Одной из задач нашей команды является персонализация коммуникаций с клиентами, а одной из ее частей - выделение сегментов для рассылок.
На тот момент у маркетинга было много сегментов на простых правилах вроде Покупал детские товары - лови баннер со скидками на школьную форму.
Но это все-таки дает небольшой охват, поэтому мы взялись делать сегменты look-alike на просмотрах товаров.
То есть берем пользователей, которые нам нужны (например, покупали детские вещи), преобразовываем их историю просмотров в фиче-вектор и используем их как положительные примеры.
За отрицательные берем юзеров, которые тоже делали покупки, но покупали что-то другое.
Фиче-вектор составляли из нормализованных каунтеров по просмотренным брендам, цветам и еще кучи атрибутов товаров, поэтому получалась выборка несколько сотен тысяч пользователей на несколько тысяч фичей.
Короче, данных было че-то многовато и в качестве первого подхода решили использовать встроенный в spark классификатор.
Получилось изи кам, но не изи гоу(
Вставлю даже вам картинок из моей презы на внутреннем митапе)

Потом мы прослышали про чудо чудесное, да диво дивное под названием Spark XGBoost.
Все в нем было в лучших традициях оупенсорсного непопулярного проекта: как установить не ясно, документации толком нет, половина функционала не работает.
В итоге чтобы хоть как-то завести его, мне пришлось для обучения использовать одну версию, а для инференса - другую. Потому что в первой не было класса, читающего модель из файла, а во второй - падало обучение🤡
Зато метрики качества наконец показывали приемлимые результаты

И все казалось бы ок, пока маркетинг не сообщил, что они хотят иметь возможность самостоятельно подбирать трешхолды для каждой рассылки и им нужно возвращать не 0/1, а вероятность принадлежности к сегменту
Мы подумали, ну окей, не вопрос. В обычных моделях же не сложно вернуть вероятности вместо предсказаний....
Но изините, это ж НА СПАРКЕ. Поэтому на любое хочу - поешь говна.
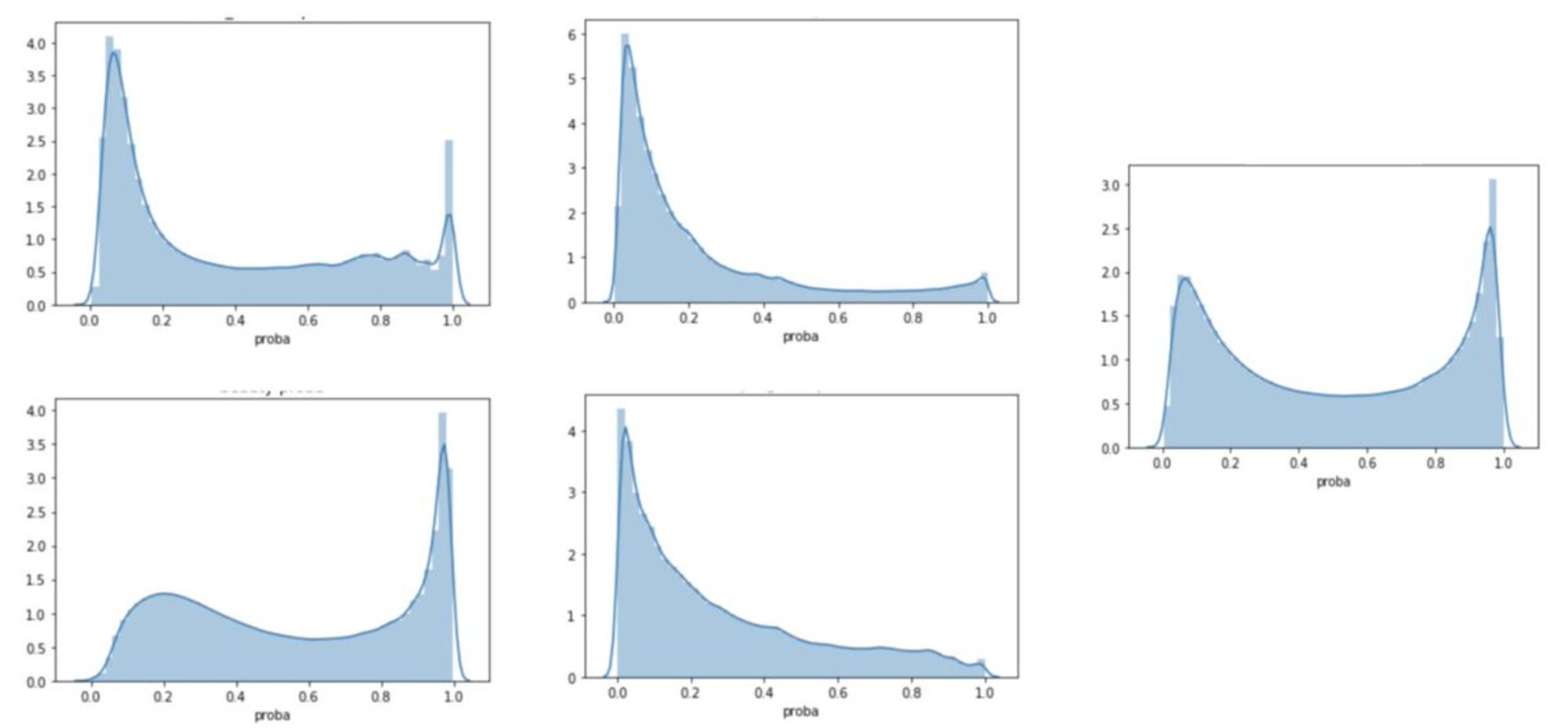
В общем, мы как-то все-таки получили вероятности и решили взглянуть на распределение, чтобы сначала предложить маркетингу оптимальный трешхолд...
как говорится, результат убил
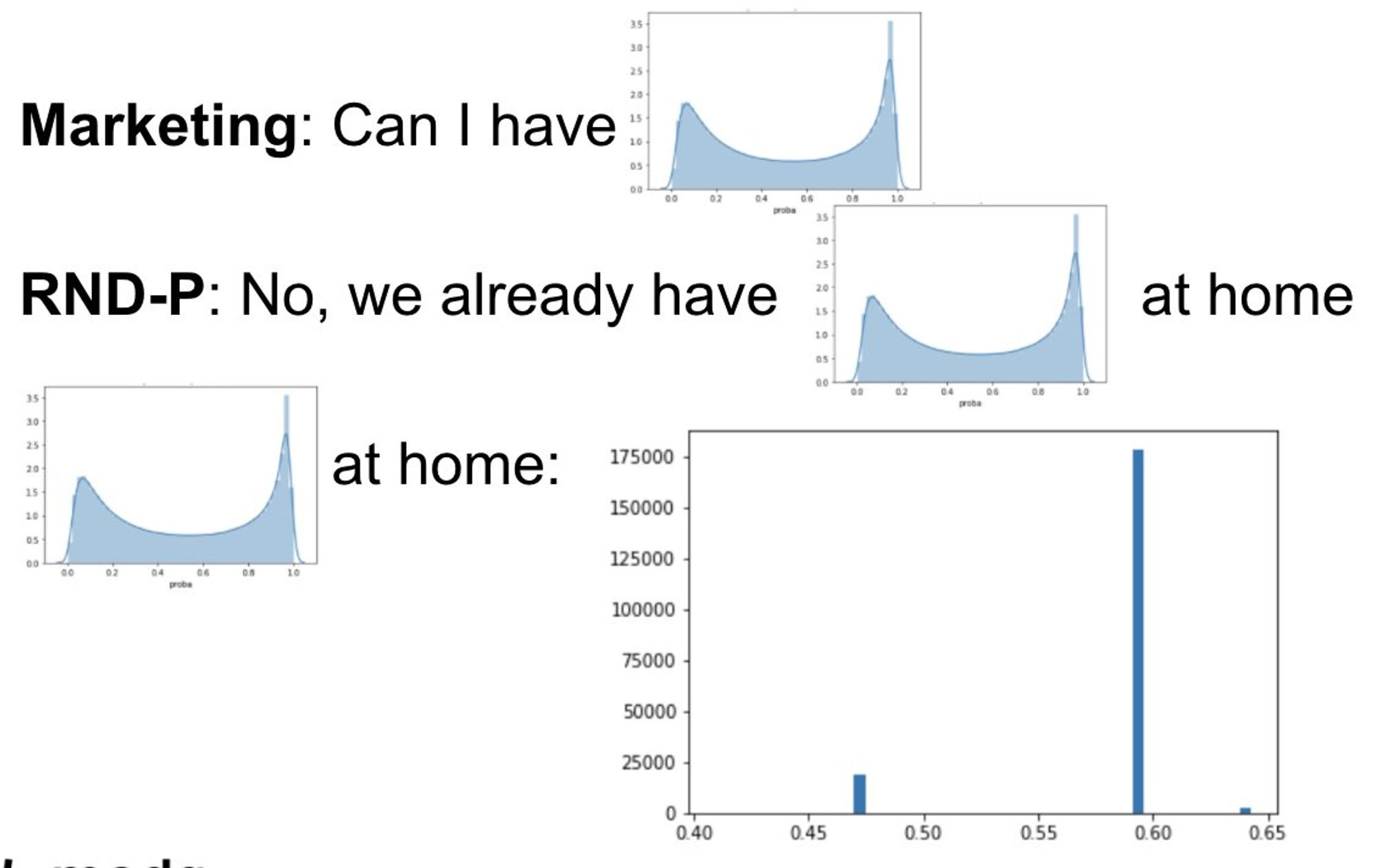
В общем, да. Модель реально тупо возвращала только 2-3 значения вероятности, хотя мы ожидали какого-то адекватного распределения с пиками в 0 и 1.
Как при всем этом метрики выглядели нормально - для меня до сих пор загадка
В итоге решили ужаться по данным и пропихнуть все в обычный xgb. Пришлось пилить 2 джобы (обучение и инференс) на 4, где на первом этапе мы собирали датасет обычным контекстом, а на втором - отъедали здоровенный драйвер и вертели модельки. Было больно, но результат вышел хороший)

Ну и напоследок - немного ананимизированных lal function porn (ну лал - это типа лукэлайк вместо лосс, ну вы поняли)