Архив недели @m12sl
Понедельник
Всем привет! Меня зовут Лёша Озерин @m12sl, на этой неделе штурманом буду я.
Закончил МФТИ в 2011 году, до сих пор люблю физику и матан.
Работал в Deephack/Reason8, сейчас преподаю в ВШЭ и работаю в Яндексе. В основном занимаюсь нейронными сетями.
На этой неделе я буду в основном агитировать разбираться в том, как работают рабочие инструменты.
Если что, нейронки для меня -- это просто формулы с параметрами. В реальных задачах без человеческой экспертизы никуда, так что если можете обойтись без DL (и без ML), обойдитесь :)
Примерный план на неделю:
- поговорить про инструменты
- как катить сетки в прод
- немного про архитектуры
- про BatchNorm
- вспомним word2vec
- поговорим про алгоритмы
- если останется порох, немного расскажу про очень быстрое преобразование Фурье
Самый богатый источник граблей - рабочие инструменты.
Очень часто наблюдаю как люди тонну времени тратят на войну с инструментами, а не задачей.
Распространенная история - человек что-то делал, получил результаты, но им нельзя доверять => работу надо переделывать.
Про инструменты.
Я в основном пишу код на питоне, эпизодически на C++, иногда JS/bash и на чем еще придется по задаче.
Все хоббийное и учебное я пишу на Pytorch, почти все рабочее на TF.
Имхо про фреймворки:
- конкуренция это здорово, tf был удобнее theano, pytorch удобнее tf, tf2 удобнее tf1
- не важной какой фреймворк вы используете, кодовую базу и математику сетей нужно заботать, иначе в ваших результатах буду валенки
- ....
- сетки падают молча, так что для поиска ошибок приходится вникать в происходящее
- даже если вы тренируете много сетей, расходы на написание трейнлупа с нуля обычно небольшие. Потому (прости @scitator) мета-фреймворки не нужны.
- но в них точно стоит подсматривать
Пара непопулярных идей:
- не надо собирать девбокс, это дорого и не поможет заботать DS
- админить рабочее окружение затратно и не помогает заботать DS, берите готовое (colab, datasphere, anaconda)
- jupyter-тетрадки прекрасны!
- aws/azure/google compute cloud/... и прочие облачные ребята
- железные сервера, например hostkey
- предложений сильно больше, но по использованию будет похоже на кого-то из них
На чем учить сетки и экспериментировать?
В порядке увеличения контроля, возможностей и головняка:
- colab и kaggle kernels.
- по гранту или за небольшие деньги на Colab Pro или DataSphere (в отличие от бесплатного colab можно отключать и долго считать)
- vast.ai
Тред #1
Что стоит знать в фреймворке (для определенности pytorch):
- как строится вычислительный граф (у тензоров есть backward-функция, за которую можно дернуть для бекпропа)
- как представлять данные (условно складываем картинки в тензора [bs, channels, height, width])
- как управлять оптимизатором (обход весов, lr scheduling, grad_clip..)
- как мерить скорость и утилизацию железа (tqdm, watch nvidia-smi, profiler..)
- как дебажить наны (forward_hook, backward_hook)
- как сериализовать модель (torch.save, jit.trace, jit.script)
- как вычисляется лосс (давайте опросом, что должно быть у сети для многоклассовой классификации в голове?)
Пояснения на всякий случай:
- в доку не подглядывать!
- FC=Linear (иначе не лезло)
- если не понимаете о чем речь => reply с вопросом
🤔
18.0% FC,Softmax,NLLLoss🤔
23.6% FC,LogSoftmax,NLLLoss🤔
51.7% FC,Softmax,CrossEntropyLo🤔
6.7% FC,LogSoftmax,CrossEntropвдогонку микровопрос про бекпроп.
У нас есть MLP (несколько Linear слоев с нелинейностями или без), можно ли инициализировать матрицу весов нулями?
🤔
30.8% да🤔
69.2% нетвторой микровопрос, можно ли инициализировать матрицу весов нулями в двух Linear слоях подряд?
🤔
18.9% да по индукции🤔
81.1% теперь точно нетВторник
В основном на курсах по ML/DL речь идет про обучение моделек. MVP делается на слегка подправленной кодовой базе с питоном и фласками.
Моделька создается кодом, в нее подгружаются веса из чекпоинта.
Если проект не умер на первых порах, дальше пойдет эволюция.
Пояснения к опросам я выложу завтра. А пока поговорим про сетки в проде.
В какой прод вы катите ML/DL модельки?
🤔
60.5% сервера🤔
6.7% мобилки🤔
5.9% браузер/компы юзеров🤔
26.9% прода нетЛюди прибывают. Модельки усложняются.
Появляется легаси (и это нормально!).
Вы начинаете страдать от обратной совместимости, а она от вас, катить становится сложнее, в коде копятся валенки (скажем другой метод ресайза картинок будет стоить вам процентов acc@1 на imagenet).
Давайте просто договоримся сериализовать вычислительный граф с весами и передавать его!
Если речь идет про классификацию картинок произвольного размера, например договариваемся кидать на вход картинки uint8 [1, 3, ?, ?], ресайз и прочий препроцессинг делать в графе...
Разумным решением будет разделить окружение на тренировочное и продовое, а затем разделить кодовую базу.
Как меньше страдать от синхронизации кода моделек и процессингов в разных окружениях?
🤔
13.3% git submodule🤔
46.7% Переписать все на плюсах!🤔
20.0% Сохранять в ckpt код🤔
20.0% Свой вариант в комментыСложность никуда не исчезает: код для экспорта моделек может стать достаточно интересным, но он лежит рядом с трейновой кодовой базой, выполняется редко, возможно даже в ручном режиме.
А вот код для запуска модели максимально простой и может быть отчужден.
моделька пусть возвращает два вектора: с названиями классов и вероятностями top5 ответов.
Пример условный, но смысл в том, чтобы коде инференса было минимальное количество вычислений.
Про скорость.
Переписать все на плюсах и полететь - это очень распространенная фантазия, но обязательно попробуйте!
Так-то питон не сильно замедляет применение моделек по сравнению с С++ API (если вычисления сложнее перемножения пары матричек).
от питона в проде (и гигабайтов библиотек) и использовать специализированные движки для инференса. Сейчас их стало достаточно много, но основных всего ничего:
- tf/torchscript
- tflite для мобилок
- ONNX - (не только для DL-моделек)
- TensorRT (GPU)
- OpenVINO (Intel CPU)
Понятное дело, что в реальности у нас могу быть другие потребности: например обрабатывать картинки батчами. Значит их придется ресайзить во время применения и в проде снова появится код с вычислениями.
Если все вычисления делать в вычислительном графе мы сможем отказаться ...
Может дать больше качества, чем учить маленькую модель на том же датасете.
В чем поинт:
- большая модель может сгладить ошибки и неполноту разметки
- можно учиться на тонне неразмеченных данных
- можно сменить тип модельки авторегрессионную в простую feed-forward
Когда код запуска отлажен и запрофилирован, а скорости мало, приходится делать что-то с модельками.
Обычно говорят про дистилляцию, квантование и прунинг.
Дистилляция модельки - это обучение маленькой модельки на выходах большой.
через сетку прогоняется калибровочный набор данных, для каждого слоя выбирается оптимальный zero-point и scale. Вместо одной fp-операции с fp-входами-выходами получается три операции: quantizing -> q_op -> dequantizing.
Квантование - классная штука. Нам нужны float point-числа чтобы работал градиентный спуск, часто при переходе к fp16 возникают проблемы со сходимостью обучения.
Но во время инференса точность не особо нужна.
Сейчас популярно квантование в int8, после тренировки:
Подряд идущие вспомогательные операции склеиваются и в идеале весь граф состоит из квантованных операций.
Подводные камни простые:
- не все получается конвертировать (и выигрыш в одном месте теряется на лишних конвертациях)
- портится качество
Прунинг - зануление весов. Обычно просто по гистограмме значений зануляются маленькие по модулю числа.
Из неочевидного: чтобы неупорядоченный прунинг дал прирост скорости нужны спарсные операции и занулять значительную долю весов.
В добавок к этим трем понятным вариантам есть еще один чуть более глубокий: инференсный граф может отличаться от тренировочного.
Когда речь идет про картиночные сетки мы так часто и делаем не задумываясь: BN в валидационном режиме превращается в простое аффинное преобразование..
Так что для скорости нужно делать структурный прунинг: выбрасывать целые каналы и слои.
На прунинг можно смотреть как на регуляризацию, в такой постановке он тесно связан с гипотезой счастливых билетов, но это уже не про оптимизацию инференса)
Красивую идею предлагают в недавней статье RepVGG: давайте учить ResNet, а инферить VGG.
Пояснение: в резнетах хорошо текут градиенты, это позволяет тренить 100+ слойные слойки.
VGG в свою очередь добры к потреблению памяти:...
отсутствие срезок (skip-connections) позволяет тратить сильно меньше памяти, но тренировать глубокие VGG-like сети тяжело (градиенты и сигналы затухают).
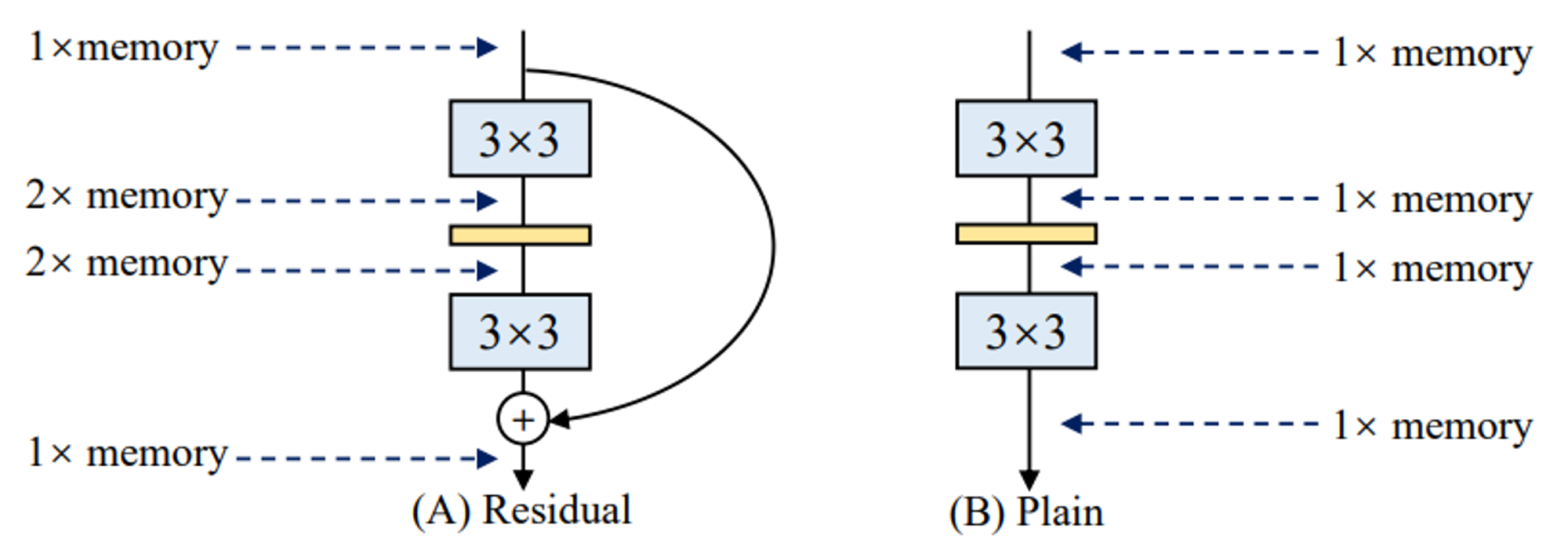
Предлагается сделать математический трюк: изменить ResBlock так чтобы его можно было конвертировать в Conv + Activation с идентичными ответами.
Для этого делаем ResBlock тощим:
- три ветки вычислений
- Identity + BN
- Conv 1x1 + BN
- Conv 3x3 + BN
- ReLU после суммирования

Так-то подобные работы делали и раньше, привожу эту как наиболее наглядную.
Статья в целом наталкивает на мысль что мы не очень-то хорошо умеем инициализировать и оптимизировать модельки.
Ссылочка на всякий случай: arxiv.org/abs/2101.03697
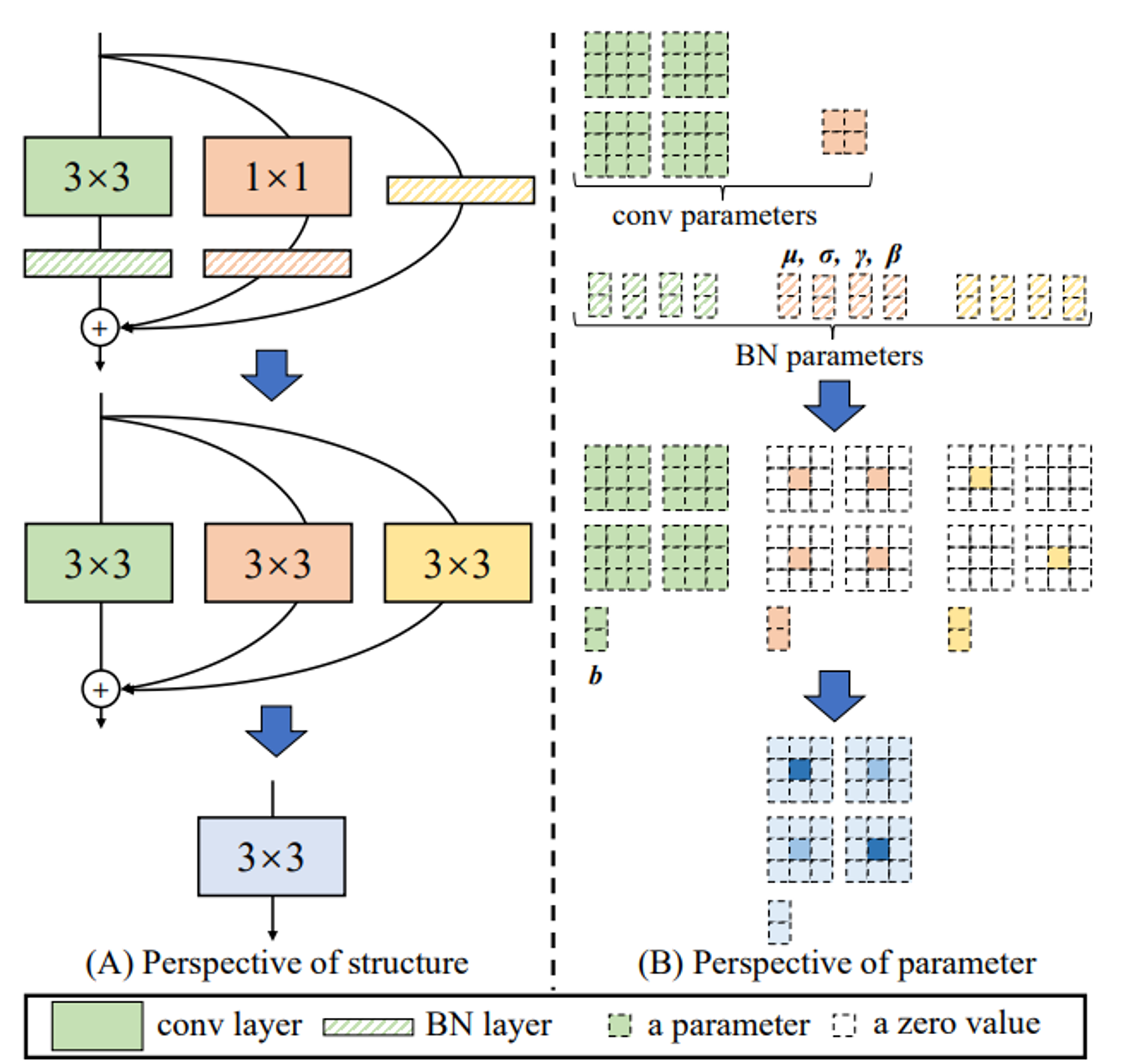
Конвертация в VGG-блок делается так:
- распячиваем Identity и Conv 1x1 в Conv 3x3 (ядра с нулями).
- BN-eval заносим в свертку (ядра умножаем на мультипликативную поправку, аддитивную в bias)
- складываем ядра -> получается одна свертка 3x3
- ...
- ответы сети идентичны исходным!
Тред #2
Среда
Попробуем как в старые добрые на доске, но без доски.
Если x не нулевой и градиенты на выход придут ненулевые, то W изменится на первой итерации и дальше все будет хорошо.
Могут ли градиенты быть не нулевыми? Зависит от дальнейшего графа :) еще один сломанный FC не даст учиться

Четверг
Названия и обрывки математики из лекций приводят к путанице.
Мы вроде бы помним формулу, но что подавать на вход конкретной функции? В pytorch дела обстоят так:
- NLL ожидает на вход логарифмы вероятностей (logsoftmax)
- CE ожидает на вход сырые логиты (без sm и lsm)
LogSoftmax можно применять повторно, ничего не сломается)
Так что правильный вариант (FC, LSM, NLL) и окнорм (FC, LSM, CE).
Бтв, гадать как правильно не надо! Разберитесь с математикой и документацией по слою :)
попробуйте что будет если сделать неправильно
Тред #3
Пятница
Неделька выдалась тяжелой, попробуем наверстать.
Все говорят, что BatchNorm -- это хорошо, но давайте обсудим)
Предположим, речь идет про картинки, на вход в BN приходит тензор [bs, channels, height, width].
Сколько в BN обучаемых параметров?
🤔
12.8% 0🤔
8.8% channels🤔
57.6% 2 * channels🤔
20.8% bs * channelsВ каком порядке правильно-то размещать BN и остальные слои?
🤔
67.5% Conv -> BN -> Activation🤔
32.5% Conv -> Activation -> BNСуббота
Во времена сигмоид (когда только самые математики использовали 1.72 tanh 2x/3) проблема была простой: функции активации с насыщением душили сигналы и градиенты. Этот момент полечился с помощью *ReLU, но градиенты продолжали взрываться и тухнуть.
Современные фреймворки удобны не только тем, что дают удобные примитивы: в них используются отличные дефолтные параметры. Мы особо не заморачиваемся с инициализацией когда учим с нуля резнет.
Между тем, вопрос об инициализации все еще активно пересматривается.
Удобной эвристикой для построения архитектур, инициализацией весов и нормализации входных данных можно считать следующее соглашение:
пусть в промежуточных тензорах соблюдается x.mean = 0, x.std =1.
Исходя из подобных соображений инициализируются веса
(см arxiv.org/abs/1502.01852)
Важный момент: E[x], Var[x] - не обучаемые параметры!
gamma и beta призваны восстанавливать параметры распределения, если это нужно. gamma инициализируется единичками, beta -- нулями.
В pytorch их можно выключать.
Что делать, если инициализация где-то оказалась неудачной? Можно физически уменьшить влияние и отнормировать промежуточные значения.
В этом нам помогают *Norm-слои:
x - это входной тензор, средние считаются по некоторым осям, gamma и beta - обучаемые параметры.
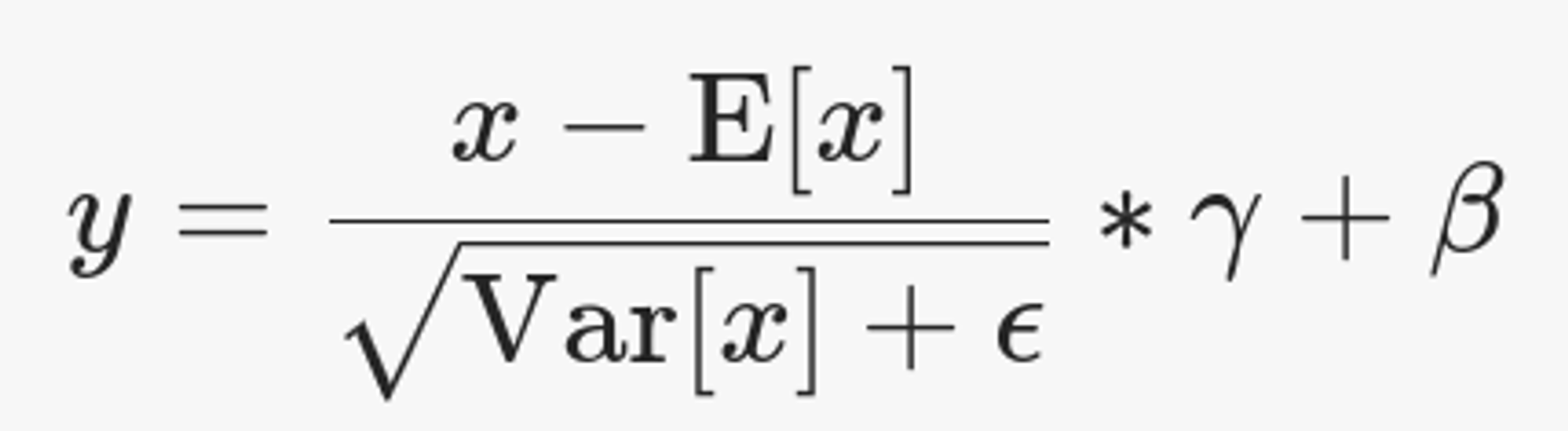
Так что если на вход BN приезжает тензор размеров [bs, ch, h, w], то усреднения делаются по [bs, h, w]. Они используются как есть и добавляются к двум векторам размера [channels].
Кроме статистик есть два обучаемых вектора размеров [channels].
Решение простое: во время тренировки в формуле используем честное средние по нужным осям (и градиенты на них пропускаем честно), а для инференса воспользуемся накопленными усредненными статистиками. В pytorch это поведение переключается методами: model.train(), model.eval().
Если говорить про BN, E[x], Var[x] считаются по всем размерностям кроме каналов. Это порождает вопросы и проблемы:
- семплы в батче теперь взаимодействуют
- что делать во время инференса? ведь там в батч может придти что угодно => это будет влиять на результат
Conv + BN (в eval-режиме) можно зафьюзить, т.е. заменить на один Conv-слой, просто пересчитав для него ядра.
Алсо, gamma и beta выглядят многообещающе для закидывания в сеть дополнительных фичей: например статистик из другой сети/с другой картинки (см AdaIN). А еще можно добавить пространственных осей и подсыпать в сеть сегментационных данных (см SPADE).
Тред #4
Понедельник
Неделька выдалась тяжелой, попробуем наверстать. Все говорят, что BatchNorm -- это хорошо, но давайте обсудим) Предположим, речь идет про картинки, на вход в BN приходит тензор [bs, channels, height, width]. Сколько в BN обучаемых параметров?
Неделя кончилась, пора отдавать аккаунт.
Всем спасибо за внимание, было интересно попробовать:)
Было три тредика:
- немного про pytorch [twitter.com/dsunderhood/st…]
- про сетки в проде [twitter.com/dsunderhood/st…]
- про BN [twitter.com/dsunderhood/st…]
Всем продуктивной недели!