В основном на курсах по ML/DL речь идет про обучение моделек. MVP делается на слегка подправленной кодовой базе с питоном и фласками.
Моделька создается кодом, в нее подгружаются веса из чекпоинта.
Если проект не умер на первых порах, дальше пойдет эволюция.
Пояснения к опросам я выложу завтра. А пока поговорим про сетки в проде.
В какой прод вы катите ML/DL модельки?
🤔
60.5% сервера🤔
6.7% мобилки🤔
5.9% браузер/компы юзеров🤔
26.9% прода нетЛюди прибывают. Модельки усложняются.
Появляется легаси (и это нормально!).
Вы начинаете страдать от обратной совместимости, а она от вас, катить становится сложнее, в коде копятся валенки (скажем другой метод ресайза картинок будет стоить вам процентов acc@1 на imagenet).
Давайте просто договоримся сериализовать вычислительный граф с весами и передавать его!
Если речь идет про классификацию картинок произвольного размера, например договариваемся кидать на вход картинки uint8 [1, 3, ?, ?], ресайз и прочий препроцессинг делать в графе...
Разумным решением будет разделить окружение на тренировочное и продовое, а затем разделить кодовую базу.
Как меньше страдать от синхронизации кода моделек и процессингов в разных окружениях?
🤔
13.3% git submodule🤔
46.7% Переписать все на плюсах!🤔
20.0% Сохранять в ckpt код🤔
20.0% Свой вариант в комментыСложность никуда не исчезает: код для экспорта моделек может стать достаточно интересным, но он лежит рядом с трейновой кодовой базой, выполняется редко, возможно даже в ручном режиме.
А вот код для запуска модели максимально простой и может быть отчужден.
моделька пусть возвращает два вектора: с названиями классов и вероятностями top5 ответов.
Пример условный, но смысл в том, чтобы коде инференса было минимальное количество вычислений.
Про скорость.
Переписать все на плюсах и полететь - это очень распространенная фантазия, но обязательно попробуйте!
Так-то питон не сильно замедляет применение моделек по сравнению с С++ API (если вычисления сложнее перемножения пары матричек).
от питона в проде (и гигабайтов библиотек) и использовать специализированные движки для инференса. Сейчас их стало достаточно много, но основных всего ничего:
- tf/torchscript
- tflite для мобилок
- ONNX - (не только для DL-моделек)
- TensorRT (GPU)
- OpenVINO (Intel CPU)
Понятное дело, что в реальности у нас могу быть другие потребности: например обрабатывать картинки батчами. Значит их придется ресайзить во время применения и в проде снова появится код с вычислениями.
Если все вычисления делать в вычислительном графе мы сможем отказаться ...
Может дать больше качества, чем учить маленькую модель на том же датасете.
В чем поинт:
- большая модель может сгладить ошибки и неполноту разметки
- можно учиться на тонне неразмеченных данных
- можно сменить тип модельки авторегрессионную в простую feed-forward
Когда код запуска отлажен и запрофилирован, а скорости мало, приходится делать что-то с модельками.
Обычно говорят про дистилляцию, квантование и прунинг.
Дистилляция модельки - это обучение маленькой модельки на выходах большой.
через сетку прогоняется калибровочный набор данных, для каждого слоя выбирается оптимальный zero-point и scale. Вместо одной fp-операции с fp-входами-выходами получается три операции: quantizing -> q_op -> dequantizing.
Квантование - классная штука. Нам нужны float point-числа чтобы работал градиентный спуск, часто при переходе к fp16 возникают проблемы со сходимостью обучения.
Но во время инференса точность не особо нужна.
Сейчас популярно квантование в int8, после тренировки:
Подряд идущие вспомогательные операции склеиваются и в идеале весь граф состоит из квантованных операций.
Подводные камни простые:
- не все получается конвертировать (и выигрыш в одном месте теряется на лишних конвертациях)
- портится качество
Прунинг - зануление весов. Обычно просто по гистограмме значений зануляются маленькие по модулю числа.
Из неочевидного: чтобы неупорядоченный прунинг дал прирост скорости нужны спарсные операции и занулять значительную долю весов.
В добавок к этим трем понятным вариантам есть еще один чуть более глубокий: инференсный граф может отличаться от тренировочного.
Когда речь идет про картиночные сетки мы так часто и делаем не задумываясь: BN в валидационном режиме превращается в простое аффинное преобразование..
Так что для скорости нужно делать структурный прунинг: выбрасывать целые каналы и слои.
На прунинг можно смотреть как на регуляризацию, в такой постановке он тесно связан с гипотезой счастливых билетов, но это уже не про оптимизацию инференса)
Красивую идею предлагают в недавней статье RepVGG: давайте учить ResNet, а инферить VGG.
Пояснение: в резнетах хорошо текут градиенты, это позволяет тренить 100+ слойные слойки.
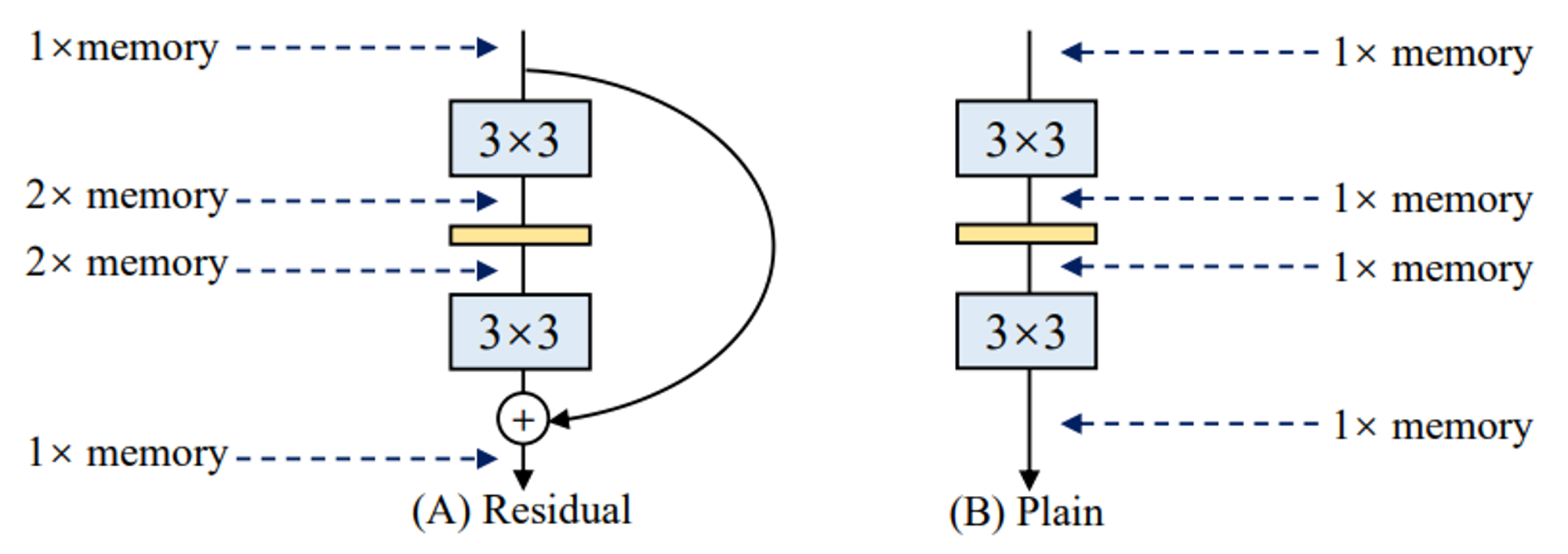
VGG в свою очередь добры к потреблению памяти:...
отсутствие срезок (skip-connections) позволяет тратить сильно меньше памяти, но тренировать глубокие VGG-like сети тяжело (градиенты и сигналы затухают).
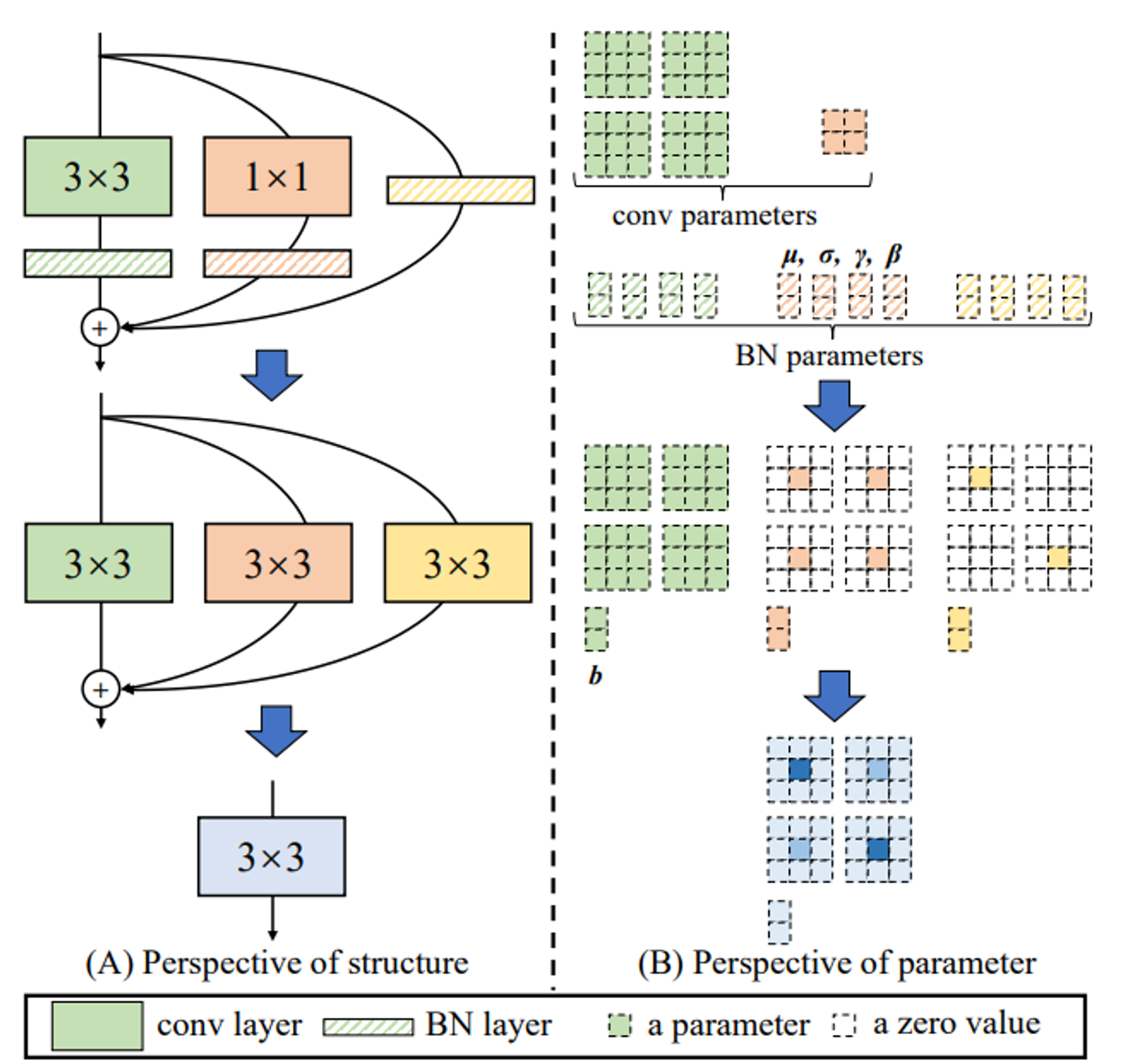
Предлагается сделать математический трюк: изменить ResBlock так чтобы его можно было конвертировать в Conv + Activation с идентичными ответами.
Для этого делаем ResBlock тощим:
- три ветки вычислений
- Identity + BN
- Conv 1x1 + BN
- Conv 3x3 + BN
- ReLU после суммирования
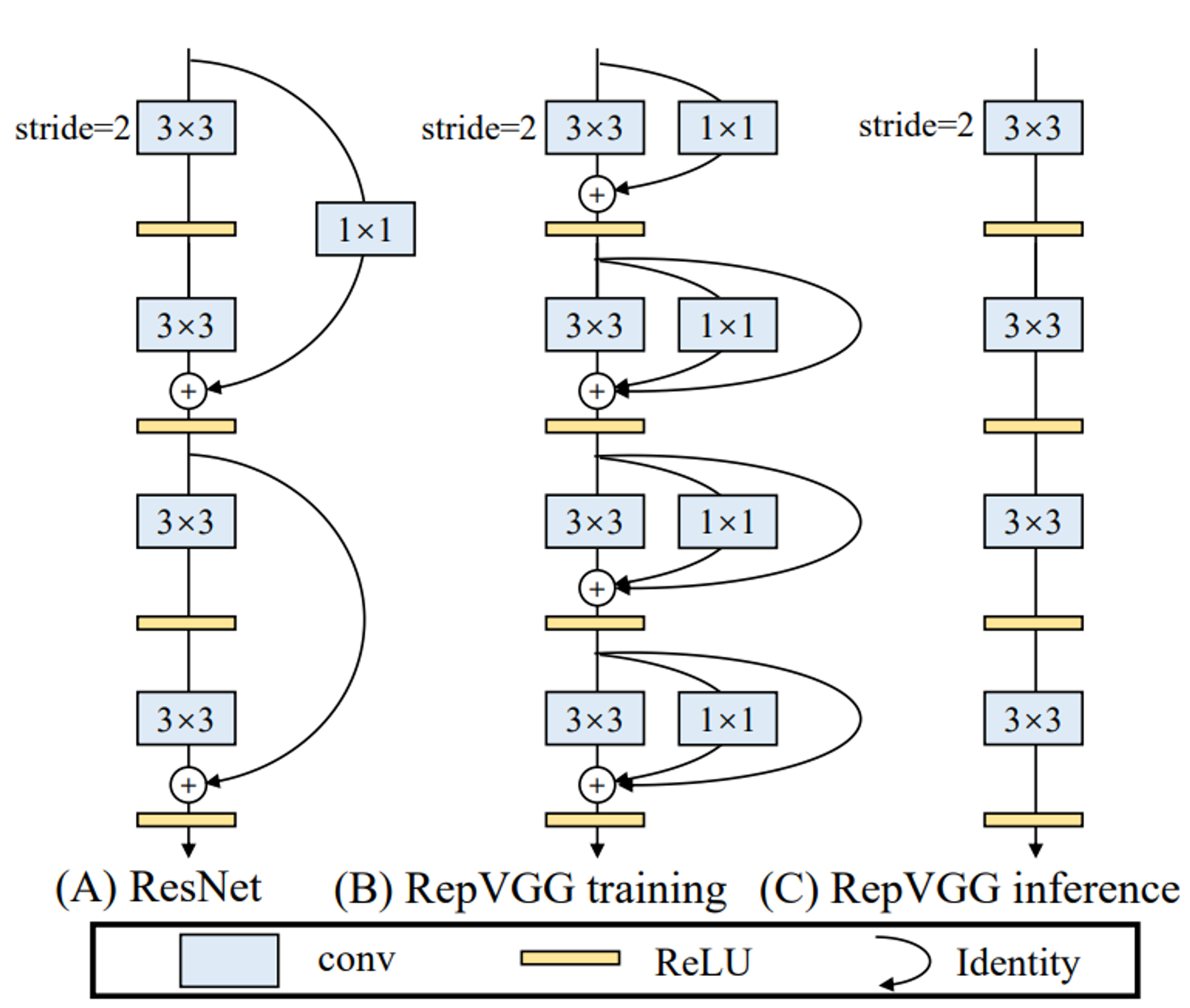
Так-то подобные работы делали и раньше, привожу эту как наиболее наглядную.
Статья в целом наталкивает на мысль что мы не очень-то хорошо умеем инициализировать и оптимизировать модельки.
Ссылочка на всякий случай: arxiv.org/abs/2101.03697
Конвертация в VGG-блок делается так:
- распячиваем Identity и Conv 1x1 в Conv 3x3 (ядра с нулями).
- BN-eval заносим в свертку (ядра умножаем на мультипликативную поправку, аддитивную в bias)
- складываем ядра -> получается одна свертка 3x3
- ...
- ответы сети идентичны исходным!