, вырастем ли мы голубоглазыми или кариеглазыми, худыми или полными, высокими или низкими, агрессивными или спокойными и пр. На практике, окружающая среда и воспитание играет огромное значение.
НО! Генетика даёт ощутимый вклад. Например, около 30% вариации индекса массы тела (ИМТ) между людьми объясняется генетикой (R2 = 30%). При этом геном в течение жизни не меняется (это тоже упрощение), и его можно прочитать хоть у плода в утробе матери.
А многие болезни легче предотвратить, чем лечить. Соответственно, хорошо было бы знать для каждого человека его генетическую предрасположенность к разным болезням заранее, до того, как они наступят.
Идея - берем много человек, читаем их геномы, находим те места, где последовательности отличаются, и смотрим, где эти отличия скоррелированы с болезнями. Тогда, т.к. геном не меняется от болезни, мы знаем, что это отличие в геноме и вызывает болезнь, даже если не знаем механизма.
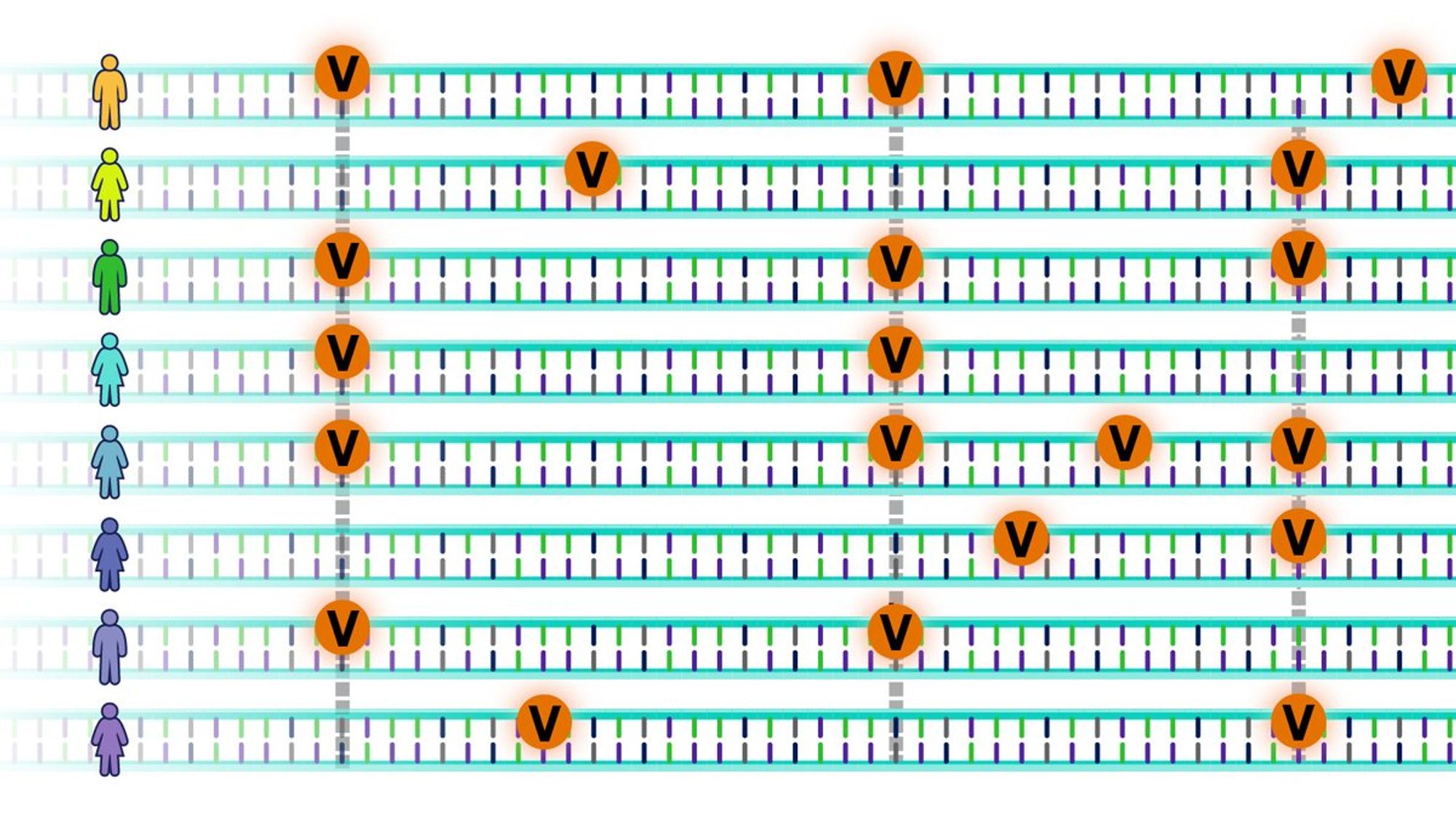
Такое исследование называется GWAS, на выходе оно даёт список мест в геноме, которые связаны с увеличением риска, и количественную оценку ("разница между носителями буквы А и буквы Т в позиции rs123456 в среднем 0.5 кг/м2").
Проблема в том, что тестируются миллионы позиций. Соответственно, если мы хотим определить конкретные важные места генома, только статистически-значимые позиции, нужно сделать запредельную поправку на множественное тестирование.
Но можно вместо того, чтобы искать конкретные позиции, просто попробовать построить как можно лучший скор, предсказывающий заболевание. Применим обычный для DS подход "training, testing, cross-validation". Тогда, можно будет из GWAS извлечь больше информации.
Скор, который берет на вход много сайтов в геноме и предсказывает предрасположенность к болезни или какой-то другой фенотип и называется полигенным. Работает хорошо - например, для ИМТ "только значимые позиции" объясняли 6% вариации, а полигенный скор - до 15% (из 30% возможных).
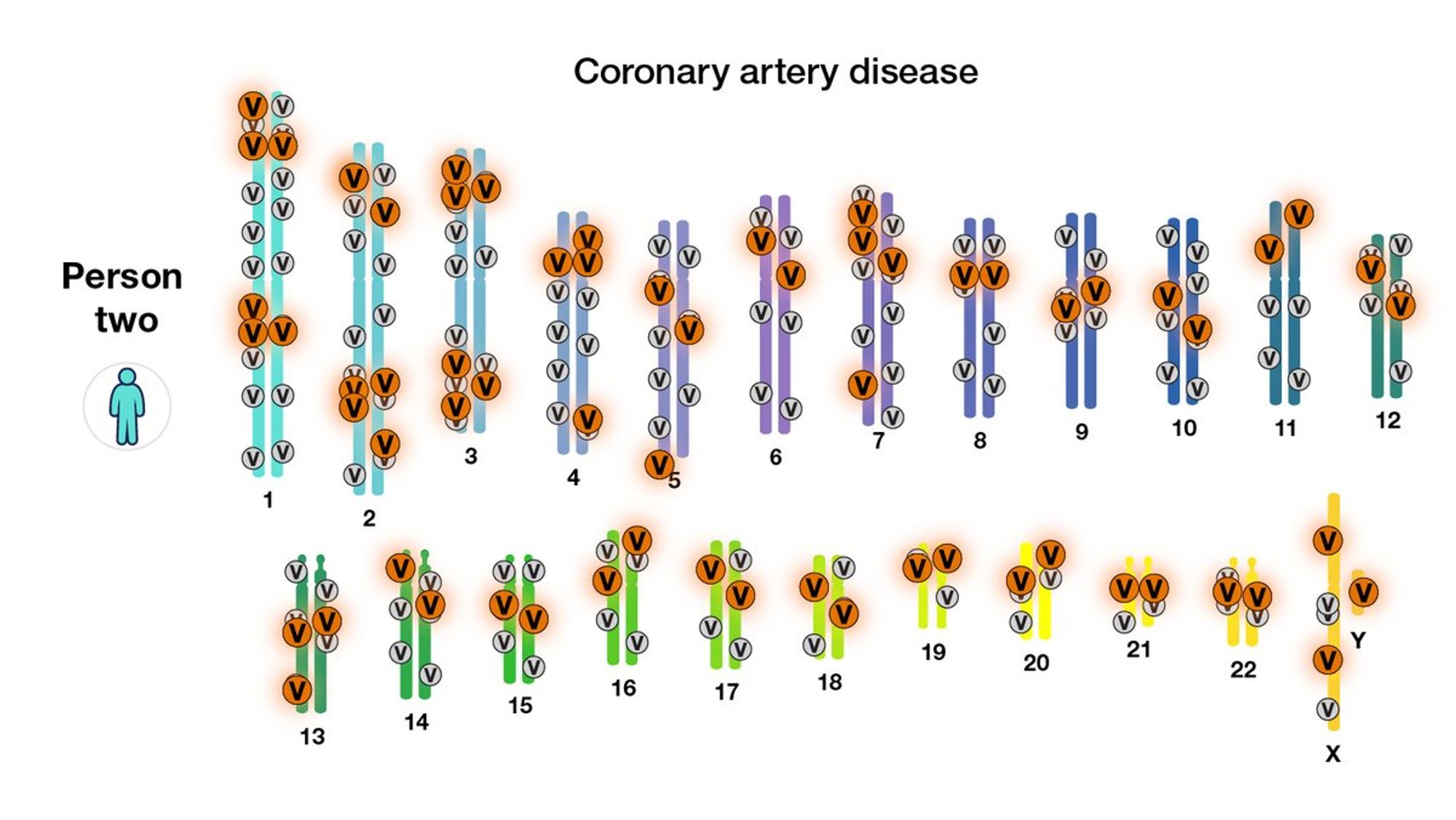
Текущие полигенные скоры далеки от идеала: они обычно просто учитывают отдельные позиции, но не их взаимодействия; и они не используют уже существующую обильную биологическую информацию об этих позициях. Поэтому у DS в этой области ещё огромный очевидный потенциал.
P.S. Великий фильм GATTACA, показывающий, что может произойти, если такой скоринг зайдёт слишком далеко.

Тред (Дима Борисевич)
Суббота
@dsunderhood Считаю, что очень круто, что в некоторых областях авторов указывают в алфавитном порядке.
Поддерживаю! twitter.com/garkavem/statu…
@dsunderhood Как тебе новость про Altos Labs как человеку от биологии. Взлетит не взлетит? И про пользу для индустрии?
Речь про "стартап" (огромный), который будет пытаться обратить старение вспять. Идея healthy aging в целом очень популярна, все хотят быть здоровыми и энергичными до 90 лет. К тому же, бОльшая часть богатства на западе - в руках людей возраста 50+, так что деньги всегда будут. twitter.com/RizhiyInArmy/s…
Возможно ли именно факторами Яманаки обратить старение? Я считаю, что нет, есть более интересные варианты. Но если бы я точно знал, что сработает, я бы сейчас сидел свой стартап пилил. Никто не знает, что сработает.
И как раз поэтому я думаю, что для индустрии это хорошо. Надо пробовать больше безумных идей, тогда какая-то из них и полетит. К тому же, такие инвестиции и PR могут подстегнуть других VC инвестировать в биотех, что тоже здорово. 👍
@dsunderhood Интересно, хоть я уже в Швецию релоцируюсь. Заметила, что большинство вакансий DS в Дании - именно связанные с биоинформатикой, очень много академии. Действительно ли есть такое отличие от остальных нордиков? Как в индустрии в Дании поживают DS?
В Дании расположен Novo Nordisk - огромная фарма, и Carlsberg - гигантский биотех (дрожжи сами не вырастут). Поэтому тут и правда есть немало позиций биоинформатиков в компаниях. + Novo Fonden инвестирует бесконечное количество денег в академию в Nordics (наверняка много в Дании) twitter.com/MarshmallowsTw…
Но я бы не сказал, что здесь только биоинформатика из DS. Просто датские компании очень плохо рекламируют свои позиции, и часто закрывают их через знакомых. "Чтобы работать в Дании, нужно уже работать в Дании"
@dsunderhood вы еще про конкуренцию в академии скажите. попасть на tenure после пары постдоков да в той же стране достаточно сложно, насколько я знаю
Все верно, из phd до tenure доходит 3-5%. И этот путь занимает лет 10 и больше. И переезд в другую страну - это не возможность, а обязанность, если вы хотите крутую карьеру в биологии. twitter.com/konhis/status/…
🤣 "The co-first authorship order was determined via the best of three rounds in Super Smash Bros." frontiersin.org/articles/10.33… pic.twitter.com/5iVuJ8lkNF
На тему порядка авторов в статье, лучший способ определить, я считаю, такой: twitter.com/KatsuFunai/sta…
Продолжим примеры биоинформатики
3. Дашборды по ковиду
В 2020, в UK потеряли 16000 кейсов ковида, потому что вставляли столбцы в Excel-таблицу, в какой-то момент они закончились, и никто этого не замечал несколько дней. Оказывается, что собирать и показывать данные сложно.
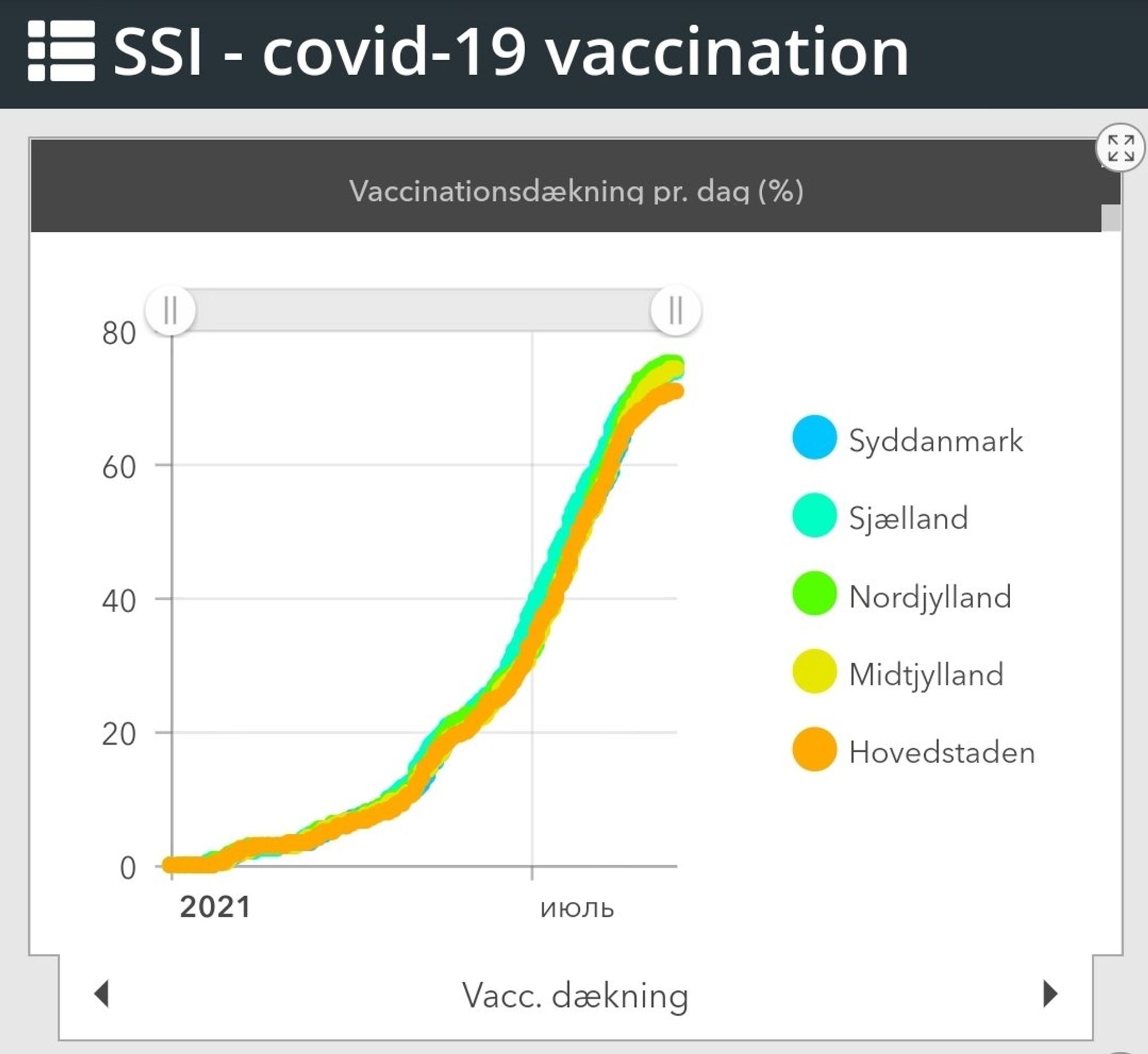
В Дании, центр, ответственный за мониторинг вакцинации сделал публичный дашборд, который показывает прогресс в вакцинации - experience.arcgis.com/experience/1c7…
Это довольно простая история, но очень важная в плане прозрачности. В каком-то смысле это тоже биоинформатика, более того,
я думаю что этот дашборд именно биоинформатики центра SSI и делали.
Полная вычислительная модель живого организма
cell.com/fulltext/S0092…
Целая модель 28 клеточных процессов одного простейшего организма.
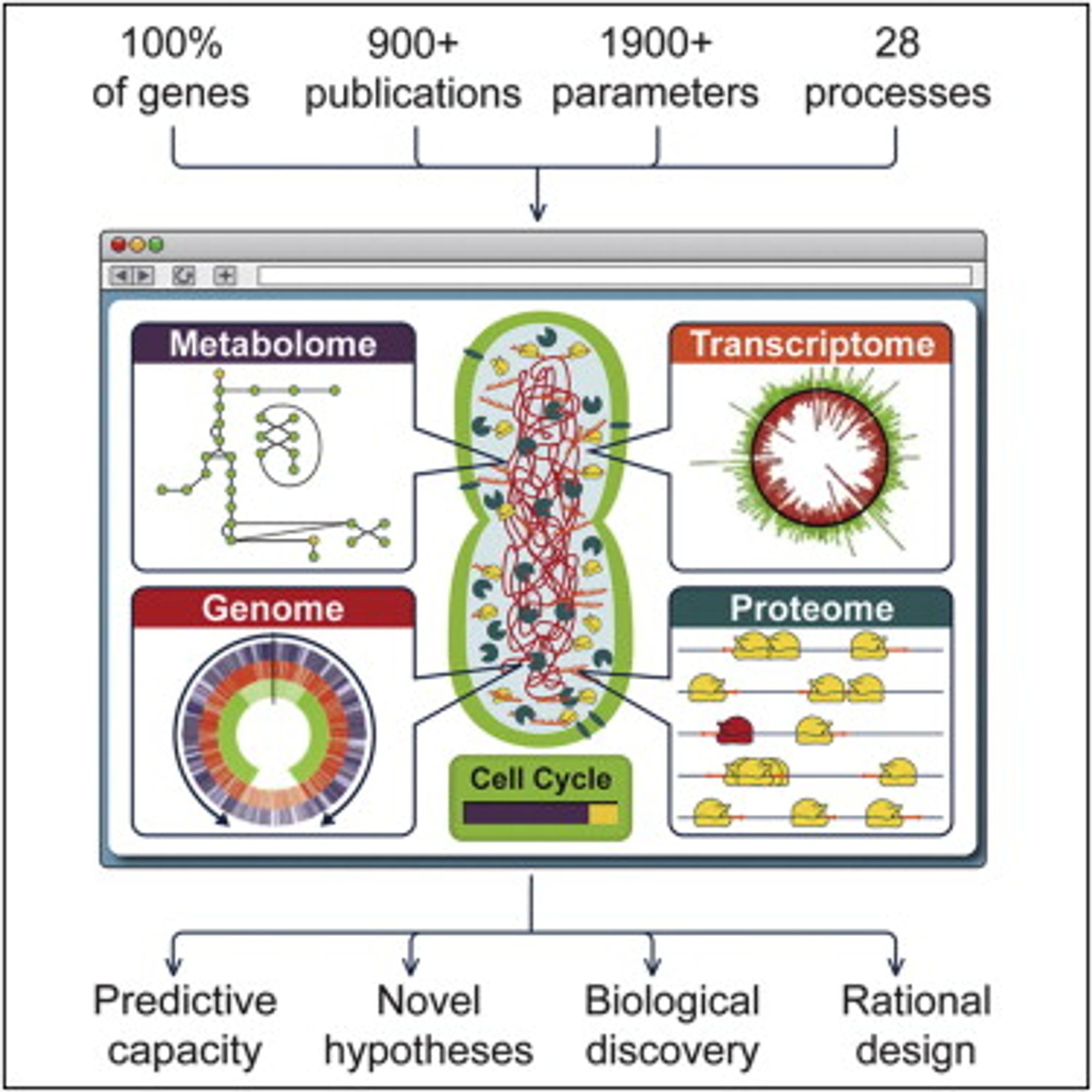
Очень хочется, чтобы живые организмы, или хотя бы какие-то процессы в них, можно было симулировать на компьютере. Эту область называют "системной биологией". Обычно симулируют дрожжи - они простые, и важны для биотех бизнеса.
Можно также симулировать химическую кинетику (т.е. как протекают хим. реакции) отдельных процессов в клетках человека, очень ограничено. А как насчёт симуляции целого, пусть и простого организма? Существуют попытки симулировать всю хим. кинетику дрожжей S.Cerevisiae.
Но мне приглянулась статья про бактерию микоплазму. В ней авторы собрали 900+ публикаций, описывающих отдельные параметры отдельных процессов, и сделали цельную модель, симулирующую кучу процессов разом.
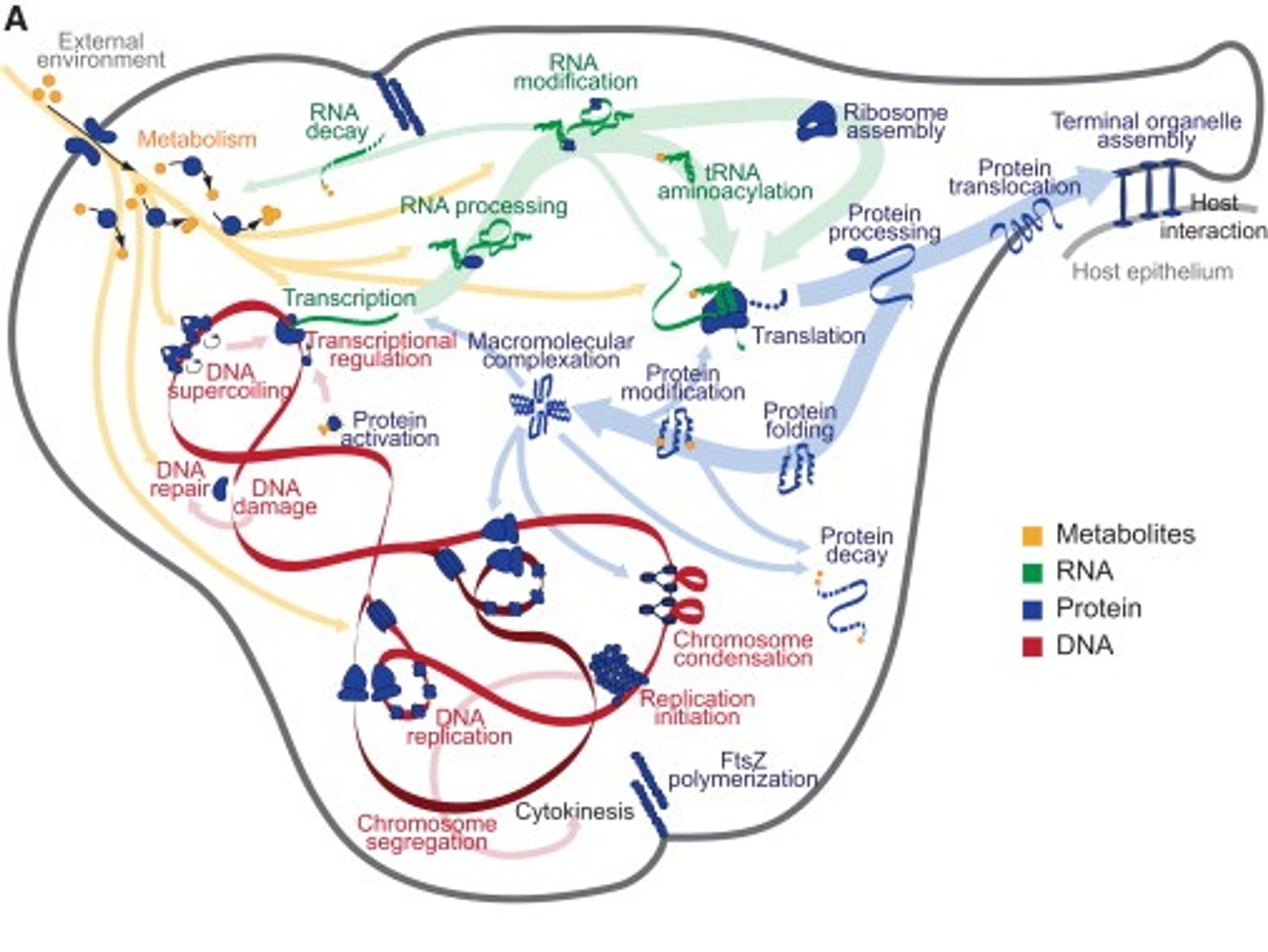
Причем, отдельные процессы могут описываться совершенно разными моделями - дифференциальными уравнениями, вероятностными моделями, или другими узкоспециальными. Все их авторы смогли собрать вместе, что по-моему абсолютно адский труд и невероятное достижение.
Авторы утверждают, что их модель буквально предсказывает поведение процессов в клетке микоплазмы, которое воспроизводится экспериментально. То есть буквально, удаётся симулировать бактерию исходя из "первых принципов", что почти никогда не происходит в биологии.
С одной стороны - это всего одна, простейшая, бактериальная клетка, и это несерьезно. С другой - это огромный результат. Я очень надеюсь дожить до того момента, когда мы такую же модель соберём для всего человека.
Тред (Дима Борисевич)
Завершая про биологию, если вы хотите продолжать читать крутые треды про генетику и другую биологию, то я лично вам рекомендую твиттер @OlgaVPettersson 👍 смотрите в закрепе уже существующие отличные треды.
@dsunderhood Какая самая weird офисная традиция в Дании?
Давайте повеселимся. Это будут не совсем традиции, потому что у нас их почти не было, но какие-то истории про наш центр. И не все будут weird - многие вполне себе обычные, но милые. twitter.com/alexk7384/stat…
На вечеринках часто приносят домашний шнапс и пытаются им напоить всех вокруг. Как правило, этот шнапс ужасен, или, например, с красным перцем ;-)
Много где есть Friday breakfast, Friday cake, или Friday beer. Ничего weird, просто возможность социализироваться с коллегами. У нас был завтрак (записывались в список и по очереди приносили хлеб + что на хлеб намазать/положить) + пиво.

Многие ездят на работу на велосипеде по 20км и принимают душ в офисе, и большие начальники тоже. Также знаю одного групп-лидера, который отвозит детей в садик, приезжает в 7:30 на работу, и бегает полчаса вокруг здания.
3.1. А ещё один поставил высокий стол, под него беговую дорожку без перил, и ходит на месте весь день, пока работает 🚶
На рождественской вечеринке большая частота половых связей между коллегами, и замужество никого не останавливает. На это все смотрят как на само собой разумеющееся.
Мы всем центром бегаем DHL Run. Это ежегодная эстафета 5х5км, которая идет 5 дней, т.к. много желающих, и куда приходит весь Копенгаген, по-моему. Университет весь бежит в один день, команд 400 разом. Это тоже история скорее про общение, чем про победу.

Тред (Дима Борисевич)
Воскресенье
Давайте, пока у нас время есть, я ещё немножко наброшу про будущее DS в биоинформатике.
Коротко: я думаю, что потенциал огромный, будет прорыв в текущих методах + за биоинформатикой глобальное будущее, но это будет не то, что мы сегодня понимаем под биоинформатикой.
Все хотят жить долго и хорошо. И современные медицинские технологии и исследования в биологии невозможны без DS. Поэтому мне кажется, что со временем биоинфо будет становиться всё важнее и больше.
Современная биоинформатика - это скорее история про обслуживание биологии. Проблема в том, как я ворчал в четверг, что заказчик-биолог не знает, какие крутые штуки можно делать и нужно хотеть. А на алгоритмах, пусть и крутых, денег не сделаешь (и карьеру тоже с трудом).
Полигенные скоры (polygenic risk scores) Тема моего PhD. Хорошее введение на английском - тут: genome.gov/Health/Genomic… Метод, который должен был появиться 10 лет назад, наконец-то появился, и теперь позволяет нам лучше понимать генетику. Много текста. pic.twitter.com/b66D27acoO
В итоге получается история, как с полигенными скорами, про которые я говорил вчера - twitter.com/dsunderhood/st…
Метод очевиден любому DS, мог появиться на железе десятилетней давности, но появился только 3 года назад, и до сих пор используется редко.
Мой вывод - биоинформатика должна быть DS-first, чтобы выжить. На мой взгляд, всё идёт к тому, что будет появляться DS-first research, в ближайшем будущем. Данные становятся всё более доступны в масштабе, о котором мы и мечтать не могли. Пример:
В прошлом году стали доступны три крупных биобанка - UK ukbiobank.ac.uk , финский finngen.fi/en , и японский biobankjp.org/en/index.html
Теперь любой учёный может подать заявку, и за месяц-два получить доступ к подробным биологическим данным сотен тысяч человек.
И коммерческая компания тоже, при условии, что результатами поделится открыто.
в некоторых областях науки также есть крутые ресурсы, агрегирующие вообще все данные. Например, ncbi.nlm.nih.gov/geo/ собрал 4000+ датасетов по транскриптомике (к которой у меня свои претензии как к науке, правда), ebi.ac.uk/gwas/ - ~16000 GWAS исследований.
Пример: в генетике человека до сих пор публикуют анализы, сделанные на 2К-3К человек. Просто потому, что данные, особенно людей, обычно спрятаны внутри групп, и почти недоступны снаружи. А в UK BioBank есть данные 400К человек, и доступ к ним может получить любой DS.
Мне очевидно два десятка разных улучшений, которые можно попробовать сделать в плане DS в генетике. Что-то я успел попробовать в своей диссертации, но большинство - нет. Очевидно, что если больше дата саентистов, которые ещё и круче меня, попадут в эту область - будет прорыв.
Поэтому в короткой перспективе я думаю, что DS-first биоинформатика начнёт добиваться крутых успехов, и вытеснит biology-first биоинформатику, как ненужную.
В долгой же перспективе, мне кажется, что современную биологию невозможно переделать. Грубо говоря, не тур.агенства 20 века изобрели AirBnB. И биоинформатика будущего будет не совсем тем, что мы называем биоинформатикой сегодня.
Мне хочется верить, что по мере того, как tech-first подход будет приходить в биоинформатику, мы будем создавать новые направления, о которых биологи сегодня даже не думают. И будут появляться AirBnB от биоинформатики. Анализ данных секвенирования - уже такой пример.
Пример пре-процессинга и анализа данных визуализировать сложнее, но именно на эти позиции нанимают большинство биоинформатиков. Вот, например, очень хороший и стабильный, и в целом считающийся простым, пайплайн анализа данных секвенирования: pic.twitter.com/TD2UZ2UZJc
Вот этот пайплайн анализа данных секвенирования - twitter.com/dsunderhood/st… - результат долгой работы, где tech и DS определяли развитие. И сегодня секвенирование и его анализ - гораздо более "продуктовые" области, чем многие другие, хотя ...
20 лет назад казалось, что секвенирование не станет никогда коммерчески доступным. Но, оказалось, что если быть tech-first, то можно сделать крутую технологию, которая создаёт целые области науки: диагностику редких заболеваний, транскриптомику, single-cell транскриптомику и т.п.
Поэтому я верю, что за биоинформатикой будущее, но это будет не то, что мы сегодня понимаем под биоинфо. А у сегодняшнего биоинфо тоже есть огромный потенциал развития, но это тупиковая ветвь эволюции, как мне кажется.
Если у вас есть мнение про будущее биоинформатики - пишите тут, подебатируем =)
Тред (Дима Борисевич)
@dsunderhood Не говоря уже про то, что без интерпретируемости результатов любой анализ в биологии (и тем более в медицине) можно выкинуть в мусорку. Годится только чтобы всякие 23andme-подобные стартапы могли добывать деньги из доверчивых клиентов, слишком верящих в мощь современной генетики.
Я подробно ответ и в треде, но вкратце - это предвзятое мнение, и я не согласен. Ген.тесты потому и стали компаниями, что в отличии от толпы других, академических методов работают. Работает генеалогия, работают полигенные скоры. А без интерпретации живет полмедицинып twitter.com/VorontsovIE/st…
Пример - при ковиде теряется обоняние. Механизм до сих пор никто не знает, но как признак для предсказания ковида работает отлично. Полигенные скоры - такой же признак.
Более того, если 23andme и иже с ними - шарлатаны, спускающие деньги,то почему те академики, которые делают GWAS исследования и строят те же скоры, до сих пор работают в академии? Выгнать их все, шарлатанов. Или "это другое"?;-)
Вроде бы я пробежал по всем темам, хотя и не по порядку =) я сделаю мета-тред, а вы пока задавайте вопросы под этим твитом, что ещё рассказать.
P.S. В комментах обсуждают компании ген.тестирования, шарлатаны ли они. Если вопросов не будет - я выскажусь на эту тему ;-)⚠️
Hardware Удивительно, но большинство анализов в биоинформатике не используют облако! Как правило анализ идёт либо на макбуке биоинформатика, либо на изолированном от мира кластере. 1/
Мета-тред недели про биоинформатику:
1/n Введение
- биоинформатика - что это - twitter.com/dsunderhood/st…, twitter.com/dsunderhood/st…
- тех.стэк в деталях - twitter.com/dsunderhood/st…, twitter.com/dsunderhood/st…, twitter.com/dsunderhood/st…,
twitter.com/dsunderhood/st…
Полная вычислительная модель живого организма cell.com/fulltext/S0092… Целая модель 28 клеточных процессов одного простейшего организма. pic.twitter.com/yuDJKyzyKB
2/n Крутая биоинфо
- AlphaFold - twitter.com/dsunderhood/st…
- полигенные скоры - twitter.com/dsunderhood/st…
- дашборды - twitter.com/dsunderhood/st…
- модель всея микоплазмы - twitter.com/dsunderhood/st…
С точки зрения одного человека, такая система в академии может быть и хорошо - этот человек будет много знать и уметь, и, как ему кажется, дорого стоить (имо, нет). Но с точки зрения системы, отсутствие разделения труда - это катастрофа.
3/n Работа
- рынок труда - twitter.com/dsunderhood/st…
- зп - twitter.com/dsunderhood/st…
- ворчу о проблемах академической биоинфо - twitter.com/dsunderhood/st…, twitter.com/dsunderhood/st…
В Дании расположен Novo Nordisk - огромная фарма, и Carlsberg - гигантский биотех (дрожжи сами не вырастут). Поэтому тут и правда есть немало позиций биоинформатиков в компаниях. + Novo Fonden инвестирует бесконечное количество денег в академию в Nordics (наверняка много в Дании) twitter.com/MarshmallowsTw…
4/n Разное
- моё скромное мнение о большом будущем биоинфо - twitter.com/dsunderhood/st…
- чуть-чуть про Данию -
twitter.com/dsunderhood/st…, twitter.com/dsunderhood/st…, twitter.com/dsunderhood/st…
Тред (Дима Борисевич)
Понедельник
Напоследок, выскажусь про генетические тесты, основанные на генетических/полигенных скорах. В комментариях ругают компании, которые продают генетические тесты, мол это шарлатанство и фуфло. Я считаю, что это гениальный продукт и абсолютно научная технология.
Я попробую поспорить с тремя аргументами, которые увидел: скоры нельзя интерпретировать, поэтому от них нет пользы; если и есть, то они ничего не предсказывают с уверенностью; если и предсказывают, то очень слабо, а компании приукрашивают и делают слишком смелые заявления.
С аргументами 1 и 2 я поспорю, а с 3 - внезапно, соглашусь. Набрасывайте, если я что-то пропустил.
Дисклеймер: я работал и в академии в этой области, и в частной компании, которая такие тесты делает и продаёт.
Я поспорю на одной статье, недавней нашумевшей pubmed.ncbi.nlm.nih.gov/31002795/, где сделали полигенный скор ИМТ (индекса массы тела) из 2.1 миллиона вариантов (фичей). Просто потому, что, как мне кажется, она позволяет опровергнуть / продемонстрировать все три аргумента.
Это публикация в Cell - топовом журнале, крутая статья, учёные из Гарварда и Бостона. Будут потом включать её в своё CV и получать миллионы бюджетных $ на исследования. Эту статью peer reviewed другие, более опытные чем я, академики, и решили, что это крутая и корректная статья.
"Скоры не интерпретируемы, значит бесполезны"
Авторы не интепретируют 2.1млн фичей. Они просто используют скор, потому что он работает. Вообще, вся статья просто показывает, что скор предсказывает ИМТ, и даже в молодом возрасте (что не обязательно), и от него есть польза.
Это философское решение, кмк: должны мы знать уметь интерпретировать находки; или достаточно рабочего скора. Я сторонник второго взгляда - если при полезный пропадает обоняние, значит это хороший скор ковида, даже если мы не можем это объяснить.
И если по 2.1 млн генетических фичей можно предсказать ИМТ с некоторой точностью, то для меня это полезный скор ИМТ. Поэтому с п. 1 я не согласен - скор, который просто работает, даже если объяснить мы его пока не можем, приносит пользу.
"Скоры примерные, ничего точно не предсказывают"
Та же статья, цитата из Summary:
"Среди взрослых мы обнаружили 25-кратное увеличение риска тяжелого ожирения, среди разных децилей полигенного скора." Чёткое, проверяемое утверждение. Довольно сильное, на мой взгляд.
Как мы видим, академики делают сильные утверждения о перформансе скора. Поэтому с п.2 я тоже не согласен - скоры предсказывают сильные эффекты, пусть и не идеально.
"Компании делают слишком громкие заявление, а учёные аккуратны"
Вот тут я внезапно соглашусь, что компании делают громкие утверждения. Ровно так же, как и академия. И если мы считаем, что это нормально для академии, то, как мне кажется и компании могут делать то же самое.
Пример из п.2 - статья публикует скор, который предсказывает увеличение риска в 25 раз! Мне кажется, раз это опубликовано, то и компания может заявить, что предсказывает такой риск в своих PR материалах.
Ещё пример - заголовок в результатах:
"Скор идентифицирует [выделение моё] 1.6% людей в популяции, с увеличением ИМТ схожим [по силе] с моногенным ожирением". "Идентифицирует" - это очень сильное слово.
Оно говорит, что мы можем со 100% точностью выявить людей с повышенным ИМТ - не с риском, а с повышенным ИМТ(!) - и это смелое заявление. И если авторы так пишут, то компания может ~1.6% клиентов написать, что у них высокий риск ожирения. Это будет даже более слабое утверждение
Но когда академик забирается на табуретку морального превосходства и говорит, что бизнес - шарлатаны, а он нет, то людям, далёким от науки, сложно поспорить, потому что они не читают научные статьи. А я читаю. И поэтому я вижу, что академики точно так же делают громкие заявления.
И с п.3 я согласен - но я считаю, что это нормально. Всегда кто-то скажет, что какое-то конкретное заявление слишком громкое, а кто-то - что давно очевидное. Кмк, рано или поздно кто-то должен сделать "смелое" заявление, потому что так работает data-driven принятие решений.
И это я говорю только про полигенные скоры, мой любимый топик. Я не затрагиваю другие генетические тесты - генеалогия, происхождение гаплогрупп, родство, моногенная диагностика. Они ещё более точные, и позволяют делать ещё более громкие заявления.
Моё резюме - генетические тесты - нормальная технология. Рабочая и научная. К тому же это гениальный продукт с точки зрения продакта, потому что он стабилен, DS для него хорошо масштабируется, и качество анализов выигрывает с ростом компании.
P.S. Любая статья в генетике - такая же. Это просто пример, который я недавно читал.
P.P.S. Я отстаиваю идею в целом, что ген.тесты, как продукт - это научно. Это не означает, что какая-то конкретная компания - не мошенники. Как и что все академики - святые люди.
"если при ковиде", твиттер сделай редактирование твитов!
Тред (Дима Борисевич)
Я так понимаю, что завтра я аккаунт передаю, @tiulpin ?
На всякий случай всем пока, был рад писать про биоинформатику, может кто-то из вас заинтересуется ей. Добавляйтесь в твиттер и инстаграм. Если аккаунт не отберут, то я что-нибудь ещё напишу завтра :-)















