

Что лучше подходит DS команде — скрам или канбан?
Давайте разбираться со скрамом. Он очень популярен в разработке ПО:
Спринт считается успешным, если команда добилась цели спринта. Она обеспечивает фокус на результате. Грубо говоря, есть чем похвастаться каждый спринт
Пользовательские истории начинаются в спринте и доделываются внутри спринта до конца. Это очень упрощает планирование. Пользовательская история разработана, протестирована, баги найдены, исправлены и закрыты, продукт задеплоен на stage или prod
Короткий Time to Market. От момента старта разработки до поставки проходит один спринт, в большинстве команд это 2 недели
Если мы фокусируемся на доделывании до конца историй в спринте, то мы не тянем в следующий спринт доделки и баги с прошлых спринтов. Тогда все прозрачно и понятно!
К сожалению в большинстве DS скрам плохом применим:
Основная проблема: гипотезу практически невозможно доделать до конца (валидировать) в течении спринта. Для валидации гипотезы нужно от нескольких недель до нескольких месяцев.
Второе важное отличие: Data Science — discovery process. Каждая гипотеза может провалится и относительно небольшой процент гипотез доезжает до прода и приносит ценность.
Проблемы Скрама в DS:
Никакой разумной цели спринта поставить не получается. Даже если вдруг мы формулируем цель, достичь ее к концу спринта практически невозможно
В конце спринта есть куча недоделанной работы, которая в конце просто переносится на следующий спринт
Внутри спринта из-за discovery-характера DS проектов может случиться нечто, что полностью уничтожает смысл доделывать спринт до конца
По-сути, в DS проектах спринт превращается в регулярную отбивку времени, просто обозначает частоту встреч команды по планированию.
В Канбан явным образом визуализируется передвижение гипотез по их жизненному циклу.
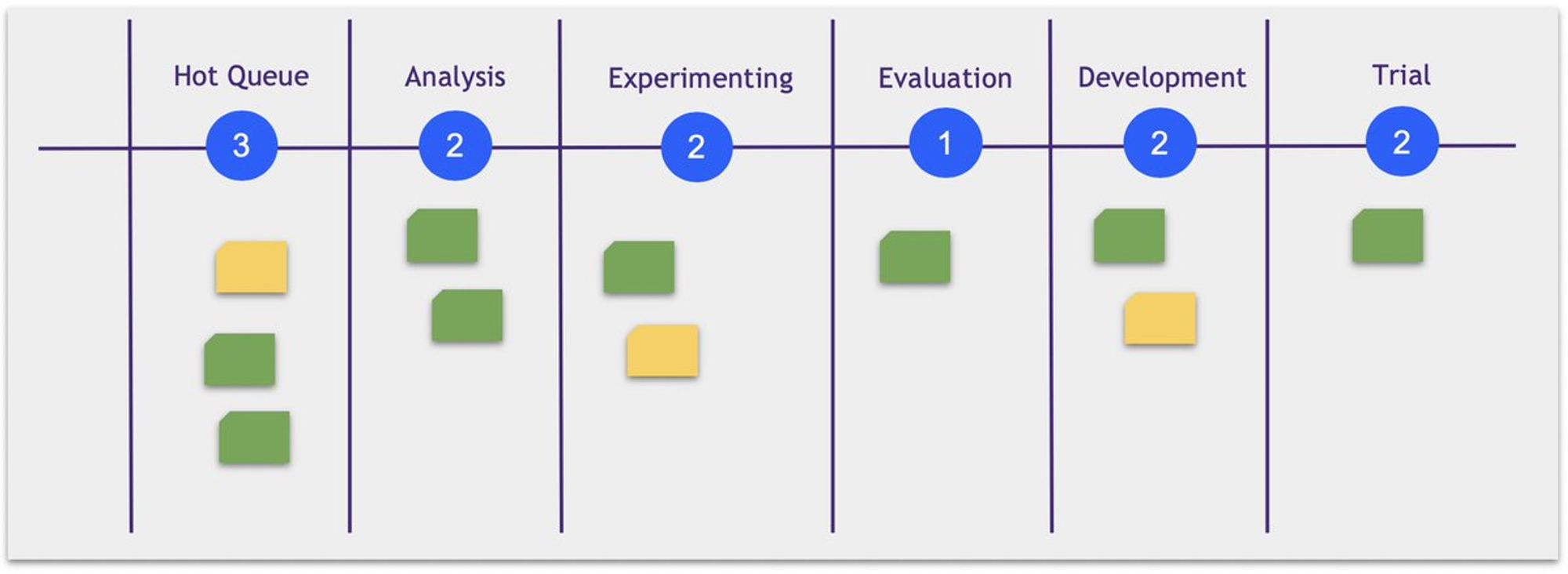
В большинстве случаев канбан обеспечивает больше прозрачности работы над гипотезами и упрощает планирование