

Архив недели @polyaniza
Понедельник
Всем привет!
На этой неделе коллективный твиттер буду вести я, Дарья Пронина (@polyaniza), Data Scientist в Lamoda R&D.
Скоро будет 5 лет как я занимаюсь анализом данных, поэтому, надеюсь, контента на недельку найдется😅
Поговорим про путь в DS, сервера с нейросетками в лесу, DS в Lamoda, "прикольные" собеседования, боевое крещение на публичных выступлениях и переживания на счёт карьеры
Начнем про путь в data science. Интересно, как у вас это происходило, потому что у меня, как мне кажется, все пошло немного через жопу))
Я училась на экономико-математическом факультете в РЭУ им. Плеханова и тогда я думала, что матстат и эконометрика нужны, чтобы предсказывать брак на производстве или работать в росстате.
Мне в учебе нравилась математическая часть и намного меньше - экономическая. Поэтому после выпуска я вышла в полной фрустрации: куда с таким идти было непонятно
Этим же летом, наша прекрасная преподавательница матанализа Ира Маслякова позвала меня даже не участвовать, а сразу помогать организовывать (!) с нуля (!!!) мастерскую по ds на летней школе. У меня даже сохранилась наша старая страничка! letnyayashkola.org/datascience/
Летняя школа - это такое абсурдное место, где все собираются в палатках в Дубне и организуют тематические обучающие программы, при этом туда приезжают самые крутые деятели областей и популяризаторы науки (об этом экспириенсе расскажу попозже))
И значит я сижу на первой встрече оргов в 2016 году, и там все обсуждают, что лучше взять для курса: R или python, будем ли давать что-то по нейросеткам или обойдемся классическими методами ML, будет ли курс отдельно по pandas....
и я в полных шоках ЧТО ЭТО ВСЕ ТАКОЕ
К слову, мы в универе проходили регрессию, мммм ну еще кластеризацию (иерархическую и Kmeans)... и делали мы все это в экселе или древних статпакетах (ну мои бро по экономическим или психологическим направлениям наверно вспомнят такие название как eviews или stata😅)
В общем за 2 недели проведения нашей мастерской для меня открылся новый мир современного анализа данных и решаемых с помощью него задач. А мои знания, оказывается, были частью всего этого, только русифицированные и устаревшие лет на 10 минимум.
После такого прозрения я решила забить на магистратуру и изучать сей дивный новый мир. Поступила на бесплатные курсы в МГУ (прошла экзамен с помощью моих универских знаний матстата, кстати)
За несколько месяцев этого курса и кегглерства освоила python, добрала современных знаний в ML и в ноябре уже устроилась на первую работу аналитиком данных 🕺
Тред (Дарья Пронина)
Кстати пятюня всем из нетехнических вузов в ds! Сколько нас тут?)
Мое образование:
🤔
65.3% Техническое🤔
17.0% Экономическое🤔
1.9% Психологическое🤔
15.8% Ваще другоеКстати пятюня всем из нетехнических вузов в ds! Сколько нас тут?) Мое образование:
Штош. С большим отрывом лидирует техническое образование, что и видно по ожиданиям в вакансиях)
Но я все-таки не особо жалею, что училась на экономико-математическом, потому что это дало свои плюсы: twitter.com/dsunderhood/st…
У нас были очень сильные курсы по теорверу и матстату. Это дает хороший старт к пониманию алгоритмов мл, а еще больше - к тому, как работают А/Б-тесты.
С этими знаниями на работе мне проще не продолбаться, анализируя эффективность нового решения.
У нас была "эконометрика" - это такой курс, где вы применяете мл на экономических данных. На ней мы разбирали не очень много методов, но зато очень подробно.
Теперь я знаю часть вещей гораздо подробнее, чем рассказывают в онлайн курсах)
Знания по экономике сильно помогают в решении задач для бизнеса, да и в обычной жизни
Например, это важно при выборе правильных метрик качества и оценке их взаимного влияния на бизнес. Часто бывает, что у ds-ов в фокусе метрики качества самих моделей, а не итогового продукта
Также у нас были полезные курсы по анализу рисков и оптимизации инвестиционного портфеля, которые помогали бы мне, если бы я тогда интересовалась😅
Ну и заключительное - это знакомство с разными отраслями: энергетика, добыча ископаемых, экология, финансы. Для кругозора было полезно)
Чего не хватило, то это 1. конечно современных знаний в мл и не только. Наверно, это проблема образования в целом, но сейчас в вузах все больше курсов совместно с крупными компаниями, и современным студентам тут явно больше повезло)
Навыков программирования тоже не хватило. Ушло много времени на понимание всяких абстракций и прочего.
Понимания, как устроена работа в IT. Этого наверно нет и на современных курсов по ds, но мне бы на старте помогла информация не только про навыки, но и про то, что вокруг. Что есть некий эджайл и различные менеджеры, что есть всякие тасктрекеры и вот такое все.
Но в целом, я недавно была в Плехе и проводила небольшую лекцию про свою работу, и заметно, что студенты (и что немаловажно, студентки!) сейчас с первых курсов интересуются Data Science и IT.
Держу за них кулачки и надеюсь, им будет проще влиться в это все)
Тред (Дарья Пронина)
Вторник
Этим же летом, наша прекрасная преподавательница матанализа Ира Маслякова позвала меня даже не участвовать, а сразу помогать организовывать (!) с нуля (!!!) мастерскую по ds на летней школе. У меня даже сохранилась наша старая страничка! letnyayashkola.org/datascience/
Так вот про Летнюю школу) twitter.com/dsunderhood/st…
Напомню, что это летний проект, где на территории старого детского лагеря под Дубной на берегу Волги можно учиться всяким разным темам от доккино и философии до биологии и компьютерных наук
Фишка в том, что изначально формат ЛШ хорошо подходил для обычных образовательных мастерских (тусуешься на свежем воздухе, слушаешь лекции, учишь новые штуки, знакомишься) ...
...а еще для практических мастерских (биологи изучают местные травинки, режиссеры снимают документалки про суровую российскую действительность в соседних Кимрах, социологи проводят исследования на сотнях участниках школы)
Нам тоже хотелось тусоваться и знакомиться, только нам предстояло собрать 20 дата саентистов практически в лесу и дать им возможность вертеть свои модельки круглые сутки🤪
В итоге у нас было:
2 пакетика...
нет)
1)полулегальная антенна с высокоскоростным интернетом от соседнего института яндерных исследований
2)по 3 забитых зарядками пилота в каждой розетке со старой проводкой
3)и сервак, "взятый в аренду" из НИИ, в котором работал один из огров
К нам приезжали с лекциями разные крутые чуваки из индустрии, рассказывали про свои проекты и привозили свои идеи для ресерча)

Вот некоторые из проектов, которые у нас делали:
(может кому-то поможет придумать пет-проджект))
На Волге очень красивые закаты. Соответственно, их очень (ОЧЕНЬ) часто выкладывают в инстаграм.
Ребята писали парсер для инсты на js и классифицировали фотки на нормальные и закаты. Конечно, только ради учебы и кеков)

В этом году активно добавлялись новые разделы на федеральном портале открытых данных, поэтому мы решили использовать их в проектах) Один из студентов анализировал уровень комфортности жилья по разным показателям жкх и гео-данным.
Делали разных телеграм-ботов, тогда это как раз было еще модно) в том числе делали что-то вроде алисы, которая пытается ответить на твой вопрос, а именно ищет семантически похожий с сайта theQuestion и выдает ответ с него.

Но это, конечно же, скучно. Лучше отвечать на сообщения мемасами!)
Было еще очень много разного, защита проектов по традиции лампово проходила в 01:00)🤦♀️
Сейчас на ЛШ тоже проходят мастерские по дс, в основном каждый год берется какое-то конкретное направление: в этом, например, была мастерская по NLP.
да, все-таки ОРГОВ )))
Тред (Дарья Пронина)
Среда
Немного про работу R&D Lamoda
У нас 3 DS-команды, разделенные по стримам:
-Навигация - ранжирование+поиск,
-"Персональный помощник" - это всякая персонализация+рекомендации и немного продуктовых фичей для облегчения жизни пользователей
-Ценообразование (ну тут понятно)
По объему описания команд в целом можно догадаться, что я занимаюсь персонализацией💁♀️
Также у нас в R&D есть команда продуктовых аналитиков и 2 команды разработчиков
По задачам у нас стандартный e-com pack) делаем ML-ранжирование в каталоге, решаем NLP-задачи для поиска, персонализируем рекомендации и товарные выдачи, персонализируем все это для пользователей, решаем задачу оптимизации скидок
придумываем всякие эксперементальные штуки)
Например, сейчас делаем упор на то, чтобы по-максимуму выжать из фотографий наших товаров, поскольку в изображениях скрыто больше информации об одежде, чем в описании или атрибутах.
Например, в инфе о платье может быть указано, что у него короткий рукав, но насколько он короткий, там не будет сказано) а по фотографии можно будет определить "короткость" в числовом выражении
Ну и дальше по картинкам можно будет анализировать всякие мета-штуки вроде стилей образов и сочетаемость товаров в них) У руля по этим задачкам у нас @tez_romach 🌟
Побольше можно кстати почитать в статье Ромы в нашем хаброблоге habr.com/ru/company/lam…
Бонус дочитавшим тред! 😅
У нас сейчас активный найм на кучу позиций, в том числе есть позиция тим-лида команды персонального помощника.
Все туть tech.lamoda.ru
Тред (Дарья Пронина)
Один из моих больших проектов за последний год - это отдельный раздел с персональной подборкой товаров на сайте и в приложениях.
Выглядит это примерно так:
В решении этой задачки я заново выучила главное правило в DS "проще=лучше" или "сначала делаем baseline, потом допиливаем".
Изначально еще 2 года назад в команде всплыла идея взять все действия пользователей с товарами и на их основе сделать такую УЛЬТРА-ВЫДАЧУ товаров условно чтобы никуда больше по сайту ходить было не нужно.
А еще решили брать статистику аж за год, чтобы захватить все сезоны, да и вообще узнать о пользователе по-максимуму
А у нас есть такая особенность, что товары часто ротируются. То есть закупаются новые коллекции в небольшом объеме,продаются за месяц-два, и их больше нет в наличии
Поэтому решили вдобавок к учету всех действий (просмотру, добавлению в корзину и избранное, покупке) накрутить еще агрегацию товаров в такие устойчивые группки, чтобы нивелировать высокую ротацию (вроде кросы найк за косарь)
и это все запихнуть в ALS
В итоге в тесте это выехало на самой простой платформе для разработки, но с не самой лояльной аудиторией (десктопе), поэтому все вообще вышло грустно, статистики было мало и проект немного заморозили
В прошлом году он оттаял, потому что выделили ресурсы на разработку на всех наших платформах, и статистику для подборки решили тоже собирать по всем платформам
Это потребовало некоторых доработок с нашей стороны и когда мы заглянули в код, оказалось, что за год он превратился в тыкву (ну то есть в легаси).
В итоге всместо быстрого фикса пришлось обновлять код, так как тест уже был в плане
Помните про все эти наши махинации с действиями и группками товаров?
Так вот спойлер: пользователи заметили подвох, что не все условные кроссовки найк за косарь одинаковые и могут им понравится.
А еще им было совершенно непонятно, откуда товары в подборке берутся: то ли они что-то похожее смотрели, то ли это потому что они что-то не то заказали, и на избранное совсем не похоже....
опа
А вот за последнее из обратной связи мы зацепились
В итоге мы решили выкинуть все сложные надстройки и сделать ALS на товарах, которые есть в избранном у пользователя.
Так сигнал для модели стал очень четким, что и сделало рекомендации понятными, реально похожими на то, что в нравится пользователю и полезными.
Мы еще немного поколдовали, а тем, у кого нет избранного, сделали подборку на просмотренных товарах
Сейчас у нас идет новый тест, и если вы залогиненый счастливчик, то можете ее увидеть на главной Lamoda 🙂
Тред (Дарья Пронина)
Четверг
Одной из задач нашей команды является персонализация коммуникаций с клиентами, а одной из ее частей - выделение сегментов для рассылок.
На тот момент у маркетинга было много сегментов на простых правилах вроде Покупал детские товары - лови баннер со скидками на школьную форму.
Но это все-таки дает небольшой охват, поэтому мы взялись делать сегменты look-alike на просмотрах товаров.
То есть берем пользователей, которые нам нужны (например, покупали детские вещи), преобразовываем их историю просмотров в фиче-вектор и используем их как положительные примеры.
За отрицательные берем юзеров, которые тоже делали покупки, но покупали что-то другое.
Фиче-вектор составляли из нормализованных каунтеров по просмотренным брендам, цветам и еще кучи атрибутов товаров, поэтому получалась выборка несколько сотен тысяч пользователей на несколько тысяч фичей.
Короче, данных было че-то многовато и в качестве первого подхода решили использовать встроенный в spark классификатор.
Получилось изи кам, но не изи гоу(
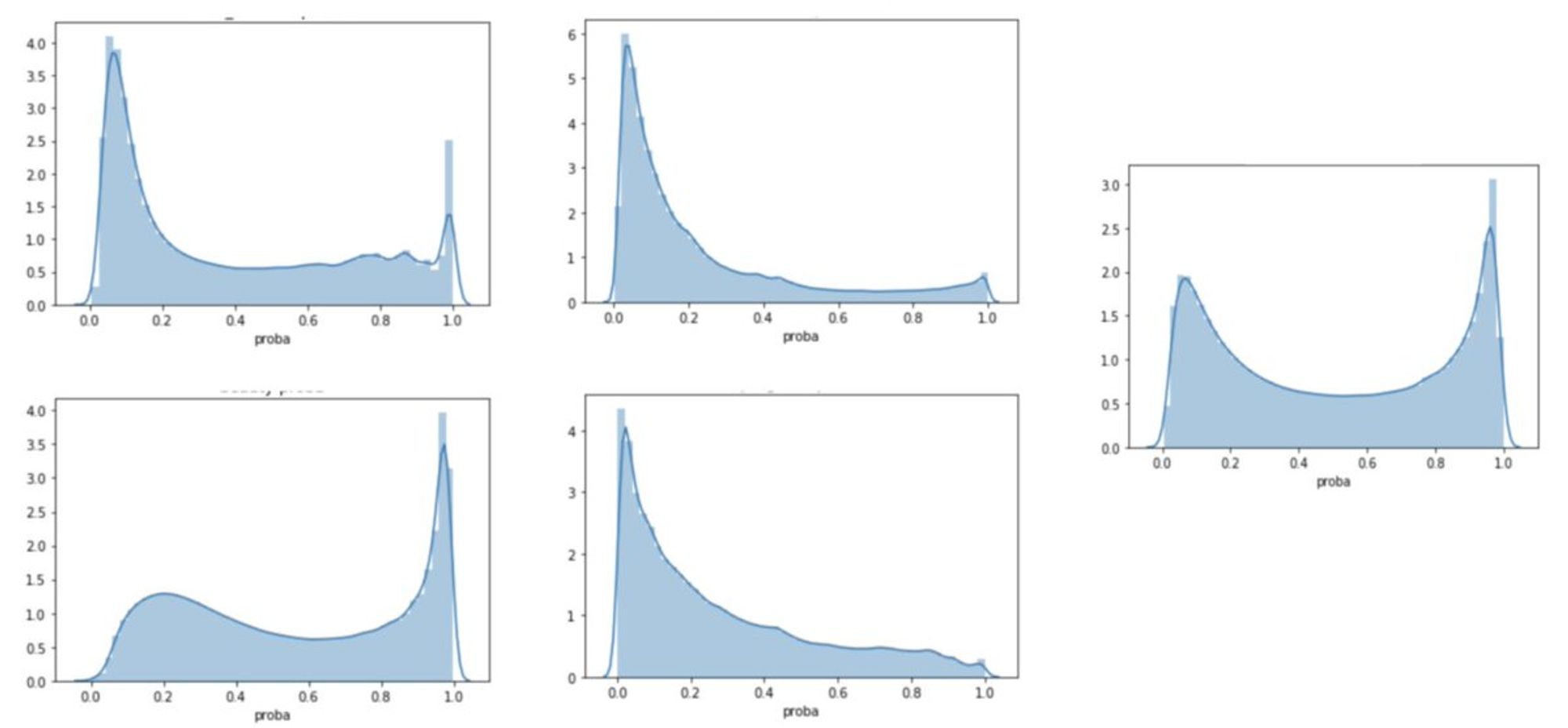
Вставлю даже вам картинок из моей презы на внутреннем митапе)

Потом мы прослышали про чудо чудесное, да диво дивное под названием Spark XGBoost.
Все в нем было в лучших традициях оупенсорсного непопулярного проекта: как установить не ясно, документации толком нет, половина функционала не работает.
В итоге чтобы хоть как-то завести его, мне пришлось для обучения использовать одну версию, а для инференса - другую. Потому что в первой не было класса, читающего модель из файла, а во второй - падало обучение🤡
Зато метрики качества наконец показывали приемлимые результаты

И все казалось бы ок, пока маркетинг не сообщил, что они хотят иметь возможность самостоятельно подбирать трешхолды для каждой рассылки и им нужно возвращать не 0/1, а вероятность принадлежности к сегменту
Мы подумали, ну окей, не вопрос. В обычных моделях же не сложно вернуть вероятности вместо предсказаний....
Но изините, это ж НА СПАРКЕ. Поэтому на любое хочу - поешь говна.
В общем, мы как-то все-таки получили вероятности и решили взглянуть на распределение, чтобы сначала предложить маркетингу оптимальный трешхолд...
как говорится, результат убил
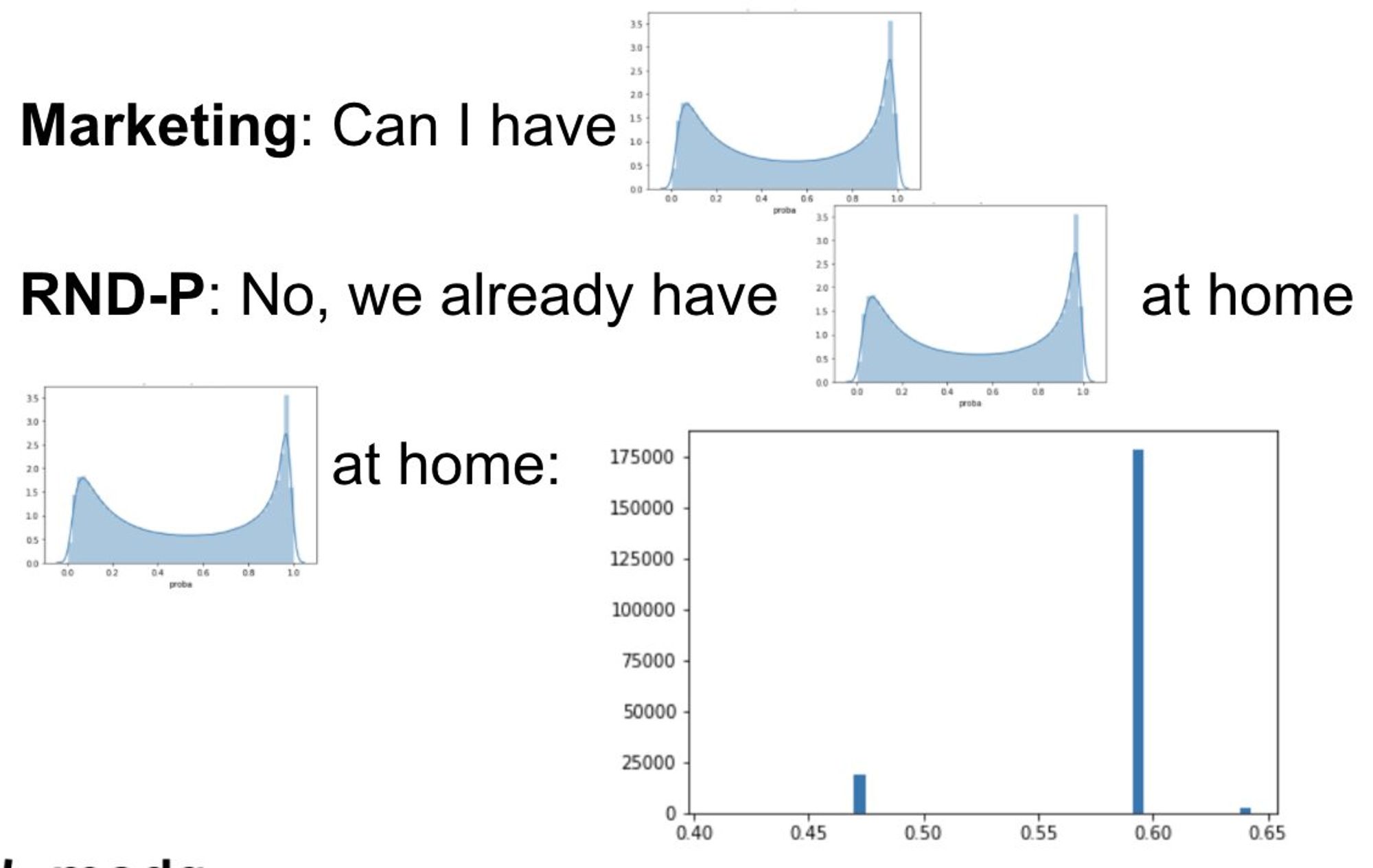
В общем, да. Модель реально тупо возвращала только 2-3 значения вероятности, хотя мы ожидали какого-то адекватного распределения с пиками в 0 и 1.
Как при всем этом метрики выглядели нормально - для меня до сих пор загадка
В итоге решили ужаться по данным и пропихнуть все в обычный xgb. Пришлось пилить 2 джобы (обучение и инференс) на 4, где на первом этапе мы собирали датасет обычным контекстом, а на втором - отъедали здоровенный драйвер и вертели модельки. Было больно, но результат вышел хороший)

Ну и напоследок - немного ананимизированных lal function porn (ну лал - это типа лукэлайк вместо лосс, ну вы поняли)
Тред (Дарья Пронина)
Пятница
Все хочу поговорить на серьезные темы, а получаются только кулстори 😅
В общем, хочу затронуть такую тему как разделение ответственности за продукт в DS. Интересно, как это устроена у вас и вообще думаете ли вы от этом)
У меня часто по ходу работы над функционалом возникает много идей, как можно было бы сделать лучше и что ещё можно потестировать.
Я обычно слежу за нашими клиентскими исследованиями и стараюсь в конечном решении учесть максимум болей пользователей.
В целом это вроде как здоровая история, что разработчики вовлечены в продукт и тоже стараются что-то превносить
Но у нас появлялись, как бы это назвать... коллизии ответственности что ли)
Потому что есть тимлид (он же техлид продуктового направления по сути). Он продумывает архитектуру фичи и обсуждает ее с разными людьми на всяких встречах, от которых разработчики избавлены к счастью
Есть ещё продакт-менеджер. Он занимается продуктовой проработкой и может в любой момент подкинуть тебе нереалистичную идею для улучшения. В итоге мы несколько раз обсуждаем, что это сложновато и лучше не сильно отходить от предварительно утвержденного концепта
В итоге и твоей идеи "Сделать простую фичу на конкретном фреймворке", которую все одобрили, по ходу реализации получается такое письмо из Простоквашино, где тимлид на встречах утвердил другую техническую реализацию, а продает накидал хотелок, которые в фреймворк не вписываются.
Теперь вопрос в зал) Кто в такой ситуации стать быть product owner и нести ответственность за конечный результат фичи?
Немного подержу опрос, потом расскажу, как мы решали эту проблему
Ну и пишите свои мысли или как у вас похожий процесс устроен)
🤔
13.6% Data scientist🤔
40.9% Team lead🤔
45.5% Product managerСуббота
Итак, по опросу приз в виде product owner'ва получил продакт менеджер)
Напомню, что наша ситуация была отягощена тем, что у меня шило в жопе😅 С этой позиции и расскажу наше итоговое решение
В первую очередь, мы разделили продуктовую часть проекта (дизайн и реализацию на сайте/аппах) и техническую (моделирование и бизнес-правила с нашей стороны) в отдельные проекты прямо на этапе планирования.
Если проект попроще - например, какой-то эксперимент новой модели рекомендаций в уже существующей полке, то проект заводим полностью на нас.
Если наоборот - основная часть на клиентах, а от нас нужно например тупо посчитать топ кликнутых фильтров, то проект полностью на плечах PM
Дальше остается только вопрос, как распределить роли внутри команды.
В итоге решили, что некоторые проекты можно выдвигать при желании самостоятельно: самому их планировать и описывать, питчить на квартальных встречах, ходить на проектные встречи и следить чтобы никто не косячил
Это конечно добавляет немного головной боли и несколько встреч, но в итоге ты прокачиваешься в менеджерских скилах и вообще после релиза супер горд за себя🙂
Тред (Дарья Пронина)
Сегодня хочу поделиться опытом того, как я вкатилась в публичные выступления.
Вкатывание заняло примерно 2 года)
Тогда мне казалось, что я вот просто дата саентист, а те, кто выступают на конфах, - они такие.... ну прям супер-крутые шарящие эксперты!)
И из этого у меня в голове рождалось такое "логическое" заключение, что вот сейчас я еще поднаберусь опыта и потом как начнуу про него рассказывать и как стануу экспертом, ваще будет жара. Буду получать многа деняк
А выступать как будто я и так уже умею. В школе же все с докладами выступали и было норм.
Оказалось, что все связано вообще не так😅 Выступающие - конечно эксперты. Но самое важное в хорошем докладе - не крутость опыта спикера, а соответствие доклада цели и аудитории, правильная и понятная структура, уверенность подачи и всякое такое
В общем мне как-то стало понятно, что нужно получать навык публичных выступлений, а не ждать какого-то необычного опыта в индустрии
К счастью, Женя Голева, наш ex-devrel, проводила у нас Speakers Club. Раз в 2 недели можно было прийти в дружелюбное пространство с докладом на 5 минут и получить обратную связь.
(кстати у Жени есть клевый канал t.me/speakersclub)
Я подготовила небольшой доклад про недавнее исследование и думала, что сейчас расскажу на изи.
В итоге я нервно тараторила свой доклад в стрессе и с потеющими ладошками)) В целом, вышло неплохо, но главное - я получила опыт выступления!
Второй раз выступать в клубе было проще - я делала доклад на нерабочую тему (рассказывала про фридайвинг). Мне задавали интересные вопросы и доклад всем понравился намного больше)
С подачей и боязнью сцены стало заметно лучше. Я уже меньше тряслась и запиналась.
Но остался вопрос, как сделать контент? Как взять рабочую задачу и положить ее в понятный по структуре доклад, который смогут слушать аж 40 минут и не уснуть?
В этом мне просто нереально помогла книга Emma Ledden - The presentation book. Там все НАСТОЛЬКО разложено по полочкам и разжевано, что я скринила чуть ли не каждую страницу как памятку))
После прочтения я стала опробовать подходы из книжки на небольших выступлениях у нас на внутренних митапах (там мы просто делимся интересными результатами внутри R&D).
Делала все как надо) продумывала запрос аудитории, складывала технические детали в целостную историю и пр.
После этого занялась подготовкой первого доклада для публичного мероприятия. Несколько месяцев я переклеивала стикеры с основными мыслями, делала презентацию, устраивала прогоны и слушала обратную связь
В итоге с уже готовым докладом я подалась на первый митап, и он сразу был онлайн.
И ЭТО БЫЛО БОЕВОЕ КРЕЩЕНИЕ, после которого посреди доклада я уже могу хоть жонглировать и продолжать спокойно рассказывать материал.
Короче, сначала было все норм. Я специально приехала в офис (это было уже лето 2020), все настроила на ноуте, чтобы меня было хорошо видно/слышно. Заранее проверили с организатором и режиссером трансляции, что у меня все супер
Я стояла в программе 3им спикером и под конец второго выступления, я понимаю, что у меня начинает что-то лагать... Со мной пытаются наладить связь, но все равно видео тормозит, звук икает и отстает. Все то налаживается, то снова лагает.
Меня все-таки решают выводить в трансляцию (на секундочку, моего первого доклада!).
Через 5 минут, мне пишут в чат, что меня не слышно. предлагают подкрутить какие-то настройки в ебучем софте для этой трансляции. Не отрываясь от рассказа, я пытаюсь менять настройки
Дальше вроде все ок, но еще через 5 минут я слышу в наушнике, как режиссер трансляции обсуждает со своим коллегой, что меня не слышно и что им делать. Я продолжаю доклад, слушая пиздеж в наушниках....
Вишенкой на торте было то, что этот режиссер пока обсуждал начал ходить по своей квартире и в этой софтине я вижу, как он размахивает своим пузом, торчащим из футболки🤢
Спустя еще минут 5-10 этого трешака, меня все-таки отключили и доклад перенесли.
После такого, мне вообще пофиг, что происходит вокруг, я просто рассказываю доклад)))
После, анализируя лаги моего компа, я все-таки склонилась к тому, что он ПРОСТО РЕШИЛ ОБНОВИТЬСЯ в самый нужный момент. С тех пор автоапдейты я держу выключенными😑
Я выступила там же второй раз через месяц и получилось хорошо)
Дальше я уже думала над следующим докладом, снова несколько месяцев готовилась, и подалась на datafest 2021. Запись посмотрели уже аж тысяча человек🤯! Теперь могу себе в прошлом сказать, что стала крутым экспертом😆
Тред (Дарья Пронина)
К теме про выступления хочу узнать ваше мнение про личный бренд)
По-вашему, личный бренд - это
🤔
4.2% лишняя трата времени🤔
27.7% развлекуха для нарциссов🤔
50.0% спсоб найти крутую работу🤔
18.1% вы непонимаете это другоеВоскресенье
Воу! Почти половина народа считает, что личный бренд рили помогает. Спасибо, что ответили!)
На сегодня финальный тред про собеседования.
Будут непрошеные советы и кулстори.
Меня очень беспокоит, что ппц как много начинающих (и не только) специалистов говорят что-то вроде: "Я ТУПОЙ! Меня никуда не возьмут! Куда уж мне?"
Я очень хочу отменить синдром самозванца, можно?
Я считаю, что фразу "я тупой" надо каждому забыть как страшный сон и никогда к себе больше не применять. Вот прям с этого момента.
Что это вообще за линейка, по которой меряют умность? Где заканчивается "умный" и начинается "тупой"? Если я не знаю столицу Болгарии, я умная или уже нет? А если еще и не понимаю теорему о подобии треугольников?
Короче, границы только в нашей голове (с) пацанский паблик
Но проблема того, что начинающим специалистам сложно оценить свой опыт и навыки, безусловно есть.
Что же они с этой проблемой делают?) Правильно, сравнивают себя с другими. А тут уже любая деталь, которая тебе показалась классной у другого, представляет его умным,а тебя - тупым
Лучший выход из этой ситуации, как мне кажется, - это искать вакансии, смотреть на требования в них и соотносить наличие у тебя практического (!) опыта применения навыков/требований в жизни. Сколько процентов от вакансии набрал - с такой уверенностью можно идти на собес.
Потренируемся!
Предположим, я недавний выпускник профильного вуза и ищу стартовую позицию в дс.
Я нашла 2 вакансии с первой странички hh по запросу data scientist junior, отработаем на них нашу технику)
Вакансия 1. t.ly/72Ur Лаба в РАНХИГС. Сверяем навыки:
-1 год опыта (у нас 0)
-отличные знания в нейросетках (мы про них только слышали на парах, так что минус)
-зато за ансамбли и стат методы по плюсику
-в python умеем
-в linux и инфбез - нет
итого у нас 3/7 очков
Вакансия 2. t.ly/9Pzo Профи ру.
-python знаем начально, SQL знаем нормально
-основы Computer Science знаем
-в ML есть учебные проекты - это подходит
-матподготовка есть
-осваивать новую информацию умеем
-желания развиваться как MLE предположим немного
6/7 очков!)
Подведем итог.На первую я бы откликнулась без особых ожиданий, а на вторую кажется почти идеально подхожу!
Какой вывод можем сделать?)
Нет линейки тупой/умный, есть только соответствие твоих навыков и опыта вакансии.А если нет нужных навыков - теперь понятно, в чем прокачаться!
Дальше конечно идут сами собеседования, где все может оказаться не так, как в вакансии)))
Некоторые бывают даже довольно травмирующими, но важно не воспринимать их в серьез.
Например, после первого года работы меня занесло на собес в мэйл ру.
Сначала мне дали список вопросов, на которые нужно было ответить письменно. Первые 2 вопроса были что такое матожидание и дисперсия, дальше что-то про ip и tcp протоколы и подобное.
Я, честно говоря, до сих пор не знаю, чем они отличаются)))
Но тогда чел вынес мне мозг, что я на самом деле не интересуюсь DS и наверно я тут ради денег только. А в таком случае мне бы лучше было пойти в модельный бизнес.
Или страхование.
СПАСИБО ЧТО ПРОГЛОТИЛ СЛОВО ЭСКОРТ
Во-первых, я на всякий случай больше не хожу на собесы в водолазках... Привет, сексизм и лукизм👋
Во-вторых, я тогда уже определила для себя, что анализом данных хочу заниматься хоть всю жизнь и сказать мне, что я не интересуюсь было абсуродом.
Короче, если вы не прошли собес - не надо загоняться ни в коем случае. Просто помашите этой компании ручкой и найдите место для себя получше)
И тем более никогда не ведитесь на то, какие вам дают советы на собеседованиях, если они вам не откликаются.
Для меня в начале карьеры это "следование за авторитетами" было немного травмирующим.
Но камон, если в примере выше очевидно,что высказывания интервьюера не про меня, тогда почему другие про меня? Почему я доверяю первому встречному больше чем себе?
Шлите умников с собесов нахуй)
И последний непрошеный совет:
Не надо романтизировать компании. Не надо грезить условным яндексом, если ваш тошнит от литкода) Или какой-то компанией, которая вас чем-то зацепила из вне: проектами, классной статьей, каким-то классным чуваком оттуда, whatever.
Фишка в том, что вы рискуете много поставить на карту, а выйдете на работу - окажется все воообще не так радужно)
Лучше всего исходить из того, что нужно вам сейчас (например, прокачаться в spark или прибавить в зп), и если что сменить работу, чем мечтать о непонятной идеальной
Бывает, что клево оказывается там, где не ожидаешь) Так я решила пойти сначала продуктовым аналитиком в Lamoda, потому что вакансий в ds тогда не было. Я думала, что это немного по-лоховски) но тогда мне слишком хотелось работать в крупном бизнесе и нетоксичном коллективе
И это был супер-крутой год! Я очень много узнала про продуктовые метрики, делала клевые рисерчи, разбиралась, как делается диджитал-продукт. А потом вообще присоединилась к R&D в качестве дата-саентиста)
Короче.
Вы не тупые)
Я была очень рада тут писать про свой опыт! Cпасибо за ваши лайки и ответы🧡 Подписывайтесь на меня @polyaniza, давайте больше болтать😺🕺
Тред (Дарья Пронина)
Начнем про путь в data science. Интересно, как у вас это происходило, потому что у меня, как мне кажется, все пошло немного через жопу))
Метатред того, что было за последнюю неделю)
Начали с моего пути в DS) и о том, как мне "помог" универ twitter.com/dsunderhood/st…
Штош. С большим отрывом лидирует техническое образование, что и видно по ожиданиям в вакансиях) Но я все-таки не особо жалею, что училась на экономико-математическом, потому что это дало свои плюсы: twitter.com/dsunderhood/st…
Отдельно было про еще про универ twitter.com/dsunderhood/st…
Так вот про Летнюю школу) twitter.com/dsunderhood/st…
Рассказывала про образовательный проект Летняя Школа twitter.com/dsunderhood/st…
Немного про работу R&D Lamoda У нас 3 DS-команды, разделенные по стримам: -Навигация - ранжирование+поиск, -"Персональный помощник" - это всякая персонализация+рекомендации и немного продуктовых фичей для облегчения жизни пользователей -Ценообразование (ну тут понятно)
Про R&D Lamoda и наши проекты, в том числе в CV twitter.com/dsunderhood/st…
Один из моих больших проектов за последний год - это отдельный раздел с персональной подборкой товаров на сайте и в приложениях. Выглядит это примерно так: pic.twitter.com/fVCkNP0hHR
Про то, как мы делали персональную подборку) twitter.com/dsunderhood/st…
Одной из задач нашей команды является персонализация коммуникаций с клиентами, а одной из ее частей - выделение сегментов для рассылок.
Про приколы ML на spark на примере моего проекта с сегментами для рассылок twitter.com/dsunderhood/st…
Все хочу поговорить на серьезные темы, а получаются только кулстори 😅 В общем, хочу затронуть такую тему как разделение ответственности за продукт в DS. Интересно, как это устроена у вас и вообще думаете ли вы от этом)
Про разделение ответственности за продукт twitter.com/dsunderhood/st…
Сегодня хочу поделиться опытом того, как я вкатилась в публичные выступления. Вкатывание заняло примерно 2 года)
Про то, как я вкатывалась в публичные выступления и мужика с торчащим пузом) twitter.com/dsunderhood/st…
На сегодня финальный тред про собеседования. Будут непрошеные советы и кулстори.
Про то, как понять свой уровень в DS и не травмироваться от собеседований twitter.com/dsunderhood/st…
Тред (Дарья Пронина)








