

Неделька выдалась тяжелой, попробуем наверстать.
Все говорят, что BatchNorm -- это хорошо, но давайте обсудим)
Предположим, речь идет про картинки, на вход в BN приходит тензор [bs, channels, height, width].
Сколько в BN обучаемых параметров?
🤔
12.8% 0🤔
8.8% channels🤔
57.6% 2 * channels🤔
20.8% bs * channelsВ каком порядке правильно-то размещать BN и остальные слои?
🤔
67.5% Conv -> BN -> Activation🤔
32.5% Conv -> Activation -> BNВо времена сигмоид (когда только самые математики использовали 1.72 tanh 2x/3) проблема была простой: функции активации с насыщением душили сигналы и градиенты. Этот момент полечился с помощью *ReLU, но градиенты продолжали взрываться и тухнуть.
Современные фреймворки удобны не только тем, что дают удобные примитивы: в них используются отличные дефолтные параметры. Мы особо не заморачиваемся с инициализацией когда учим с нуля резнет.
Между тем, вопрос об инициализации все еще активно пересматривается.
Удобной эвристикой для построения архитектур, инициализацией весов и нормализации входных данных можно считать следующее соглашение:
пусть в промежуточных тензорах соблюдается x.mean = 0, x.std =1.
Исходя из подобных соображений инициализируются веса
(см arxiv.org/abs/1502.01852)
Важный момент: E[x], Var[x] - не обучаемые параметры!
gamma и beta призваны восстанавливать параметры распределения, если это нужно. gamma инициализируется единичками, beta -- нулями.
В pytorch их можно выключать.
Что делать, если инициализация где-то оказалась неудачной? Можно физически уменьшить влияние и отнормировать промежуточные значения.
В этом нам помогают *Norm-слои:
x - это входной тензор, средние считаются по некоторым осям, gamma и beta - обучаемые параметры.
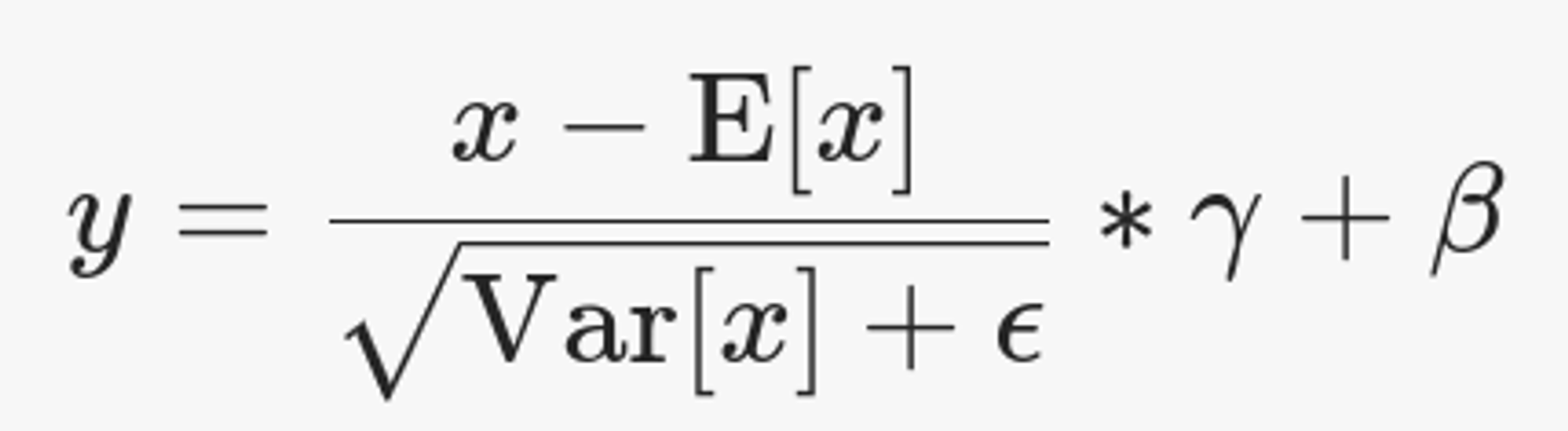
Так что если на вход BN приезжает тензор размеров [bs, ch, h, w], то усреднения делаются по [bs, h, w]. Они используются как есть и добавляются к двум векторам размера [channels].
Кроме статистик есть два обучаемых вектора размеров [channels].
Решение простое: во время тренировки в формуле используем честное средние по нужным осям (и градиенты на них пропускаем честно), а для инференса воспользуемся накопленными усредненными статистиками. В pytorch это поведение переключается методами: model.train(), model.eval().
Если говорить про BN, E[x], Var[x] считаются по всем размерностям кроме каналов. Это порождает вопросы и проблемы:
- семплы в батче теперь взаимодействуют
- что делать во время инференса? ведь там в батч может придти что угодно => это будет влиять на результат
Conv + BN (в eval-режиме) можно зафьюзить, т.е. заменить на один Conv-слой, просто пересчитав для него ядра.
Алсо, gamma и beta выглядят многообещающе для закидывания в сеть дополнительных фичей: например статистик из другой сети/с другой картинки (см AdaIN). А еще можно добавить пространственных осей и подсыпать в сеть сегментационных данных (см SPADE).