Архив недели @zaleslaw
Понедельник
Добрый день, меня зовут Зиновьев Алексей, в миру @zaleslaw
Сейчас я работаю в JetBrains в команде Kotlin for Data Science, создаю DL/ML библиотеки на Kotlin; также несколько лет жизни я посвятил @ApacheIgnite разрабатывая фреймворк распределенного машинного обучения.
Семейный.
План на неделю следующий:
Биография (матфак ОмГУ->аспирантура->начало трудовой карьеры->рынок труда в небольшом городе)
ML на JVM, текущее состояние
SparkML/Ignite ML
Kotlin for Data Science
Tensorflow, кишки
Разное (работа на удаленке, взгляды на жизнь)
Сфера моих рабоче-научных интересов в 2020 году: TensorFlow Java/C/C++ API, расчет градиентов в TF/PyTorch, JAX, hyperparameter tuning methods и AutoML вообще, форматы хранения моделей ML/DL, CUDA, приближенные методы классического ML, распределённые ML алгоритмы.
Настроение для разговора с вами: ребята, я люблю ярких и умных и в меру дружелюбных людей, пишу сюда под ooolong чаем, немного устал к концу года от ковида и всего связанного с ним, пришел сюда, чтобы найти парочку единомышленников для дискуссий и познакомить вас с миром DS JVM
BioThread: Мне скоро 33 и я стал как-то спокойнее к славе, быстрым деньгами и выяснению какой язык программирования лучше и т.д.
Началась моя история с Math с того, что однажды осенним днем 1999 года мой сосед Димка не вышел гулять - он решал задачки для маткружка.
Что за кружок, что за линии и кружочки, кто такой Дырыхле, что за комбинационный взрыв, какие фальшивые монеты? В общем, упросил маму свозить меня в этот кружок и обеспечил себе "веселые субботы" под олимпиадными задачками на весь 5,6 и 7 классы.
В 2000 году мне удалось съездить в кировскую ЛМШ, и там на берегу реки Вятки меня укусил математический комар, вбросив в кровь теорию графов, конечные автоматы (общение с одной девятиклассницей) и linux (без него нельзя было открыть дома дискету с задачами)
Позднее, я попал в мат.школу 64 в городе Омске (удалось покинуть, ага) и там мне повезло с хорошим учителем физики - сухая алгебра и немые производные и интегралы заговорили и ожили, оказались применимы, а фантазийная геометрия Лобачевского затанцевала польку рядом с СТО
В Омской области в 2000-2020 существовало сразу несколько выездных школ для математиков: ЛАН Ноу Поиск, ШМИТ, ЛГМШ. С 2000 по 2010, сначала ребенком, потом преподом я провел в этой среде, питательной для ума и дружелюбной, позволявшей мириться с окружающим меня затхлым постсовком
В 2005 я поступил на матфак ОмГУ, где было все как у людей: матан, функан, тервер, методы оптимизаций, физра, программирование на Pascal (sic!) и дрянная еда в буфете, а также транслируемая всеми уверенность в богоизбранности математиков
Базу нам давали хорошо отменные динозавры с корнями из новосибирского академгородка 70-ых (отсюда у меня огромное восхищение ТЕМ САМЫМ академом). Попытки научить нас программировать были вялыми и нерешительными, а айтишники тогда еще не ходили читать спецкурсы во имя хантинга
Мои научные интересы были странными и немного не матчились на увлечение моей профильной кафедры теорией расписаний и линейным программированием, меня откровенно перекидывали от научника к научнику, а я как теленок долбился, не понимая основ взаимодействия в научной среде.
Начал я с построения дорожных графов наиболее оптимальным способом, перейдя попутно к bilevel programming с нелинейными нечеткими ограничениями, способам ее решения и эвристикам на основе монте-карло и генетических алгоритмов. Подготовка датасета с дорожным графом привела меня в
Яндекс и Mail, которые любезно дали доступ к некоторым датасетам, в научные школы, где такие темы и алгоритмы обсуждались, а затем в Одноклассники, в их эпоху активного шаринга социального графа и контестов. Но чтобы это обработать пришлось ковырять Hadoop и ранний Spark
Я поступил в аспирантуру, но статьи не удались, на английском я не умел, дальше Урала не посылал, а в одном из журналов случилась дурнопахнущая история, когда мою статью завернул рецензент, а на следующий год его сын напечатался в этом же журнале с похожим подходом к решению.
В 2014 телёнок закончил бодаться с научным дубом и решил переквалифироваться в управдомы, полностью уйдя в индустрию развлечений на Java/Data Engineering, уехав в солнечный Петербург.
Final: В 2020 году я с удивлением обнаружил засилье тематики bilivel programming, ml, нечетких уравнений на конференциях, где выступали мои бывшие научные коллеги. Приятно быть первопроходцем в Сибири. Зовут к ним выступать.
CareerThread: свои первые деньги я заработал вкопав ракету в одном омском дворе. Потом на утреннике для школьников. Если первое мне показалось тяжелым, то второе чуток понравилось, но не костюме индейца. Хотелось заработать головой, но в 2006 в Омске было мало junior-вакансий. 0

Один из преподов, не веривших в нас, рекомендовал всем не сдавшим зачет по матлогике идти в 1С. Хоть зачет я и сдал, в 1С я пошёл. Шел 2007, там брали молодых и шустрых, а программировать на русском диалекте VB казалось лайфхаком.
С самого начала нужно было писать много SQL, строить отчеты, графики, общаться с реальным пользователями, делать выгрузки в XML, цеплять dll, делать UI. Скорость разработки на этом конструкторе необычайно высока. После нее downgrade в мир Java/MySQL/JQuery был очень болезненным.
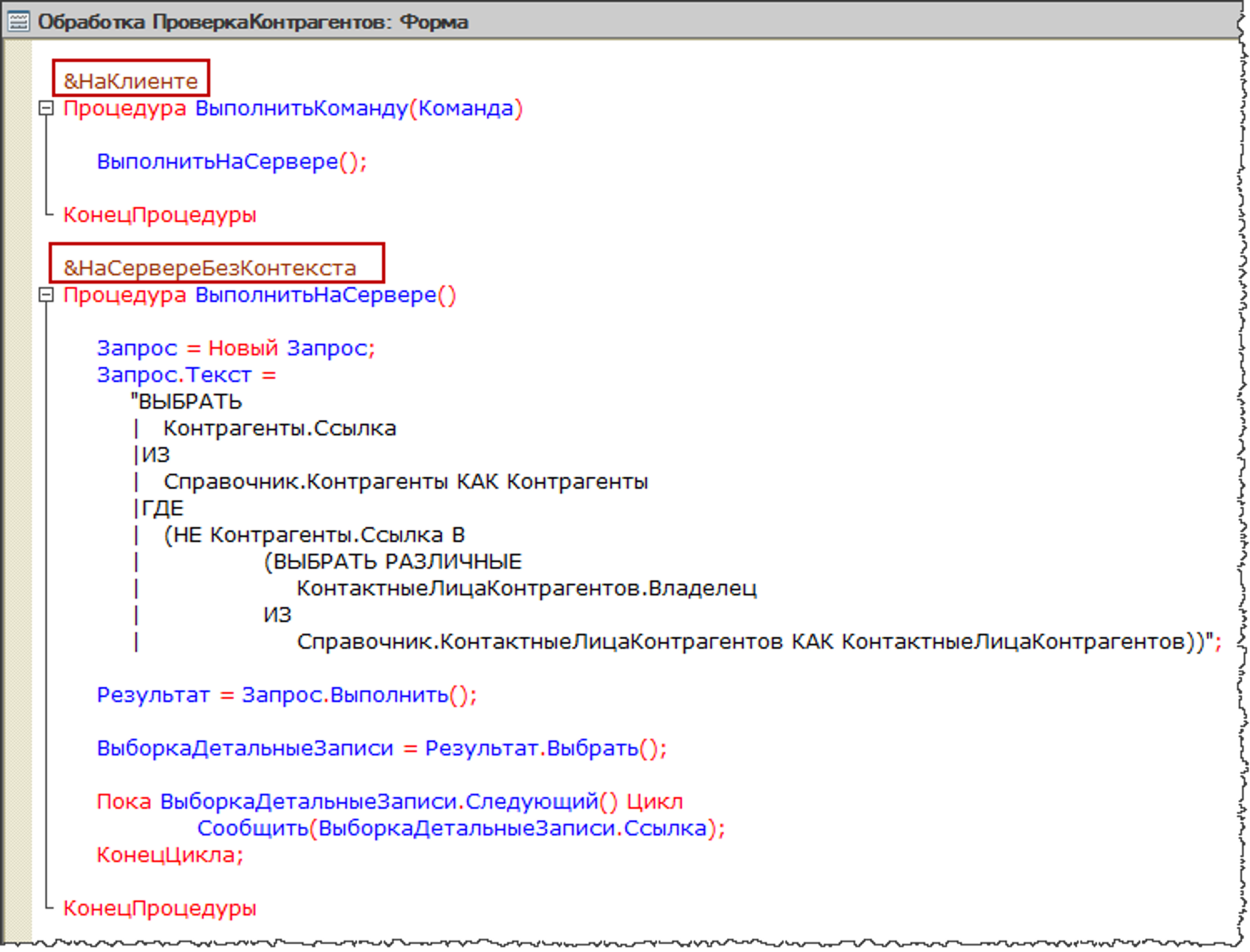
Еще в 2009 (11 лет назад) мне платили деньги за: мат.статистику, кластерный анализ, поиск ассоциаций и дерево решений.
Тренеры и модели шли в 1С, я готовил для них данные и встраивал в отчеты. Тогда это называлось "анализ данных".

Однако для дорожных графов и генетических алгоритмов 1С была уже не столь удобна, поэтому в научной работе я переключился на низкоуровневую Java 1.4 (учил по книжке, в которой не было даже дженериков). Со временем в городе появились первые конторы с вакансиями на Java и я перешёл
В 2012 году, имея за плечами большой опыт аналитики и разработки бэкендов, написания запросов на прекрасной 1С я окунулся в мир незаконченных фреймворков. В Java не было единого стандарта ни на что. По каждому поводу существовало 2 крупных фреймворка и 10 мелких. Spring был слаб
Мне как-то сразу повезло попасть в струю связанной с работой с набиравшим популярность @hadoop и такой ранней библиотекой распределенного машинного обучения, как @ApacheMahout (Spark появился позднее и во всех церквах звонили колокола в тот день)
На работе мне в руки текли проекты связанные с геоданными, анализом данных, развертыванием отчетности на основе OLAP-куба. О, MDX, о, богом забытый фреймворк Mondrian для их построения на java. Ніколи знову!
@dsunderhood Spring был слаб в 2012 году? Поясни плиз.
Поясни за Spring, спросили меня. Сейчас спрингом пугают питонистов в колыбели, а тогда был модный прогрессивный фреймворк (да и сейчас, конечно же) twitter.com/antonarhipov/s…
DSThread: К 2013 году стало ясно, что есть кластер Hadoop, а есть мат.методы в распределенной среде. И за первое первый мир уже готов платить, а за второе - пока не очень, но интересно именно второе, ведь там какая-никакая математика (к тому моменту я видел только KMeans/KNN)
У нас на работе возник кружок изучения DS (старое название ML), где мы в нерабочее время разбирали мат.методы: деревья, регрессии, метрические и прочее.
Смотрели подпольные материалы ШАД (которых тогда почти не было в открытом доступе)
У нас на работе возник кружок изучения DS (старое название ML), где мы в нерабочее время разбирали мат.методы: деревья, регрессии, метрические и прочее. Смотрели подпольные материалы ШАД (которых тогда почти не было в открытом доступе)
Кстати, о "воронцовских курсах" пост - zaleslaw.medium.com/24-%D0%BB%D0%B… twitter.com/dsunderhood/st…
Занимаясь машинным обучением в России, редкий человек избежал искушения обучиться базовым навыкам посредством знаменитого курса от Воронцова. Многие пытались использовать его как первый и единственный доступный материал и убегали в страхе, раздавленные уже первой лекцией.
Те из многих, кто имел достаточную математическую подготовку и небольшой практический опыт боготворили лекции как единственное верное учение и подход к подаче материала.
Кто-то, имеющий большой практический опыт и некоторый опыт преподавания осуждал сугубую академичность изложения и отсутствие практических примеров (видимо, на scikit-learn).
Но практически все, с кем я обсуждал прохождение этого курса, сходятся в том, что существует такое фундаментальное явление, как два семестра машобуча, мимо которых пройти мимо сложно и влияние на индустрию и методику преподавания оказано огромное.
Об этом курсе заговорили в моем окружении на рубеже 2012–2013 годов в связи с ростом популярности ШАДа в узких кругах выпускников матфака ОмГУ/НГУ. Изначально звучала лишь название курса и “дикая сложность” оного, без фамилии создателя и изредка проскальзывало суждение,
что наилучшая информация по ML может быть найдена на machinelearning.ru, вокруг которого и будет формироваться русское сообщество ученых и практиков машобуча.
Мои рецензии на лекции первого и второго семестра тут
zaleslaw.medium.com/%D1%80%D0%B5%D…
Второй семестр zaleslaw.medium.com/%D1%80%D0%B5%D…
Контора, где я работал, активно пыталась войти на рынок DS/ML/BigData, делала бэки для стартапов, где уже появлялись простые модели на ансамблях деревьев, Markov chain для кое-чего и просто матрицы с весами, которые как-то вычислялись поверх данных.
Одновременно я начал смотреть в сторону консалтинга, но там, в 2014, ML-ные деньги попадались только в порно. Порно, о сколько в этом слове для сердца ML-щика слилось, коль много там отозвалось. Питер - столица порно-ML стартапов приняла меня в свои объятия.
@dsunderhood Зачем вкапывать ракету на утреннике для школьников в костюме индейца?
Слушайте, это же Омск. У меня мама работала на заводе, где делают ракеты, их было так много, что их приплетали всюду, даже на утренниках модно было быть в костюме ракеты:) twitter.com/varpa89/status…
DEThread: Перебравшись в СПб я уже вплотную занялся прокачкой навыков DE, пытаясь устроиться чистым DS. На чистого DS брали только на мало денег, поэтому я раз за разом выбирал DE проекты (presale/прототипы) и рос очень быстро, играя роль FullStackBigData
DEThread: Перебравшись в СПб я уже вплотную занялся прокачкой навыков DE, пытаясь устроиться чистым DS. На чистого DS брали только на мало денег, поэтому я раз за разом выбирал DE проекты (presale/прототипы) и рос очень быстро, играя роль FullStackBigData
Из той эпохи сохранилась пара выступлений про DS/BigData на Java
youtube.com/watch?v=dXKs26… twitter.com/dsunderhood/st…
Одновременно пошел просто огромный поток джавистов, дотнетчиков, database administrators, бегущих из старых рынков в новый сияющий мир "BigData: Hadoop, Hive, Spark". В EPAM мы открыли менторинг (учеба с куратором) по BigData, через который прошло 300+ человек в 16-18 годах
Одновременно пошел просто огромный поток джавистов, дотнетчиков, database administrators, бегущих из старых рынков в новый сияющий мир "BigData: Hadoop, Hive, Spark". В EPAM мы открыли менторинг (учеба с куратором) по BigData, через который прошло 300+ человек в 16-18 годах
Я выступал с кусочками тренингов на конференциях, например про Hadoop youtube.com/watch?v=TtsBOB… twitter.com/dsunderhood/st…
Мне повезло работать с очень крутыми архитекторами и большим количеством досконально изучающих фреймворки людей. Кишки Hadoop - это нечто. Именно тогда и началось мое погружение в недра и уход в библиотекописательство. Ты глядишь - и понимаешь, что можешь говнякать не хуже. 100%
Люди на тренингах, особенно на внешних любили задавать такие заковыристые вопросы, рассказывать про такие кейсы, показывать такие вещи, что волосы становились дыбом, а опыт конвертировался в консалтинг. Но тянуло меня от java-dependecy hell больше к проблемам с форматами моделей
Потом мне попалась интересная задача с Kafka + Online Learning и я иначе взглянул на классический ML и давно известные модели под углом: кто легко апдейтается, а кто нет. Кто профнепригоден, а с кем мы еще поговорим. А кто может лечь на распределенный кластер...
Потом мне попалась интересная задача с Kafka + Online Learning и я иначе взглянул на классический ML и давно известные модели под углом: кто легко апдейтается, а кто нет. Кто профнепригоден, а с кем мы еще поговорим. А кто может лечь на распределенный кластер...
Из той эпохи есть одно добротное выступление на конференции "Kafka льёт, а Spark разгребает! (при помощи Structured Streaming)" youtube.com/watch?v=_rmuD6… twitter.com/dsunderhood/st…
На пути в JetBrains: в 2017 году я обратил внимание на статью на хабре habr.com/ru/company/gri…
Там ребята из компании @gridgain сделали копию @ApacheMahout поверх in-memory database @ApacheIgnite
Потом мне удалось с ними пообщаться вживую (помогли старые EPAM-вские связи)
Оказалось они только стартуют и челленджей непочатый край. Я начал работу над OpenSource проектом с баг-фикса в алгоритме перемножения распределённых блочных матриц и понеслось. 102 коммита, 300k+ строк кода, 15 моделей, PMC проекта.
Чем больше я пилил распределенный ML, читал статьи, писал свои, изучал код scikit-learn/Spark/dlib/tensorflow, тем больше крепло ощущение, что это мое. В какой-то момент случилась магия:
Летом 2019 я начал прототипировать ML-либу на Java, но поглядел на Kotlin, составил roadmap и начал двигаться потихоньку (в приватной репе). И через какое-то время мне написали HR JetBrains и позвали в новую команду Kotlin for Data Science. Это был идеально. Мысли материальны.
Трудовую биографию изложил, завтра продолжим.
Всем приятного вечера! Завтра день ML на JVM
Вторник
Итак, ML/DL/DS на JVM (Java/Scala/Kotlin). Использовали ли вы хоть какую-то java библиотеку, чтобы открыть знание в данных или выучить его?
Известно ли вам, что эти @ProjectJupyter поддерживает в ноутбуках не только #python, но и #java и #kotlin ?
Вы знаете, что numpy/tensorflow/pytorch - у них внутри не Python? Прям сразу? Про Spark, наверное слышали тоже, что там не Python. Т.е. никакого первородного или перфоманс права у Python как такого нет?
Вчера я уже упоминал @ApacheMahout, этот тред посвящаю ему: В начале 10-ых с ним многие связывали надежды и очень редко прод. Всем казалось, что если KMeans, то сразу на всех данных (на целых 100 ГБ, например). Он был написан на java для работы в связке с ранним Hadoop.
Из вкусного: там были кластеризации (distributed clustering implementations: k-Means, Fuzzy k-
Means, Dirchlet, Mean-Shift and Canopy) и рекомендательные системы, те самые, с триплетами, вошедшие потом почти без изменений в @ApacheSpark
К сожалению, не все ML алгоритмы можно легко разложить в distributed среду (об этом мы поговорим позднее) и @ApacheMahout надорвался еще 7 лет назад - люди потратили тонну сил, чтобы сделать что-то достойное at the top of @hadoop. В итоге, много осталось за бортом
На волне хайпа про него написали несколько книг и старые перцы до сих пор его вспоминают. Сами создатели в какой-то момент устали от всего - переписали ядро на Scala, сделали либу линейной алгебры, выкинули алгоритмы. Теперь это слабо кому нужное нечто, но вдруг
@dsunderhood Не наверное, а самый настоящий цэ плюс плюс
С++сите! twitter.com/Alexwortega1/s…
С++сите! twitter.com/Alexwortega1/s…
Хотел обыграть слово из ника "Спасите", а вышло, как вышло. Мне стало стыдно. twitter.com/dsunderhood/st…
@dsunderhood Numpy точно благодаря C работает, насчёт остальных не знаю.
Скоро дойдем до кишочков TF, не переключайтесь! twitter.com/kouandique/sta…
Тред ламповости: каждый начинающий любитель java, которому надо немного статистики или кластеризации, значет, что есть такая commons.apache.org/proper/commons…
И действительно, бодрые старцы, которые ее делали, лихо впилили years ago линейную регрессию и kmeans.
@dsunderhood В numpy вообще фортран внутри имеется
По транзитивным зависимостям мы можем уйти далеко! twitter.com/YevhenKolodko/…
Мыши колются, но продолжают есть кактус. Иногда встречаю либы, написанные как расширение к ней. Эдакий scikit-learn, который не взлетел, т.к. попытался стать всем.
Из еще лампового - новозеландская студия для DS/ML/MLOps и копирования кода на java - Weka
cs.waikato.ac.nz/ml/weka/
DataSource source = new DataSource("/some/where/data.arff");
Instances data = source.getDataSet();
J48 tree = new J48();
Evaluation eval = new Evaluation(data)
@dsunderhood @zaleslaw @ApacheIgnite Хотелось бы увидеть разбор экосистемы Kotlin для Data Science с аналогами билиотек для Python. Так же хотелось бы увидеть, что из open source и не очень, Jetbrains создала на Kotlin для Data Science. Какую ставку Jetbrains делает на Kotlin в Data Science?
Обязательно будет, в свое время с интересными новостями. Однако без отрыва от JVM экосистемы это не имеет смысла, посему, медленно движемся к цели! twitter.com/dmitrybalabka/…
При этом Weka - живее всех живых, развивается, там имеется типичный Java GUI, на котором вы духе концепции No Code можете накидать Pipeline (и могли это еще в 2014, например)
Кстати, если кому интересен датасаенс — люто рекомендую подписаться на этот аккаунт. Много интересного можно узнать. twitter.com/dsunderhood/st…
Тут действительно собираются разные люди и мнения, и временами хочется перечитывать чьи-то треды. Спасибо @tiulpin за организацию, кстати twitter.com/kouandique/sta…
@dsunderhood Ну Спарк это всегда была Скала, но все появилось благодаря Джаве.
Просто, ввиду популярности #pyspark уже сталкиваюсь с людьми, которые не в курсе и удивляются exceptions с executors или ошибке сериализации twitter.com/nordilion/stat…
Самой крупной либой классического ML в JVM мире я считаю Smile haifengl.github.io (погодите про H2O, не гоните). Это прямой аналог scikit-learn в JVM-мире. Но есть одно но. Текст лицензии.
github.com/haifengl/smile…
Мне он не подходит, например.
Либа хорошая, для research, для студентов, для чего-то не финального. Но в финале вам придется платить по счетам, в прямом смысле. Читайте лицензии, конечно.
Такие лицензии еще опасны тем, что протекают в ваш OSS продукт, заражая его.
@dsunderhood Я как изначальный джавист вообще был дико во всем этом разочарован, когда пришел в DS из розового мира семейства Apache. Python везде python и теперь это де-юрре стандарт. До сих пор его полноценно не принял. Нахожу отдушину в R/Julia.
Крик души, обнимемся брат. Знаешь, я как-то успокоился. Ну Python, ну ладно, пусть перемалывает души, а мы по тылам побольше нащучим:) twitter.com/nordilion/stat…
Smile одна из немногих либ, которая имеет API сразу на Scala/Clojure/Java/Kotlin.
Исходный код чистый, но плоходокументированный, читается и дебажится легко.
Также - из хорошего, есть нормальная визуализация
Тред визуализации: С ней на JVM в целом не так бохато как в Python в силу безумного заигрывания с AWT/SWING/JavaFX и попыток делать это централизованно, через обком партии.
Одной из либ, которая мне зашла пару лет назад я считаю github.com/PatMartin/Dex
Без d3js не обошлось

Еще одна либа для раскладки и визуализации графов - @Gephi, всплывает то тут, то там. Я общался с создателем этой либы в одной уральской выездной школы - талантливый парень из Франции, без ума от графов. Кейс у меня был простой - есть БД с графом, надо разложить красиво.
Типичный Workbench с коннекторами к разным источникам данных и дальше мир красоты!

Также в экосистеме @TheASF есть свои собственные ноутбуки, которые весьма недурны собой, имеют удобные коннекторы к куче тулов из DataEngineering и кучу языков c элементами визуализации графиков, графов, диаграмм и карт
Квадратно-гнездовой тред: Дальше возникает резонный вопрос, ну ок. Где, я вас спрашиваю, ДАТАФРЕЙМЫ. Хде PANDAS? Хде шустрый и быстрый кирпич и основа сущего - аналог numpy.
А они есть, их делали неоднократно, но почему-то не летит ежик по небу.
На самом деле, надо понимать, что большинство Java-разработчиков знают SQL. Наш Pandas - это SQL. Вы не поверите, как просто на нем делать все то, что делается несколькими вызовами команд в Pandas. А то, что не сразу, пишется в какие-то кастомные функции на PL/SQL и алга!
Ну ок, к нам приходят люди и говорят, хочу месить таблички в коде. Так у нас есть @Hibernate c 3 или 4 видами API и 1001 попытка сделать SQL в коде (они есть в каждом языке, проверьте).
Хорошо, если надо прям, чтобы уже похоже на pandas, но идиоматично к языкам, то вот есть на java (но 500 звезд всего) github.com/cardillo/joine…
Еще и GPL3. Народ сразу отходит в сторону.
Под апачевой лицензией лежит довольно популярная библиотека github.com/jtablesaw/tabl… (2.5k звезд), которая неплохо интегрируется с выше упомянутым Smile.
Мне она в свое время немного не вкатила, но я в целом не фанат табличек в коде.
В Kotlin, где DS только зарождается и пытается идти своим путем (используя мощь Kotlin DSL и проча) есть вот такая либа github.com/holgerbrandl/k… сделанная с оглядкой на Pandas и dplyr (который мне, кстати, нравится).
Если говорить о numpy, то мы, в @jetbrains в прямом смысле его просто шоколадно обернули Котлином и он пошел жить своей жизнью в бэкендах некоторых крупных корпораций.
github.com/Kotlin/kotlin-…
Но там внутри остался кусочек Python, это нам не нравится и в идеале мы хотим аналог Numpy, но как Kotlin над C/C++ бэком для операций. Некое новое издание раннего эксперимента Viktor github.com/JetBrains-Rese…
Да и DataFrame мы тоже в отделе хотим сделать не слепой копией pandas, а подойти ближе к неким возможностям БД и иерархического анализа данных.
Лично я верю, что в следующем году мы порадуем JVM экосистему чем-то приятным.
@dsunderhood Блин, ну нифига же не правда. Не просто на SQL сделать то, что можно сделать в Pandas. Скорость разработки разная, качество кода получается разное, возможности дебага разные. Надеюсь, это был сарказм =(
Да нет, не сильно сарказм, безусловно, существует 10% магии pandas (и сахара странных функций) которые сложно повторить в SQL, но с подготовкой отчетов и данных для анализа опытные DB-щики и аналитики вполне успешно используют SQL. Вопрос привычки. twitter.com/loony_alien/st…
и да, мне приходилось решать задачу в обе стороны, SQL->dataframes/dataframes->SQL, они решаемы, обе
ML от Oracle (Tribuo) тред: пару месяцев назад @Oracle рассекретил ML либу написанную на Java, которую они с 2016 года использовали внутри.
github.com/oracle/tribuo
Мне очень нравится проделанная работа и свежий подход к пониманию того, что есть Модель и что туда входит
С одним из ее активных разработчиков, @craigacp активно вкладывается в разработку ONNX и Java TensorFlow API - талантище и очень мощный разработчик и исследователь, под его началом молодый сотрудники активно пилят алгоритмы - думаю все у них получится
Это не просто вещь в себе, но и попытка поднять в одну экосистему и другие фреймворки, имеющие Java API: XGBoost/LibLinear/ONNX/LibSVM
А вот ноутбук на Java с KMeans github.com/oracle/tribuo/…
@mittov @dsunderhood Питон - это скорее не язык, а такой интерфейс
Язык для интерфейсов в DL/ML, да, пожалуй так, и весьма хороший язык, вы не подумайте, что я тут пришел его обижать. Мне по душе типизированные языки для либописания с питоноподобным синтаксисом (Kotlin - один из них). twitter.com/not_logan/stat…
Про ONNX я отдельно напишу завтра - но скажу честно, в 2020 его Java API не пользовался только ленивый, пытаясь встроить в свою DL либу.
В @jetbrains Research тоже активно пилят фреймворк поверх ONNX - github.com/JetBrains-Rese… для наших хитрых планов по захвату мира!
На сегодня все, мне приехала доставка из Ленты, пойду смывать теплой мыльной водой остатки ковидных телец с ряженки. Всем хорошего вечера, завтра я хочу посвятить время такому неоднозначному фреймворку как Spark ML, его экосистеме, прошлому, будущему, а также распределенному ML
@dsunderhood @jetbrains Только у нас pure-Kotlin runtime и для JVM никакого JNI :)
Коллеги, не переживайте, это дело наживное, вместе поправим, когда надо будет ускориться. twitter.com/vdtankov/statu…
Среда
@dsunderhood Да да, тесты заставь сперва своих дбашников написать. Ну или читаемый запрос писать хотяб, ну там сложный какой то. Это еще а как то можно через запрос контролировать способ отдачи результата: стрим или батч(и)? О UDF и дба давай поговорим еще!
Вперед, мои верные нукеры-ДБАШНИКИ.
Про тесты в DS можно долго и интересно разговаривать. Например о тестировании алгоритмов ML/DL, особенно в русле проблемы воспроизводимости результатов от прогона к прогону, даже со всем просеянными сидами. twitter.com/mr_apt/status/…
Через пару часов доделаю рабочие активности, уложу активного трехлетку спать (из машобуча его интересует только автопилот, которым занимается один мой друг), и мы устремимся в мир распределенного машинного обучения.
А пока пару видосов про Spark ML (1 часть - введение в DS для джавистов и немного Spark ML)
"Смузи ML вместе со Spark MLlib" с JBreak'18
youtube.com/watch?v=rktYkX…
И чуток глубже в SparkML, для тех, кто уже понимает в DS и интересуется, как поделать что-то на SparkML
youtube.com/watch?v=J-najk…
Погнали. Используете ли вы Spark в 2020 году на вашем проекте? Нравится? Хотели бы?
Тред про плюсы Spark ML: лично я стартовал на нем в 2013 на версии 0.8 (SVM + distributed matrices на 100 Гб данных) на кластере из 10 тачек. И это было примерно в 10 раз лучше Mahout. Тогда и началась наша любовь.
За эти годы я видел некоторое: пилил приватные алгоритмы, падал на стандартных, делал PR, испытывал боль от перехода от MLLib на RDD на MLLib на DataFrames в 2016-17, читал по нему тренинги, делал package для Spark Package за деньги и не под своим именем. И конечно, читал код.
Иногда, мне кажется, я знаю каждый класс в этом фреймворке, прочел треды в каждом Umbrella тикете, помню в лица юзерпики многих коммитеров.
В Spark ML постарались перенести оптимальное большинство алгоритмов, которые в целом могут быть распаралеллены по данным и не нуждаются в синке на каждый чих и видеть все данные в моменте (как DBSCAN, с ним прям беда)
С самого начала - это было рабочей штукой, а иногда и единственным способом сделать достойный ML на Java/Scala и одновременно затащить это все куда-то под Spring Boot
Не в последнюю очередь, синергия Python коммьюнити, использующего Spark как платформу для распределенного ML и отдельных товарищей внутри Databricks обусловило приход DataFrame API (с оглядкой на pandas), а затем и появление проекта Koalas github.com/databricks/koa…
Также за годы подтянулись довольно приличные байндинги к R с поддержкой формул ~x1+x2, но лично я всегда предпочитал пакет Sparklyr spark.rstudio.com
API делался с оглядкой на scikit-learn сразу, как на золотой стандарт, поэтому кривая обучения для питонистов была не очень крутая
Оно работает поверх HDFS! В экосистеме Hadoop.
У него имеются бесшовные и дешевые (по сравнению с java/scala) коннекторы к таким источникам данных, как csv/json/txt
Вы можете делать препроцессинг на ETL/SQL головного мозга и выплюнуть в датасаентиста.
Имеется базовая поддержка тюнинга гиперпараметров и оценки моделей. Для других DE-интегрированных тулов а-ля @ApacheMahout или @ApacheFlink - это редкость.
Чуть подробнее я расписал основные плюсы в этой статье
zaleslaw.medium.com/i-have-been-a-…
Недостатки Spark ML (стандартной библиотеки): самая большая проблема - это низкий приоритет у либы у самой компании @databricks, начиная где-то с 2017 года и при этом очень жесткий контроль над развитием с ее же стороны. Пойдем по проблемам:
Ансамбли не завезли и видимо уже не завезут: есть частные случаи в виде RandomForest или Gradient Boosted Trees, но обобщенных Stacking/Bagging/Boosting тоже нет. В коммьюнити решить проблему пытались, но далеко не продвинулись. pierrenodet.github.io/spark-ensemble/
Странная и заброшенная попытка с online-learning, в ранних версиях были online Kmeans/LinReg на RDD, ясно, что это сложная, не до конца изученная область, но можно было приделать какие-то наивные версии.
Ну и работает это только на DStreams, а со StructuredStreaming нет
Надо понимать, что все данные из датафреймов и датасетов не тренируются as is, а проходят через стадию конвертации в вектора из чиселок и операции над этими векторами и чиселками отнюдь не так круто затюнены, как современный суперSpark (а там прям вообще все круто)
Много попыток интеграций с DL-фреймворками, которые закончились либо ничем, либо чем-то слабоэффективным (тут не вина Spark, как такового, а скорее амбиции @databricks, которые пытались и с TensorFlow(аж три раза) и с Caffee и с PyTorch и сейчас пытаются с TF через Horovod
Самая законченная попытка - это DL4j поверх Spark - оно реально работает, видел в проде, дебажил сие добро, проблемы - родовые травмы DL4j deeplearning4j.konduit.ai/distributed-de…
В кишках творится анархия - код до сих пор местами обертка над RDD MLlib (постепенно мигрирует, большая задача), местами это приводит к странным аномалиям по потреблению памяти, дурацкие распределенные матрицы неконсистентно перемешаны со связками векторов. Нет единого стиля.
Отдельной боли заслуживают средства сериализации моделей. Почему-то выбран parquet, довольно сложный формат для парсинга. JSON - только за деньги в Dataricks Runtime. Поддержка старого доброго PMML начата и брошена (он работает только для 7 старых моделей в RDD MLLib).
В самом Spark ML все очень грустно с загрузкой моделей из других систем для transfer learning/inference, хотя много готовых Java API доступны.
У меня очень хорошая статья на эту тему, где я подробно все это разбираю zaleslaw.medium.com/weakness-of-th…
Spark ML экосистема: если вас заставляют тренироваться на Spark ML, то советую обратить внимание на игроков экосистемы: Spark Packages spark-packages.org/?q=tags%3A%22M… mmlspark github.com/Azure/mmlspark и PravdaML github.com/odnoklassniki/…
На Spark Packages можно найти много интересного - например интеграцию Spark и Scikit-learn spark-packages.org/package/databr…, хоть она и архивная, но проложила дорогу к общему подходу отправки вычислений из питоновских научных фреймворков на бэк Спарка github.com/joblib/joblib-…
Приличная интеграция отличной библиотеки машинного обучения h20 (но сыр не бесплатный) github.com/h2oai/sparklin…
Также там лежит много мертвого кода, который можно утащить себе в проект для решения конкретной задачи, будь то TopicModeling или KNN (на квадра-деревьях)
Проект mmmmmlspark от Microsoft решает кучу проблем, описанных в предыдущем треде, активно разрабатывается, но знают про него мало. Пользуйтесь, не стесняйтесь.
Последний проект, PravdaML, делал в @odnoklassniki Дима Бугайченко (теперь, кажется в Сбере), там есть байесовская HPO/XGBoost-интеграция и много приятных плюшек при работе с Pipeline API
Сегодня было много работы и умеренно твиттилось, завтра продолжим про распределенное машинное обучение и погрузимся в @ApacheIgnite ML, историю его разработки, возможности и особенности реализации
Напоследок кину ссылку на замечательный аккаунт нашего KotlinForData-евангелиста, Марию. У нее англоязычный твиттер, очень добрые подписчики, если вы смелый, ловкий, умелый - фолловьте. twitter.com/mariaKhalusova…
Вспомнил, что забыл рассказать еще пару фактов про Spark и Kotlin.
У нас же есть замечательное api к Spark на Kotlin github.com/JetBrains/kotl…
Там решено много проблем, которые есть, в Java API, а его создатель @asm0di0 охотно общается насчет идей и пожеланий по развитию.
Маша не держит все яйца в одной корзине! twitter.com/mariaKhalusova…
Четверг
На пути в JetBrains: в 2017 году я обратил внимание на статью на хабре habr.com/ru/company/gri… Там ребята из компании @gridgain сделали копию @ApacheMahout поверх in-memory database @ApacheIgnite Потом мне удалось с ними пообщаться вживую (помогли старые EPAM-вские связи)
Вот в этом твите я подробно описывал, что меня привело в @ApacheIgnite.
Давайте я начну с опросов, я допускаю, что вы никогда не пользовались Ignite ML и я открою для вас маленькую теплую Новую Каледонию. twitter.com/dsunderhood/st…
Опрос про Ignite ML. Слышали ли вы что-то про него до этой недели?
Ясно, что изначально IgniteML поверх @ApacheIgnite появился просто как продающая эту базу данных пунктик, а -ля OracleML/DS, RedisML, но в развитии он пошел дальше, чем просто какая-то математика в БД. Лично для меня - это был способ создать распределенный ML лучше чем SparkML.
Чтобы проблемы описанные в посте zaleslaw.medium.com/weakness-of-th… были решены, чтобы была легкость в добавлении новых алгоритмов, но и в целом in-memory БД потенциально лучший движок для ML, чем ETL с диска.
IgniteML до начала 2020 года (релизы 2.6-2.7) очень сильно менялся в плане структур данных, имплементаций алгоритмов и API и только с марта этого года (2.8) можно говорить о более-менее стабильной версии.
Вот в этом видео я рассказываю о первом стабильном релизе и его базовых фичах (им отдельный тред я хотел бы посвятить) youtube.com/watch?v=SnUgcT…
Меня часто спрашивают, зачем вообще было делать такой фреймворк - в этом посте ответ, кому интересно более глубокие моменты в мотивации создания, а также ссылки на образовательные ресурсы - ныряйте
zaleslaw.medium.com/apache-ignite-…
Но основная была следующая - все эти FlinkML/Mahout/SparkML/RedisML сделаны как будто не для людей. Просто набор алгоритмов, не соединенных общим API и идеей, их сложно использовать в проде, любую вещь типичную в тренировочном цикле или оценке надо писать руками. ML для людей.
Погнали по фичам: я составил сравнительную таблицу Spark ML и Ignite ML по фичам. В целом мы его делаем
gist.github.com/zaleslaw/a7606…
Глядите сами: стэкинг, бустинг, бэггинг есть
Вся классика алгоритмов: деревья, регрессии, перцептроны (кстати наш бохаче), SVM, KMeans, GM есть. Кроме того, я активно занимаюсь темой approximate ML algorithms, среди них адаптация KNN - авторский ANN
Коллаборативная фильтрация появилась в конце 2019 года (ALS, факторизашки). Препроцессоры базовые есть, новые легко пишутся (это вам не в Spark всунуть) - у нас 1-2 метода переопределил и поехал.
Также мы сделали платформу для распределенного инференса и хранилище моделей на базе кэшей Ignite. Сюда очень легко подключать модели из других платформ, имеющих Java API и свой кусочек рантайма
Большое развитие получил фреймворк подсчета метрик распределенно (все классические метрики поддерживаются) ignite.apache.org/docs/latest/ma…
Также мы продвинулись дальше в тюнинге гиперпараметров (я в свое время вдохновился парочкой книг по AutoML) - про это я напишу отдельно ignite.apache.org/docs/latest/ma…
Также мы сделали базовый online-learning для большинства моделей, и пусть он пока местами не финализирован, писать это руками было бы намного сложнее в инфраструктуре @ApacheIgnite
ignite.apache.org/docs/latest/ma…
Больше про соревнование со Spark ML (spoiler, с 2020 оно для меня немного в прошлом), планы на будущее
zaleslaw.medium.com/apache-ignite-…
@dsunderhood RedisML was replaced by RedisAI, but RedisAI is not used for training but for realtime low latency inference.
Very useful comment, happy for Redis! twitter.com/g_korland/stat…
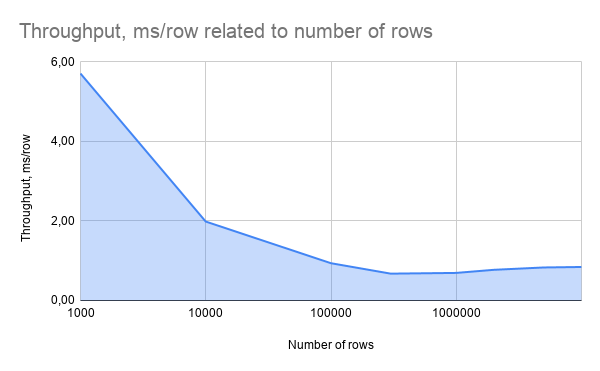
Насколько быстрым является Ignite ML. Скажу честно, мерить performance ML тренировки (именно она меня и интересовала больше) - дело неблагодарное. Что есть время работы, скажем распределенного SVM? Достижение определенной acc? Нет же? Фиксированное количество глобальных итераций?
Может быть взять синтетический бенчмарк на известном датасете? Но там почти всегда данные для тренировки на 1 машине с 1 памятью и выгодные создателю бенчмарка. Что сделал я? Мне было интересно весной 2020, насколько быстро я могу решать задачу от клиента в кластере.
После работы с ним, я нагенерил сходные обсфурцированные данные, запустил на его задаче классификации (бинарной!) в кластере со урезанной конфигурацией (1,2,4 ноды вместо 100) и записал все данные в этот пост
zaleslaw.medium.com/apache-ignite-…
Будем считать это отправной точкой.
Запускался я кластере из 4 тачек с JVM с такими настройками -Xmx80G OffHeap = 10G (да, Ignite активно любит OffHeap, как и любая тула BigData на Java). Настройки у алгоритмов я брал дефолтные (чтобы потом с легкостью повторить эксперимент), а там где менял - фиксировал.
Естественно, себя хорошо зарекомендовали тренеры линейных моделей, а-ля LogReg/LinReg/SVM и гораздо хуже разные древостроительные. Дело в том, что мерджить информацию с разных партиций на мастере (мы мерджили гистограммы) - это дорого. Тут никто пока сильно лучше ничего не сделал
Очень неплохо отработал старичок KMeans и основанный на нем внутренне ANN (приближенный KNN). Обычный KNN сдыхает очень быстро, а вот если вы как-то ограничили число суседей, то вместо пробега по всему датасету, вы можете бегать и предсказывать по 10 000 центрам мини-кластеров.
В целом, от обработки 10^9-10^10 строк для некоторых алгоритмов мне немного не хватило памяти (например по 120-200GB на нодах вместо 80 были бы уместны). Со мной делились числами прогона на 100 нодах по 40GB - ммм, там все очень хорошо.
Тред про инференс с других ML либ: во-первых, [@ApacheSpark](https://twitter.com/ApacheSpark) и @ApacheIgnite не сильно-то и соперники (как могло показаться). Например, [@ApacheSpark](https://twitter.com/ApacheSpark) довольно часто использует нижележащий Ignite как слой для ускорении и кэширования в памяти.
ignite.apache.org/docs/latest/ex… - IgniteDataFrame
Логично было бы сплотить их еще больше - так и родился проект по парсингу моделей ApacheSpark, сериализованных в parquet. Для этого мной был реализован отдельный подмодуль spark-model-parser. Вы трените SVM в Spark, грузите в Ignite и можете разное: ignite.apache.org/docs/latest/ma…
Загруженная модель является полноценной моделью в ApacheIgnite (мы не тащим Spark runtime сюда вообще, чистый парсинг файла) и может быть обновлена и дотренирована на данных в Ignite, используя update моделей.
Затем по значимости идет полноценная интеграция с @XGBoostProject . У него хорошее Java API, с ним все интегрируются, это легко и приятно.
Буквально вчера в мастере появилась интеграция с @CatBoostML благодаря PR от @MrkAndreev
github.com/apache/ignite/…
Спасибо, Марк!
Также, какое-то время назад пришли ребята из @h2oai и добавили инференс для их Java API. Так в ignite попали H2OMojoModel и H2OMojoModelParser
Также у нас была большая история с интеграцией с Tensorflow в 2018-2019 годах habr.com/ru/company/gri…
Очень сложная история в ходе которые мы начали даже контрибутить в Java API TF, но в тот момент там было все медленно, вышла TF 2.0, рантайм весил 1.5GB, были баги и я дропнул TF
В целом, мы очень здраво использовали Ignite как аналог Horovod для раздачи задачек в распределенном режиме (не зная про Horovod, его делали одновременно), TF в распределенном режиме работала хорошо. Но в TF надо залезать основательно, чтобы так интегрироваться, maybe in future
medium.com/tensorflow/ten…
В целом это работает на прошлых версиях Ignite и @TensorFlow , можно побаловаться.
Пойду поработаю пока, а вам пока опрос с подводкой к следующему блоку. Тюните ли вы гиперпараметры и какие мат.методы используете?
@dsunderhood Ручной перебор
Наши руки не для скуки, наши глазки для побед! twitter.com/IAshrapov/stat…
@dsunderhood А это нормально, что генетика такая непопулярная?
Она underrepresented в большинстве фреймворков для HPO. Меня это тоже огорчает. twitter.com/tttttrus/statu…
@tttttrus @dsunderhood Видимо, думают, что настроить работу с какого-нибудь градиентного спуска проще, чем запрогать нсга.
Вообще, конечно есть миллионов методов (как точных, так и эвристик, взятых с потолка) как дискретной, так и непрерывной оптимизации, которые ждут своего часа! twitter.com/skv_nskv/statu…
В батюшке scikit-learne имеется два способа перебирать сочетания гиперпараметров - GridSearchCV и RandomizedSearchCV. Ну и как показал опрос, ими многие не пользуются, предпочитая зоркий глаз и интуицию - алгоритмам оптимизации на втором уровне.
Странно, что тот же навык не применяется для апдейта параметров нейросети вместо SGD или Adam.
Ну да ладно, хотят люди делать хоть что-то сами, пусть делают.
Более продвинутые пользователи в Python знают и пользуют scikit-optimize.github.io/stable/ с его BayesSearchCV (наиболее распиаренный "альтернативный" метод) или Sequential model-based optimization (SMBO) через skopt
Также большой популярностью пользуется github.com/optuna/optuna - у нее есть куча интеграций со всем подряд и свои способы достичь оптимума
И не менее прекрасный github.com/hyperopt/hyper…
В котором уверовали в парзеновские деревья (и они таки весьма хороши) и в целом в движение вдоль Паретовских границ.
Однако в мире JVM все тут намного грустнее. Даждь бог, хотя бы полный перебор организован, а-ля GridSearch.
Если говорить про распределенную среду, то все еще сложнее. Тут возможны несколько схем тюнинга гиперпараметров и утилизации ресурсов кластера.
В целом, задача тюнинга гиперпараметров мне приглянулась, когда я искал прикладные приложения так называемой bilevel optimisation problem. Игра Штакельберга - это весело, но лично я перебрал много мат.методов для решения задачи двухуровневого линейного программирования и выбрал..
генетические алгоритмы как наиболее устойчивое семейство алгоритмов, позволяющих при удачной кодировке и фитнесс-функции двигаться постепенно к хорошему решению. Конечно, не без элитизма, имитации отжига и прочих трюков для неумолимой поступи прогресса.
Это не значит, что я не пробовал другое, но на мою задачку они легли идеально. Моя мат.модель чем-то была похожа на современных Generator and Discriminator в GAN, только они у меня были Constructor/Destructor и делали не фотки, а дорожную сеть, устойчивую (в некотором смысле)
У меня были отличные датасеты, дорогая фитнесс-функция (ее вычисление требовало значительного времени на одной особи, прогона алгоритма оценки надежности)
Нашел тему еще одной статьи или доклада, но не могу найти текст
"Генетический алгоритм для решения задачи оптимальной доставки грузов на дорожном графе большой размерности" с DOOR'13 math.nsc.ru/conference/doo…
Не прошло и 2 года, как я закончил свои научные дела (думал я, ага), как я увидел эту задачу в HPO для ML. Как же я внутренне ликовал. Мы делаем либу, еще и на Java, тут своих тулов нет, можно порезвиться с нуля!
Но сначала надо было родить все метрики, кросс-валидацию...
Стартовать в теме мне помогла статья Бенджио "Random Search for Hyper-Parameter Optimization" (есть тема на которую он не писал?) jmlr.org/papers/volume1…
Когда я видел формулы один-в-один из своего диссера я радовался, что копал куда-то в верном направлении.
После упорных трудов в конце 2018 пришло время пилить HPO в Ignite. Выбирая между Bayes и Эволюционкой, я выбрал знакомые эволюционные алгоритмы с элитой (чтобы не терять хорошие решения).
Также было ясно, что придется запускать много тренировок, каждая тренировка - время кластера и надо попытаться тренироваться в параллель, управляя количеством тренировок в параллель.
В случае эволюционных алгоритмов одно вычисление fitness function - эквивалентно прогону тренировки с фиксированным набором гиперпараметров. Они могут быть выполнены на одном наборе изначальных данных, но в ходе тренировки могут быть оккупированы новые блоки памяти.
Тем не менее, даже, если у вас 10 параметров с 10 дискретными значениями каждый, это уже 10^10 вариантов, а с RandomSearch или ген.алгоритмом с 10 особями в поколениями и на 100 итерациях вы можете себя ограничить 1000 прогонов, что меньше значительно.
Подробности все в моей самой большой англоязычной статье в жизни (скажите, такое можно уже на архив?)
zaleslaw.medium.com/theory-and-pra…
Если кто-то в теме, то был бы рад обсуждению или поверхностному ревью идей (и имплементации), пишите, есть что обсудить.
Вот на этом я не планирую останавливаться, думаю, что JVM мир ждет нормальную либу (не часть другой) для тюнинга гиперпараметров в других фреймворках.
Думаю, что она должна быть написана на kotlin:)
zaleslaw.medium.com/theory-and-pra…
Завтра день нейросетевых фреймворков. Готовьтесь. Буду много ругаться и радоваться.
Перед завтра надо выяснить. Есть два вопроса: какой у вас любимый нейросетевой фреймворк
Было про любимые. А теперь на чем приходится деньги зарабатывать:
@dsunderhood 👍🏻 Насыщенная неделя в этом аккаунте!
Спасибо, я никогда в жизни столько не твиттил, надеюсь кому-то полезно и мы с вами останемся на связи после недели тут. twitter.com/ivn_finaev/sta…
Пятница
@dsunderhood лучше тред #научпоп о решаемых задач залепи тут!)
Так моя наука - пилить фреймворки, чтобы дата-сайнтистам было легче жить. Поэтому пишу про свои решаемые задачи - чтобы например градиенты для DepthwiseConv2D считались не только в Питоне и MobileNet пахал у всех, у кого надо. twitter.com/nituP_idohU/st…
@dsunderhood Мы тоже использовали генетические алгоритмы для подбора гиперпараметров в одном из проектов. Они дали нехилый прирост в точности. И поскольку моделька была не очень тяжёлая, это не заняло много времени. Плохо, что генетика мало где реализована. Нам пришлось делать самим.
Да, причем, что самописных либ - прям миллион на любом языке. Но почему-то они все полузаброшенные (может студенческие проекты, я вот не знаю) twitter.com/aigirlpower/st…
Вчера мы поняли, что вы любите PyTorch, пишите на PyTorch (человек 40 из 2000 подписчиков твиттера), но немного и на TF. Недавно в ODS я заметил довольно странный смайлик - перечеркнутый TF, если кто-то обсуждает TF, задает вопросы и т.д. Хотя в 17-18 году все было иначе.

Лично мне @PyTorch не интересен (хотя его кишки я облазил), его многословное API, его слабенькое нечто для инференса на java - выдают в нем плохого кандидата для JVM мира. Единственное, мне понравилась битва двух сверхразумов - github.com/catalyst-team/… и @PyTorchLightnin
Здоровая гонка и амбиция, попытки спрятать не нужную широким массам мешанину под ООП и функции, а также конкуренция за внимание @karpathy - все это дает мне пищу для изучения и референсы для имплементации
Я больше болею за "наших" - команду Catalyst. Но в любом случае, как говорил Мао: "Пусть расцветут сто фреймворков для PyTorch, сто цветов"
Мне импонируют подход @Google - сделали авто дифференцирование, монсеньор @fchollet запилил keras для масс, написал чудесную книжку - все же читали, и вкрутил это в TensorFlow. Так отвалились бэкенды для CNTK (плак-плак) и иные.

Однако вместе с удобным API он принес и некий расслабон создателям @TensorFlow - много трюков и приколов, включая куски оптимизаторов, градиентов, операторов, странного препроцессинга перекочевали из нативного кода в Python
Хотя сначала Python - был просто тонким фронтендом поверх нативного кода и на каждый чих уходил туда.
В 2.x, когда вся кодебаза оказалась смерджена - все стало иначе. При этом C и C++ API оказались подзаброшены - многие вещи не обновляются с 2018 года.
Как следствие тормозится развитие такие языков оберток, как мостик в Java, Go, .NET, JS (люди в TF JS ручками на своей стороне блин добавляют градиенты для операторов)
Тем не менее, код написан довольно чисто, в нем можно разобраться, @Google поддерживает внешние группы разработчиков, которые пилят свои мостики, как например SIG JVM (пилим в Java), встречаются с нами, рассказывают про релизы. А еще у Гугла очень много рабочих рук, чтобы делать
Экосистему: TFLite для Android, TF.js, TensorBoard, Swift (с автодифом на уровне языка), TF Serving, куча MLOps интегрируется с TF, разве что ONNX тут немного подкузьмил - я считаю месть за гибель Keras для CNTK
В 2019 году, используя TF Java API я был уверен, что это API только для инференса и на нем нельзя тренироваться. Однако, лазая по классам, я вдруг обнаружил дырки для оптимизаторов, куда можно сбрасывать веса и обновлять их согласно их внутреннему закону (адамову-адамово!)
Я собрал тренировку простой модели LeNet-5 и линейной регрессии на этом безобразии, можете полюбоваться zaleslaw.medium.com/lenet-5-in-kot…. Но в целом, мне претило писать стандартные модели на таком низком уровне. А не написать ли Keras на Kotlin подумал я в начале пандемии и устремился!
@pytorch_ignite twitter.com/dsunderhood/st…
Тут из Тулузы сообщают про github.com/pytorch/ignite
Но позвольте, господа, как они посмели назвать свой фреймворк именем прекрасного @ApacheIgnite (тм) ? Это каково? У них юристы не пробовали трейдмарки проверять. В общем, не люблю этот ignite :) нас путали twitter.com/francereports/…
📣Check out the first early preview of KotlinDL (v.0.1.0), a high-level Deep Learning framework that offers simple APIs for building, training, and deploying deep learning models in a JVM environment. blog.jetbrains.com/kotlin/2020/12…
Ну и написали, да! KotlinDL с Keras-like API поверх низкоуровневого Java API. twitter.com/KotlinForData/…
Это альфа, там пока все просто, VGG - подобные вещи, transfer learning. blog.jetbrains.com/kotlin/2020/12…
Но именно с этого и начинали TF JS, TF..NET и другие.
Если вы пишите на JVM языках - приглядитесь, какие-то простые вещи можно делать уже сейчас github.com/jetbrains/kotl…
Но мы совершенно не собираемся останавливаться на достигнутом. Планов много и в 2021 будет много интересных новостей на эту тему.
@dsunderhood It's not just (TM) it's (R) now :)
Ну все, PyTorch, переименовывай! twitter.com/ApacheIgnite/s…
@dsunderhood Ну кто виноват, что из TF какаху сделали. Я начал TF использовать с начала 2016, и тогда его использовать было очень приятно, потому что весь фреймворк был как на ладони. Начиная с 2018 все резко пошло под откос :/
Я не буду столь резок в выражениях, но для ресерча - и впрямь, трудновато. twitter.com/DanevskiyD/sta…
Какие есть глобальные цели у всех, кто делает API DS-тулов не на Python, и DL фреймворки и байндинги, в частности.
Принести в экосистему своего языка возможности, которых там нет.
.NET/Go/Java/Scala/Kotlin/C++/JavaScript - в каждом из них есть десятки тысяч умных людей
Которые отлично знают свою экосистему, свои фреймворки и хотят иметь ПРОСТЫЕ и ДОСТУПНЫЕ инструменты а-ля scikit-learn/Keras/numpy.
Эти люди не собираются мигрировать в другую экосистему, тулы, понижать свою производительность. Напротив, хотят ее повысить. Особенно крут тут MS
Поглядите, ну какая бигдата и ML на .NET в 2017 сказали бы вы. А теперь - к Spark есть байндинг, ML..NET - написали, к TF - прикрутили достойное API, платформа - развитая, ONNX - в кулачке зажат (все вы скоро на него подсядете). Любо, братцы!
Конкуренция за умы и души новых поколений студентов-juniors. Студент - человек, который очень сильно доверяет слухам, мнению случайных людей, чьем мнение в какую-ту фазу Луны показалось авторитетным. Чей PR будет лучше, чье сарафанное радио мощнее - тот и получит новые головы.
Согласитесь, отсутствие поддержки парсинга JSON в языке - студента не напряжет. А отсутствие тулов для Data Science (которым манят как калачом в каждой рекламе в 2020) - серьезная причина "выбрать" Python, а не язык X. Вот все и борются.
Неумолимая поступь прогресса. ML/DL через 5 лет будет в любом языке обычным средством вроде ORM или Web-Server. Просто надо это принять. Это не Rocket Science, мы же с вами разобрались... И другие разберутся.
Вы же понимаете, как легко будет делать DL/ML, если надо будет писать только forward pass, a backward - уже нет. Тогда движки для автодифа - не нужны. А это придет в каждый язык. Фреймворк для DL можно будет написать в 10-20 раз быстрее и поддерживать его будет супердешево. Тред!
Для Kotlin существует минимум 2-3 проекта.
1 по значимости
github.com/breandan/kotli… от @breandan - он вообще мне кажется немного гений, планирую вскоре попробовать в качестве бэкенда.
Посмотрите, как божественно поступает Facebook - делает по сути новый, дифференцирующий Kotlin.
ai.facebook.com/blog/paving-th…
До прода надо немного подождать, но сказка же.
Swift - проторил дорожку и поддержал на уровне языка
github.com/apple/swift/bl…
Правда, имхо, Swift for Tensorflow - незаконченное изделие, но ребята кайфуют, что сказать
А С++ не хотите? Если в ваш язык не завезут расчет производных на разностных схемах - делаешь C++ ядро -> С API-> мостик и вперед!
open-std.org/jtc1/sc22/wg21…
А С++ не хотите? Если в ваш язык не завезут расчет производных на разностных схемах - делаешь C++ ядро -> С API-> мостик и вперед! open-std.org/jtc1/sc22/wg21…
Если не хотите ждать языка - уже есть либа github.com/autodiff/autod…
Ясно, что перформанс может быть спорный и мне пока по душе больше библиотеки, нежели языки, но я - ретроград. Хотя и признаю новое веяние.
На сегодня все, на выходных у меня немного времени, да и вам надо будет отдохнуть от суровой рабочей недели. Планирую писать о следующем - работу на удаленке, ворк-лайф баланс, совмещение занятий наукой и разработку, какие-то странные наблюдения и просто про жизнь, книжки и т.д.
Суббота
Мой идеал: учоный нарисовал на бумажке формулы с тензорными операциями, сфотографировал на планшет, картинка в облаке распозналась и преобразовалась в вычислительный граф, остается указать тренировочный датасет, параметры тренировки и можно идти пить кофе, пока модель тренируется twitter.com/dsunderhood/st…
В моем идеале ученый даже не знает что такое тензоры (например, он биолог), но все описанное ниже продолжается ^__^ twitter.com/ivn_finaev/sta…
Theano is not dead! Не надо тут! pymc-devs.medium.com/the-future-of-… twitter.com/dsunderhood/st…
Его память священна, бегут пионеры: "Привет, Тиану", летят самолеты: "Привет, Тиану". twitter.com/ivn_finaev/sta…
Сегодня выходной и у меня он реально был: уже 3 года, как я перестал работать по субботам и вскр. Я перестал читать техническую литературу в сб/вскр и посещать рабочую почту и чаты. В моей жизни случился сын и это самое лучшее, что произошло с моим work-life balance. Тред!
В первый год я еще иногда работал по субботам, ребенок был мал, неразумен, а я отлынивал. Одной работы мало, надо две, деньги в семью, работа по вечерам, ночам и все в режиме без сна. Ну и что.. Очень быстро лошадка здохла. А ребенок привык к папе в углу за компом как к мебели.
Мне повезло с моим руководителем - тоже семейным человеком, который позволил мне работать частично на удаленке еще в 2018 году и это позволило мне наблюдать (поначалу лишь наблюдать), как растет сын, что приходится делать жене, делать небольшие перерывы в работе на общение.
Моя жена закончила матфак и сама айтишница - поэтому мне повезло: никто не воспринимал, что я "сижу весь день за компом, что сложно встать и сделать", как у некоторых моих друзей. Но именно это и расхолаживало. Вот это понимание. Я перестал делать что-то по дому, готовить.
Стал обычным рабоче-бытовым паразитом. Много моих знакомых в ИТ неоднократно в таком положении оказывались и тут я не рассказываю вам что-то уникальное. Так вот, я думал в какой-то момент, что это нормально, пока не начал (не знаю зачем читать паблики а-ля "ЩастьеМатеринства" ВК.
Это помогло мне другими глазами (с женской стороны) взглянуть на положение вещей. И если моя жена не роптала и понимала, не значит, что этого бы не случилось в будущем. В какой-то момент, я заметил, что ребенок играя в папу, изображает человека за столом за компом.
Эта маленькая нейросеточка просто выучила самый обобщенный папин паттерн жизни и поведения. Да и вообще нейросеточка стала такой интересной, что готовить данные для нее тоже стало интересно. Но на это нужно время. Где взять? Для начала сократить работу в орг.комитете конференций
Пару лет я волонтерил в оргкомитете конференций @jugrugroup Классные ребята, классная движуха и тысяча часов инвестированные в счастье и амбиции других людей. Я решил инвестировать их в самого важного спикера - своего сына. Вы знаете, получилось. Лучше, чем с некоторыми спикерами
Потом я перестал брать новые подработки, связанные с поездками в другие города. Было сложно, спрос на меня возрос, и надо было учиться говорить "нет". Сначала было тяжело, пару раз меня просто уломали, но потом стало проще. Но этого было мне мало.
Потом, впервые за 6 лет я поехал на отдых с семьей, не пытаясь приурочить к конференции. Как было до этого - еду на конфу, иногда один, иногда беру жену и это "типа отпуск". Так было много раз. Все время много волнения, элементы подготовки, жесткий маршрут и тайминг.
Потом я постепенно стал ставить рамки всезаполняющей "работе" (прямой и непрямой): начинал с дней без Интернета (по вскр), заставлял себя вместо чтения статьи взять ребенка и пойти играть/гулять/кормить жывотных. Постепенно выработалась привычка искать иное удовольствие в выхах
Вместо интеллектуального поглощения и выработки информации. Я стал лучше спать, шерсть заколосилась, надои выросли. Помните, как в старом фильме наших отцов, "Нео бочком-бочком вышел из Матрицы".
Сегодня выходной, и у меня уже была прогулка по снежку в Спб, оплата коммуналки, строительство дредноута из конструктора Полесье, сейчас я закончу в твиттер и меня ждут - горячие хачапурики из доставки и продолжение чтения книги Фрица Фишера о причинах Первой Мировой.

У меня такое тоже примерно было. Хотя отпуски были полноценные, а не "под конференцию", но постоянные подработки по ночам и выходным были. И это жесть как тяжело и выгорабельно. Вовремя осощнал проблему и исправил её. И вам рекомендую. 10 из 10 что вам понравится результат! twitter.com/dsunderhood/st…
Люди делятся наболевшим twitter.com/shaderzzz/stat…
@dsunderhood Отличный тред, спасибо! И приятного аппетита!
Спасибо, тебе тоже хорошего вечера! twitter.com/_bravit/status…
Сегодня выходной и у меня он реально был: уже 3 года, как я перестал работать по субботам и вскр. Я перестал читать техническую литературу в сб/вскр и посещать рабочую почту и чаты. В моей жизни случился сын и это самое лучшее, что произошло с моим work-life balance. Тред!
Я ребята, к чему это написал. 👇 Просто, чтобы те, кто замотался немного в этой гонке за L5-левелами в долине, и почему-то почуял, что это немного не его, знал, что в жизни можно быть счастливым альтернативными способами. twitter.com/dsunderhood/st…
@dsunderhood Такая смена рабочего ритма сказалась на основной работе? Доходы упали или что-то компенсировало?
Сначала упали (подработки приносили много), конечно. Но там вообще дикий эффект у многих родителей-айтишников. Но по отзывам коллег, я стал лучше работать, быстрее решать задачи, четче и доступнее коммуницировать, что сказалось на карьере в + twitter.com/MNZakharov/sta…
Это круто. Но работать по выходным ещё круче, особенно если это в кайф. twitter.com/dsunderhood/st…
Ни в коем разе не собираюсь вам противоречить или навязывать свой подход. Просто помню по себе, что информации о том, что так можно и так бывает - не хватало как-то в жизни в 20-25 лет. Надеюсь, кому-то будет полезно, что я написал. twitter.com/Marat_Galiev/s…
@dsunderhood Так, моя гипотеза потихоньку подтверждается) Спасибо. Я тоже как-то принял решение не работать по воскресеньям.
Да, если даже не строго этому следовать, а просто попробовать и сравнить, что тебе лучше. Знаю господ, работающих 7 дней в неделю. Правда по 5 часов. Говорят - ни на что такое не променяют. twitter.com/MNZakharov/sta…
Кстати, 5 лет назад посмотрел такую штуку мастер-класс, "мне 36 лет" от одного айтишника.
youtube.com/watch?v=es0Yvf…
Тогда воспринял с известным скепсисом. Сейчас, конечно, понял, что все правда.
Это на самом деле круто! Есть ещё один лайфхак с ребёнком - по выходным берёшь его днём на тихий час, и тоже спишь. 100% легальная схема!!! twitter.com/dsunderhood/st…
О, народ делится лайфхаками продуктивности! twitter.com/vorobiev_xyz/s…
@dsunderhood А что стало с карьерой жены? Кончилась с рождением ребенка?
3 год декрета она работал на полставки, потом вышла на полную. До рождения она была в ее направлении медлу мидлом и синьором, сейчас стала ближе к лиду: судя по обязанностям и тому, что она драйвит проекты и менторит юных падаванов. Карьера жены - для меня сейчас #1 приоритет. twitter.com/garkavem/statu…
Воскресенье
@dsunderhood Максимальное уважение жене. Я думаю ей было очень сложно
Передал, она передает спасибо, и что было сложно, но возможно, если второй пилот адекватный и не тянет одеяло на себя ВСЕ ВРЕМЯ:) twitter.com/ladytellur/sta…
@dsunderhood >Одной работы мало,надо две,деньги в семью Я прошу прощения, неужели ЗП дейтасайнтиста в СпБ не хватает на содеражние семьи,что надо искать вторую работу?Я просто смотрю по своим знакомым и никого из ИТ рождение ребёнка не выбивает из бюджета.Я не в курсе нынешних ЗП у вас сейчас
Ну вот фараоны строили пирамиды, кто-то бросался в экспедиции в новые земли, зачиная десяток детей во время перерывов, кто-то работал на двух работах (или шести). Думаете дело было в содержании семьи? Мне думается, немного в другом. twitter.com/MWolf_/status/…
Сейчас маленький комок надежды на карьеру после декрета слегка расправил плечи. Есть прецеденты twitter.com/dsunderhood/st…
Я вам могу пожелать сил, удачи, высыпаться, и адекватного работодателя. У меня среди знакомых есть прецеденты выхода на работу после декрета программисток и автотестировщиц, в том числе растивших детей в одиночку. Очень сложно, да. Вечный баланс между своим личным и общесемейным. twitter.com/ai__small/stat…
@dsunderhood Хороший тред. Сам сейчас нахожусь в аналогичной ситуации. Работаю на удаленке, а вечером играю с ребёнком. Правда по выходным все равно продолжаю иногда работать и читать проф. литературу.
Кстати, про проф.литературу. Сегодня я буду брать с полки некоторые книжки и про них рассказывать. Никаких бешеных инсайдов, просто люблю свою домашнюю библиотеку, возможно вы посоветуете свои хорошие книжки в реплаях. twitter.com/malafeev_en/st…
Красавчик. Меня рождение ребёнка сломало пополам, год ушёл на рекавери. Для меня удаленка идеальный вариант - отработал, и вперёд с сыном на улицу на часок. Вместо часа на проезд до/с работы twitter.com/dsunderhood/st…
Всеобщая удаленка с одной стороны даровала нам дополнительной время для семьи, с другой стороны, многие семьи держались на том (есть 2 грустных истории среди знакомых), что они друг друга не видят 24*7 и все удобно (я утрирую, конечно). twitter.com/rocketjump07/s…
@MWolf_ @dsunderhood не в деньгах ж дело. а в интересе, хочется других задач, людей. или просто что-то сделать про боно - конфы, преподавание, школы для джунов и т.д.
С про боно вообще интересно - этого стало в 10x меньше, и оно приняло другие формы - вместо впиливания тонн времени в малознакомых случайных людей я теперь сфокусирован на поддержке "моих ближних" - непосредственных коллег, ревью и небольшое менторство в важных для меня кодебазах twitter.com/konhis/status/…
Есть ли у вас домашняя библиотека?
Мои первые книги по DL/ML и релевантной математике:
Первой была вот такая книга Чжун Кай Лая "Однородные цепи Маркова". Цепи Маркова для предсказаний и моделирования меня так вдохновили, что я даже делал либу для них на java в 13 году, ее внедрили в паре мест у заокеанских друзей

Очень сильно я любил советские учебники по тер.веру и мат.стату. У нас был очень сильный преподаватель в ОмГУ mathnet.ru/rus/person29493, в каком-то смысле был для меня ориентиром в том, как не панибратствуя и не унижая студента доносить до него сложный и качественный материал.

В начале изучения ML/DL хорошим ориентиром были емкие учебные пособия от Яндекса. Тогда я и узнал о великой гонке ядерные советские методы против "их" продажных капиталистических нейросетей. Все грустно закончилось.

Однажды, мой однокурсник уезжал в далеком 2009 из Омска и раздавал книги. Так мне досталась гениальная польская книжка по нейросетям, ген.алгоритмам и нечетким множествам. Эта книга дала мне ощущение, что я с своими мат.мыслями не один и что можно немного писать против ветра.

В 2011 я был на конференции в Челябинске и купил вот такую книжку в киоске ЮрГУ: MLP, Больцман, реккурентные сетки, моделирование нелинейности. Все уже было. Фреймворков не было. Мне она очень понравилась, мы ее потом немного обсуждали на семинаре по нейросетям в ОмГУ.

Мне все это очень нравилось. Но в 2011 году никто за это не платил. Только-только загоралась заря хайпа NoSQL систем, а-ля MongoDB.
Неделю назад заказал чудесную книгу Red Plenty. Она про выдуманный мир, в котором Канторович научился решать задачу линейного программирования поверх Генплана СССР о выпуске товаров ЭФФЕКТИВНО. Это сказка о Тройке, это киберпанк, это "Защита Лужина 2.0".

Только прочтите последний абзац этой книги. Me crying.
Книга написана с глубокой любовью и уважением к русскому языку, науке, сказкам и персоналиям.

Если подходить с меркой реализма, то прыгнул я на эту книгу вот с этого разбора проблемы нахождения оптимального генплана в СССР crookedtimber.org/2012/05/30/in-…
Дальше пойдем кучно: я хорошо читаю на английском, но еще больше люблю читать книги по DL/ML на русском, особенно постобработанные после прогона через GoogleTranslate. Обычно я читаю раннюю версию на английском, но потом покупаю переводную версию на русском. Я уважаю труд авторов

Отдельно хочу отметить книгу Сергея Николенко "синяя книга про сетки с рыбкой". vk.com/sergey.i.nikol… В какой-то момент она стала самой глубокой, сложной, и широковспоминаемой на русском языке. У Сергея талант излагать интересно. Не знаю его твиттера к сожалению.
Мне очень нравятся книги разряда "Идеи машинного обучения" или "Глубокое обучение" от Гудфеллоу- они содержат очень емкие выводы, которые просто открывают тебе глаза на суть вещей. Дают ключ к пониманию. Иногда, конечно, для быстрого изучения - покупаю и "TF за 3 часа"
@dsunderhood Стоило бы отметить «Глубокое Обучение» Николенко. Это оригинал на русском.
Когда пишем одновременно:) Особенно я кайфовал с его предисловий. twitter.com/dmitrybalabka/…
Также мне понравилась книжка "грокаем глубокое обучение", где с нуля пишется PyTorch-подобный фреймворк. С удовольствием писал код всю книгу (правда на java)
По этой полке вы можете увидеть мою бурную биографию справа налево (книги по 1С я раздал несколько лет назад, их нет). Книги старые и добротные, местами подаренные на java-конфах, каждая из них - отлична в своем поле. Много информации не устарело и пригождается мне sometimes

Ну и еще одна из полок: для отдохновения и вдохновения ума. Книги разрешенные к листанию на выходных. Гомер - свежий, из Зингер-башни, справа комиксы про статистику и теорию игр из почившей Республики. Немного R/Python - не влезли на соседнюю полку)

В свое время я хотел поступать на истфак (в 15 лет) - с тех пор осталось увлечение, любовь к работе с источниками и интерес к археологическим памятникам. Особенно интересны из истории страны: 20-ые XX века, развитие древнерусского языка, то как жили наши предки 300-500 лет назад

Я немного разбираю текст на польском, поэтому во время командировок привозил пару раз книги по истории и программированию из Польши. Programista na konferencji rozumie prezentację o kompilatorach i bazach danych. О, вы тоже смогли!

Толстые тома и Клод Моне - приданое жены. Шишкин - уже мой. Любим большие фолианты. Опять же - ребенку куча картинок, в 3 уже можно отличать Моне от Шишкина и Ван Гога. Стили у них разные что-ли)))
Для вновьподписавшихся и тем, с кто успел ко мне привыкнуть и хочет поглубже разобраться с KotlinDL/IgniteML/Kotlin/TensorFlow internals сейчас будут ссылки где на меня можно подписаться.
twitter - @zaleslaw
medium - zaleslaw.medium.com
github - github.com/zaleslaw
Также все свои (теперь редкие) выступления я выкладываю на youtube (возможно там появятся какие-то видео по Spark, KotlinDL и других Java-фреймворках в 2021)
youtube.com/channel/UCW6Z6…
С новостями своими и которые мне интересны в сфере BigData (теперь больше ML/DL фреймворки) я веду ВК
vk.com/big_data_russia
и TG: t.me/bigdatarussia
Также я веду пару ВК-TG для новостей JVM языков (пишу редко и о наболевшем, никаких новостей про новую версию Spring, скорее про сами языки)
vk.com/java_jvm
и TG: t.me/javajvmlangs
📣Check out the first early preview of KotlinDL (v.0.1.0), a high-level Deep Learning framework that offers simple APIs for building, training, and deploying deep learning models in a JVM environment. blog.jetbrains.com/kotlin/2020/12…
Подписывайтесь на twitter нашей команды, если вы заинтересовались KotlinForData. twitter.com/KotlinForData/…
У меня есть Linkedin, там я держу профессиональные связи. linkedin.com/in/zaleslaw/ Стучитесь там, можете написать что вы dsunderhood, приму "дружбу".
Если есть вопросы по контенту этой недели - пишите в личку твиттера или в телегу, там я тоже @zaleslaw Я начинаю завершать свое дежурство в этом твиттере. К концу недели мы разговорились на пятерку, я думаю. Перехожу в режим ответов на вопросы и комментарии к твитам.
Да, задавайте вопросы, не стесняйтесь, у меня сегодня масса времени - кулинарный марафон до вечера, жена обещала научить готовить сырники (я их потребляю, но готовить не умею).
@dsunderhood Кстати, а ты уже писал на этой неделе про R? Если нет, то интересно, как ты к нему относишься, какие у него перспективы.
Немного писал в контексте коннектора к Spark, но в целом нет. У меня странный опыт - я на нем писал DS в 13-15 году немного, RStudio, учится легко, ходил на vk.com/spbrug. Также я пытался сделать R-коннектор к IgniteML, но забил. twitter.com/_bravit/status…
Поднять на нем приложение в прод мне было тяжело 5 лет назад, пакеты очень неоднородные и многие написаны ну вообще не программистами. Немного отдает matlab (я вот его я не люблю ооочень сильно за экосистему и навязанность в научно-государственной среде)
Сразу видно, не перфекционист. Вы только посмотрите, как у него Илиада стоит. Продирает аж до мозга костей. twitter.com/dsunderhood/st…
Глазастый ты, однако. Это кстати признак, что Илиаду я таки листал уже. А вот на Одиссею времени не хватило пока. А анализ точный - я человек первых 80% по Парето. Борюсь с этим. twitter.com/_bravit/status…
@dsunderhood а можешь рассказать, пожалуйста, как она работала на полставки, в какое время и какие договорённости были с работодателем? это каждый день точно 4 часа или 20 в неделю? это с какими-то утренними стендапами или без них?
О, там была сложная схема. 20 часов в неделю как два полных дня и стендапы каждый день. 2 дня в офисе. Один из этих дней сидел я (ходил на стендап во время сна), отрабатывал в субботу, другой моя мама (золотая женщина). Через 7 месяцев дали садик, но стало на самом деле сложнее. twitter.com/Ohirro/status/…
Ну с двухлетке уже почти можно объяснить - мама на "митинге", пойдем играть в коридор. А раньше 2 лет - там очень разные дети, у кого то в 3 месяца можно сидеть на созвонах и работать - а дите тихо угукает, у кого-то ШИЛОПОП и агрессор против дровосеков в мониторе.
@dsunderhood В смысле?! SVM юзали в хвост и в гриву во всём мире. Да и бэкпроп в СССР был придуман параллельно с "их" бэкпропом.
Ваши бы слова, да молодому датасайнтесту бы в уши. Я несколько раз оказывался в неприятной ситуации, когда приходилось объяснять людям - что тут SVM лучше, чем нейросеть, а обсчитать можно на порядок больше. Под грустью имел ввиду окончание холодной войны и "зимы нейросетей" twitter.com/VorontsovIE/st…
Вот что вспоминал habr.com/ru/company/spe…
@_bravit @dsunderhood У меня есть «R в действии» на полке. Абсолютно проклято.
Ну для меня эта книжка своего рода ориентир по функционалу. Сидишь, думаешь, над какой-то фичей в либе. Зачесалось. А как там в R? Обычно там есть все. Свой первый Kaggle я заводил на R twitter.com/rufuse/status/…
@dsunderhood за пять лет много изменилось. пайплайны и фреймворки для аналитиков (mlr3, drake), легкое использование C++ вставок, веб-сервер для простеньких дашбордов, параллелизация (плюс асинхрон), визуализации и т.д. data.table, который для работы с таблицами, в разы проще и быстрее панд..
Вот тут нам пишут, что с R все хорошо стало. Охотно верю. Сейчас многие языковый экосистемы - целые микровселенные в модели инфляционной вселенной (зачастую даже не подозревают, что решают одну и ту же задачу), как упомянутое изобретение backprop одновременно двумя коллективами twitter.com/konhis/status/…
Всем пока! Следующие твиты будут уже следующего ведущего.

















![IGNITE-13714 [ML]: Add catboost inference integration by mrk-andreev · Pull Request #8489 · apache/ignite](https://avatars.githubusercontent.com/u/47359?s=400&v=4)