
Полигенные скоры (polygenic risk scores)
Тема моего PhD. Хорошее введение на английском - тут: genome.gov/Health/Genomic…
Метод, который должен был появиться 10 лет назад, наконец-то появился, и теперь позволяет нам лучше понимать генетику. Много текста.

О чем речь - наши тела "запрограммированы" в последовательности нашего генома, в молекулах ДНК. ДНК папы из сперматозоида попадает в яйцеклетку, смешивается с ДНК мамы, и из этой клетке, как по программе, вырастаем мы (конечно, всё сложнее, но я опущу историю про эпигенетику).
Соответственно, последовательность генома определяет нашу "судьбу" в плане того, вырастем ли мы голубоглазыми или кариеглазыми, худыми или полными, высокими или низкими, агрессивными или спокойными и пр. На практике, окружающая среда и воспитание играет огромное значение.
НО! Генетика даёт ощутимый вклад. Например, около 30% вариации индекса массы тела (ИМТ) между людьми объясняется генетикой (R2 = 30%). При этом геном в течение жизни не меняется (это тоже упрощение), и его можно прочитать хоть у плода в утробе матери.
А многие болезни легче предотвратить, чем лечить. Соответственно, хорошо было бы знать для каждого человека его генетическую предрасположенность к разным болезням заранее, до того, как они наступят.
Идея - берем много человек, читаем их геномы, находим те места, где последовательности отличаются, и смотрим, где эти отличия скоррелированы с болезнями. Тогда, т.к. геном не меняется от болезни, мы знаем, что это отличие в геноме и вызывает болезнь, даже если не знаем механизма.
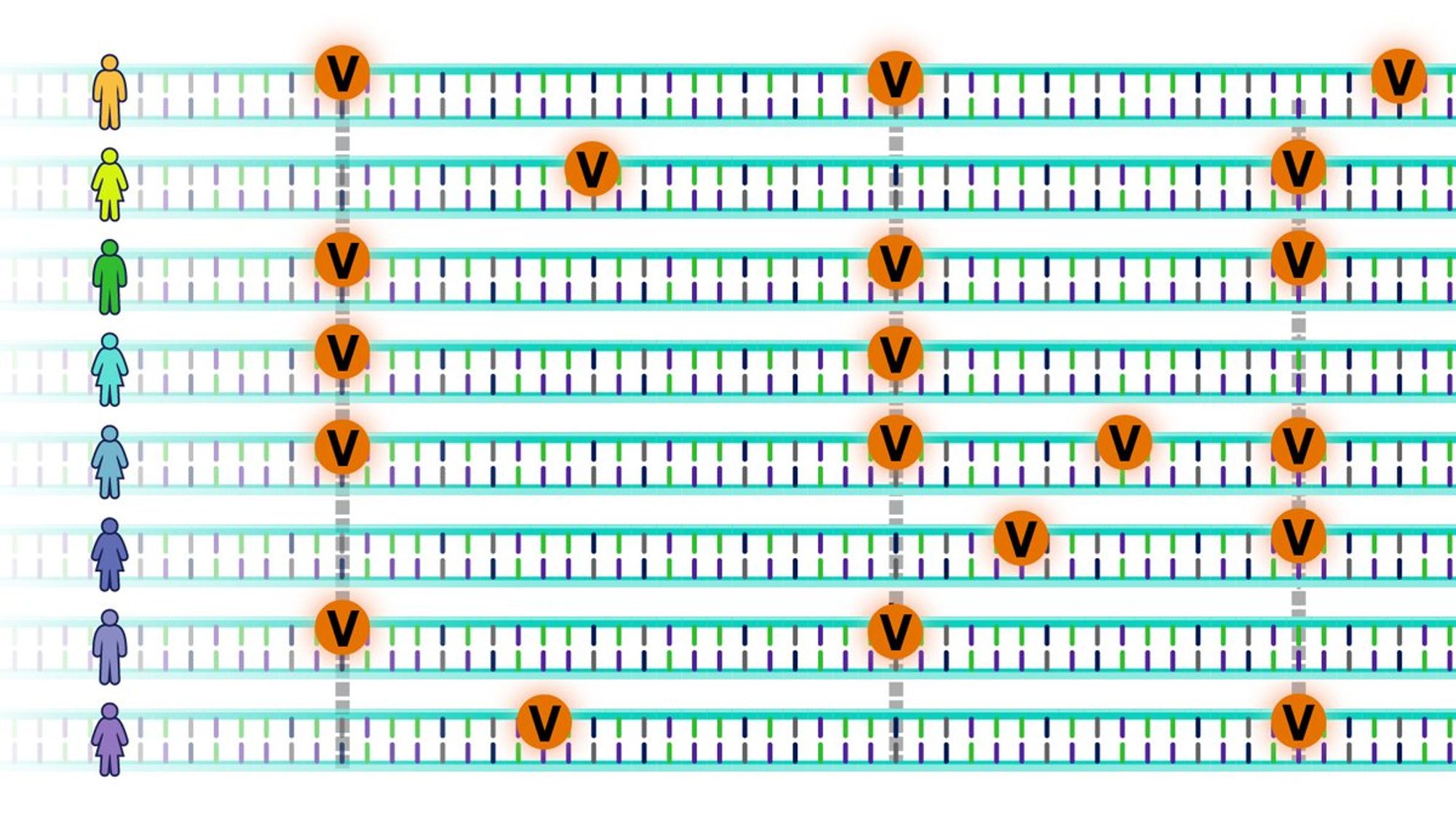
Такое исследование называется GWAS, на выходе оно даёт список мест в геноме, которые связаны с увеличением риска, и количественную оценку ("разница между носителями буквы А и буквы Т в позиции rs123456 в среднем 0.5 кг/м2").
Проблема в том, что тестируются миллионы позиций. Соответственно, если мы хотим определить конкретные важные места генома, только статистически-значимые позиции, нужно сделать запредельную поправку на множественное тестирование.
Но можно вместо того, чтобы искать конкретные позиции, просто попробовать построить как можно лучший скор, предсказывающий заболевание. Применим обычный для DS подход "training, testing, cross-validation". Тогда, можно будет из GWAS извлечь больше информации.
Скор, который берет на вход много сайтов в геноме и предсказывает предрасположенность к болезни или какой-то другой фенотип и называется полигенным. Работает хорошо - например, для ИМТ "только значимые позиции" объясняли 6% вариации, а полигенный скор - до 15% (из 30% возможных).
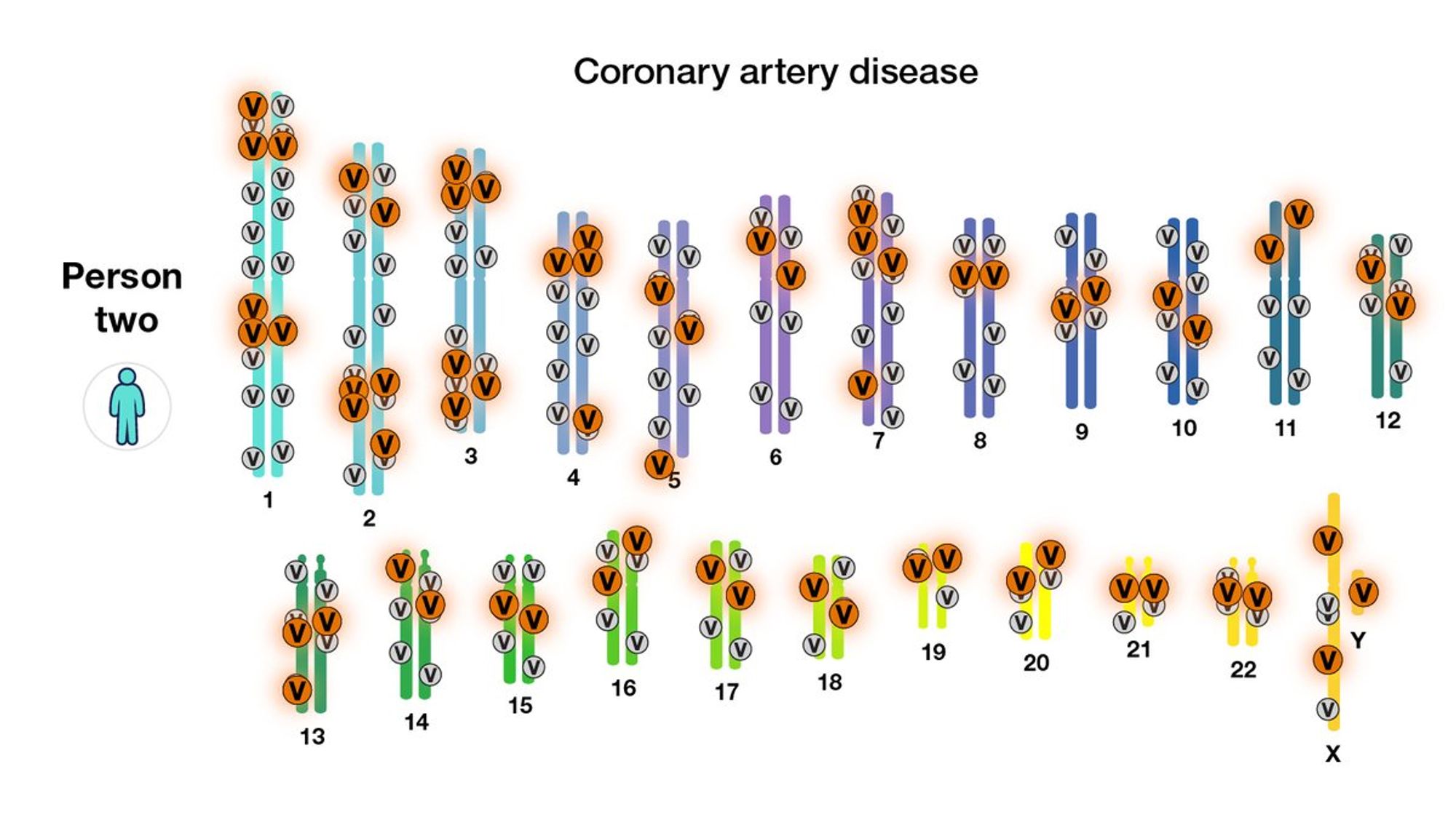
Текущие полигенные скоры далеки от идеала: они обычно просто учитывают отдельные позиции, но не их взаимодействия; и они не используют уже существующую обильную биологическую информацию об этих позициях. Поэтому у DS в этой области ещё огромный очевидный потенциал.
P.S. Великий фильм GATTACA, показывающий, что может произойти, если такой скоринг зайдёт слишком далеко.

 Дима Борисевич
Дима Борисевич