Архив недели @ykashnitsky
Понедельник
Всем привет! На 3-ей неделе с вами Юра Кашницкий, yorko. Как-то я уже много писал о себе в Slack ODS, чтоб не возникло мании величия, тут кратко: выпускник МФТИ, к.т.н., 3 года тащил mlcourse.ai, mail.ru, сейчас в Нидерландах, Kaggle Master чисто в NLP
Примерный план недели:
- Погружение в DS: Python, SQL, математика
- Погружение в DS: базовый ML + Deep Learning
- Pet projects, Kaggle (плюсы)
- Kaggle (минусы)
- Интервью, холивар про алгоритмы
- Как найти работу в DS за границей
- Случайный набор крутых историй
План недели, возможно, у меня будет выглядеть банальным, но я выражу свое неотесанное, порой циничное мнение о том, что из всего этого добра реально нужно в Data Science. Также могу рассказать про чух-чух опыт поиска работы за границей.
Ну и всякие кулстори и мемы, как без этого. Посмотрю, как Твиттер зайдет для долгих баек, а то интерфейс тут у вас так себе. Намедни Джереми Ховард ретвитнул мой твит о переводе статьи про covid, а я возьми да удали твит :rukozhop: Ну… тем не менее, в добрый путь!
Мем-спойлер 4-го дня: главный (для меня) минус Kaggle

Тред про Python. И сразу каминг-аут, он же наброс: я не могу себя назвать хорошим программистом, но в Data Science вроде пока разрешают и так (от специализации зависит). Смещение акцента в сторону ML Engineers происходит, но вот C++, скажем, скорее всего вам не пригодится
Для тех, кто только готовится к собесу на DS-позицию, я постараюсь по каждой дисциплине указать ресурс для ботвы, причем трех уровней (базовый, средний, двинутый). Python с нуля это интерактивные тьюториалы типа DataQuest, DataCamp or even CodeAcademy.
Средний уровень – это пройти все же нормальный курс или спецуху (например мэйловский на Coursera или от MIT). В этом посте есть ссылки vk.com/mlcourse?w=wal… Из продвинутого знаю курс Computer Science Center по Python, но сам не проходил.
И книг годных можно много найти, но я обещал быть честным и циничным – пока это мне ни разу не было нужно. Ну там, скажем, знать, как C++ и Python на низком уровне в NumPy завязаны.
Оговорка, конечно, где-то это нужно, безусловно, но когда разработчик на таком уровне программирует, я бы его так уже разработчиком и называл, а не Data Scientist.
Python в DS, если брать шире – это разработка в DS, тут мой коллега @tez_romach осветил некоторые вопросы на 2-ой неделе. Я бы сказал, что далее по книгам/курсам не продвинешься. Научишься разрабатывать по-нормальному на работе и (очень желательно) в сильной команде.
Избегайте ситуации, где вы единственный “аналитик” на всю команду. Думаю, Андрей @AndLukyane описывал свою историю тут на первой неделе. Ничего путного не выйдет, когда надо набираться опыта, а ты в одиночку ковыряешься. В этом плане mail.ru меня здорово прокачал.
Про SQL кратко – так просто его не ботай, пойди лучше спортом позанимайся. Освежить SQL можно уже перед собесом. Здоровее быть никогда не помешает, а ботая SQL лишний раз, ты и здоровее не станешь, и SQL не освоишь – все вылетит только так без практики. * картинка из ∏ρ؃uñçτØρ

Я и курсы специальные проходил по SQL, и архитектуры для Business Intelligence строил, и с ClickHouse/Teradata работал. Все тлен! Сейчас сходу, маркером на доске напишу максимум “SELECT * FROM fridge WHERE flour > vita_c”.
Но перед собесом лучше освежить, пойдет Kaggle Learn (базовый уровень) и олд-скул sql-ex.ru (средний/продвинутый). Хотя я никогда не буду SQL на собесе спрашивать, бред, уж извините. Про собесы – на пятый день этой веселой недели.
Буду немного разбавлять историями на смежные темы, эта будет около-SQL-ная (не очень, ну и ладно), а больше про всеми нами любимые галерки и бодишопы. Посмотрим, насколько убого длинная история будет выглядеть в Твиттере, threader нам в помощь.

В магистратуре я уже фултайм работал, может зря, если б мог, лучше б в ШАД поступил. Работал я на ноунейм галере в сфере BI, в принципе мне даже норм было, задача – спроектировать архитектуру, связать всякие физич./логические таблицы так, чтоб можно было отчеты дальше строить.
Ну как, офисный планктон, конечно, но не так тупо, как BI-отчеты набивать, некий простор для творчества и арх. решений даже был. И вот как-то меня вызвали после моего др – выбирай мол подарок. Чё? Ну да типа мы узнали, у тебя др был, вот - что угодно, вообще До 10 тыс. рублей 🤣
Ну я там что-то выбрал (GoPro, который в магаз так и не приехал). Это меня сдобрили, чтоб потом отправить в рабство в Пермь. И вот две поездки по 4-5 дней, наконец, на 3 недели. Чувак-финансист, курящий проект, сидел с нами же, и вот рукокрюк!
Как-то в смете не учел, что мы люди, и в выходные нам тоже надо было в отеле жить. Цифири стали не сходиться, и нам сказали, что мы работаем 21 день подряд, без выходных. Йес, сё!
Выглядело это так: отель “Прикамье”, в самом центре, упреков нет, в 7:40 утра нас забирает такси – еще темно, минус 28, ветрюга. Увозят нас в Эр-Телеком (это который провайдер Dom.ru), и до 20-21 вечера. Все солнце, что я видел – это 5 минут во время обеда.
Вечером возвращаешься в отель задолбанный, и тебе с ресепшн: “Отдохнуть не желаете?” :el_risitas: и так типа 21 день подряд. А я прилетел с коньками, клюшкой, планировал со шпаной в Перми в хоккей рубать.
Ну что, субботу первую я так отработал, а в воскресенье сказал про себя “идите все на!”, а лиду нашему сказал то же, но так чтоб не ссориться - и пошел реально рубать со шпаной в хоккей (уровень! 5-летний капитан “Молота” меня возил, как дитя), ибо жизнь больше, чем просто работа
Сейчас понимаю, что я просто лида подставил, но тогда считал себя человеком, борющимся с системой за свои права. В-общем, поработали мы так, проект не особо и взлетел, несмотря на то, что упахивались, оценки-бонусы за него были так себе.
Тогда я еще не знал, что моя будущая жена будет из Перми. И хорошо, что я этого не знал, т.к. в то время там помешал бы другой Юра :)
Испытал я на своей шкуре капитализм, увидел свой горизонт лет так на 30 вперед – и резко свернул, ушел на фултайм в ВШЭ в аспу по математике
Ни разу не пожалел, в то же время прошел Ына и решил, что буду заниматься ML. Морали не будет, но если чувствуете застой – меняйте работу!
a story by twitter.com/ykashnitsky (а то потом непонятно будет)
sudo @threader_app unroll
кто этими костылями умеет обращаться – помогите деду 😅
Cработал костыль threader.app/thread/1239580… но минуты две открывался, ну че, все из дома работают, good enough
Математика для Data Science – фух, обширная и холиварная тема. Мне нравится пафосная фраза, что “Data Science – это математика для бизнеса”. Но вот вопрос, а сколько реально математики в этой математике для бизнеса?

Честно: производную я брал всего один раз на рабочем месте (ну если Ph.D., конечно, исключить). И то локальная гипотеза, так, фигня, в прод моя производная не выкатилась. Но во-первых, есть такие случаи, когда без понимания математики действительно никуда.
Например, чтоб вам решить, какой алгоритм рекомендаций в проде крутить, вам надо поставить корректный эксперимент и… вам нужны A/B-тесты, а это статистика, может и не непосредственно, а косвенно, но всяко придется почитать статьи, поразбираться, и упс, в статьях будут формулы.
Во-вторых, жизнь – это больше, чем работа. Мы живем в классную эпоху, сетки что только не творят, и чтоб в этом разобраться, нужен матан. А разобраться в этом хочется, как минимум, желательно знать математику на базовом уровне, чтоб она не была ограничением в понимании вещей.
Тут можно возразить, что для получения business value не обязательно “понимать всякие там ганы”, но про это позже, о холиварах про математику/алгоритмы на собесах – в пятницу.
Для подготовки по математике для DS достаточно в принципе одной ссылки на MIT Open Courseware, еще некоторые я подбил все в том же посте в группе mlcourse.ai – vk.com/mlcourse?w=wal… но с тех пор появилось многое, на той же Курсере.
Отдельно отмечу ютуб-блогера 3blue1brown, парень автоматизировал такую непростую вещь как визуализация мат. понятий и очень доходчиво вещает про основы линейной алгебры. Честно, мне и после физтеха спустя лет дцать было полезно глянуть, как он иллюстрирует суть собств. векторов.
Вторник
Напоминаю, что это абсолютно типичный уровень развития датасаентистов. twitter.com/dsunderhood/st…
Для тех, кто настроен душевно похоливарить twitter.com/poebist/status…

Кстати, моя цель на первые 5 дней недели – рассказать, как готовиться к интервью на позицию Junior DS, а заодно вкратце про то, как некоторые из этих вещей реально используются на практике. В целом это по материалу видео “How to jump into Data Science” youtu.be/FGuGg9F2VUs
Про базовый курс машинного обучения.
Не претендую на обзор всего-всего, обсудим курс Andrew Ng, mlcourse.ai и специализацию Яндекса и МФТИ. А также, почему это хорошо, но в реальных приложениях будут проблемы, к которым курсы не готовят.

Если начинаете с нуля и хочется загореться красотой машинного обучения, то вам к Andrew Ng, очень харизматичный рассказчик, прекрасная структура, слайды, примеры – вроде бы курс-образец. И очень важно, что там активный форум, с любым, даже самым дурацким вопросом помогут.
Но курс устарел немного. И нет таких критически важных тем, как деревья решений и основанные на них лес и бустинг. К тому же Octave, бесплатный вариант MatLab, вот это боль. Хотя можно домашки и на Python делать.
Сложно не упомянуть mlcourse.ai – курс, который я тащил 3 года, намного более современный, чем курс Andrew Ng, бесплатный, море практики, соревнования Kaggle, порой примеры реальных задач приводятся.

Минус – сейчас он в self-paced mode, если ты усидчивый и готов много часов вложить в курс, то и многое приобретешь. В противном случае лучше проходить другой курс в большом сообществе (mlcourse.ai и был таким местом с 2017 по 2019, но бесплатные вещи все же не вечны)
Пожалуй, самая сбалансированная программа у специализации Яндекса и МФТИ. Получается да, реклама, но я хорошо знаю специализацию изнутри – и сам прошел, и финальный Capstone проект для нее разрабатывал. Особенно хороши 4 модуль по статистике и финальные проекты, четыре на выбор.
Насчет сообщества – не знаю, в начале было довольно активным (хотя ни в какое сравнение с курсом Andrew Ng и сессиями mlcourse.ai), сейчас, возможно, общение на форуме Coursera уже не такое оживленное.
Онлайн-курсы хороши, но очные, даже платные курсы не стоит сразу отметать. Там плюсы – нетворкинг, больше времени на каждого студента, и (главное!) можно пристать в лектору со своим вопросом/проектом. Рекламировать такие курсы не буду, но один с гантелькой особенно хорош :)
Ну и наконец, все это не покроет все-все вопросы, с которыми вы столкнетесь в работе. Как часто обучать модель заново, чтоб качество не проседало? Почему вдруг предсказания свалились преимущественно в один класс? Что делать, если в CV-задаче вдруг на фотках поменялось освещение?
На эти вопросы не найдешь ответы в книгах и курсах. Частично ты это доберешь уже на работе, и опять же важно попасть в сильную команду, с опытом. Но на многие вопросы так и не получится дать общий удовлетворительный ответ. Чаще что-то типа “От задачи/проекта/данных зависит”
Про курсы глубокого обучения. Из всего зоопарка выберем только три представителя – cs231n, dlcourse.ai и fast.ai

cs231n vs. fast.ai – это прекрасная иллюстрация дилеммы bottom-up или top-down. Начнем со стэнфордского курса cs231n "Convolutional Neural Networks for Visual Recognition" (я лично выбираю его).
Тут ты пойдешь с самых основ, сперва на NumPy реализуешь kNN для классификации картинок, увидишь, что ого, не так-то и просто написать эффективную векторизованную версию. Далее – тоже простые алгоритмы классификации и наконец многослойный перцептрон и свёрточные сети.
И так с самых низов – и до cutting-edge штук, таких как стилизация изображений или генерация картинок с GAN, почти все своими руками (хотя стэнфордская команда для очень многих примитивов делится своей реализацией). Всё по Фейнману "What I cannot create, I do not understand".

Минус – нет сообщества, курс чисто стэнфордский, приходится сбиваться в группки, ботать курс вместе. Например, так github.com/Yorko/stanford…
fast.ai, наоборот, привлекателен тем, что можно с помощью трех строчек кода запустить одну из последних сеток, допустим, семейства ResNeXt, на своей задаче классификации мопсов. А потом уже разбираться, как оно там под капотом устроено.
Из плюсов – большое активное сообщество и реализация всяких cutting-edge DL-эвристик в библиотеке fast.ai. Минус – ну извините, просто быдлокод. Слушаешь Джереми (лидера fast.ai), убеждаешься вроде, что он опытный разработчик, но...
потом пытаешься с fast.ai работать – и просто плюешься. “import fastai; print(fastai.version)” – когда это упало, надо было уже заканчивать. Беда с CI/CD, стилем кода, версионированием, да даже с названием переменных.
В-общем, курс fast.ai неплохо познакомит с текущим положением вещей в Deep Learning, там можно найти людей, что вписаться в какой-то классный проект, набраться опыта. Но писать код лучше просто на PyTorch, без fast.ai
Хороший баланс между cs231n и fast.ai – курс Семена Козлова & Co. dlcourse.ai, радует, что на русском. По теории и практике хорошо все, @sim0nsays прекрасно подает материал. Минус – сейчас курс, как и mlcourse.ai, – в режиме self-paced.
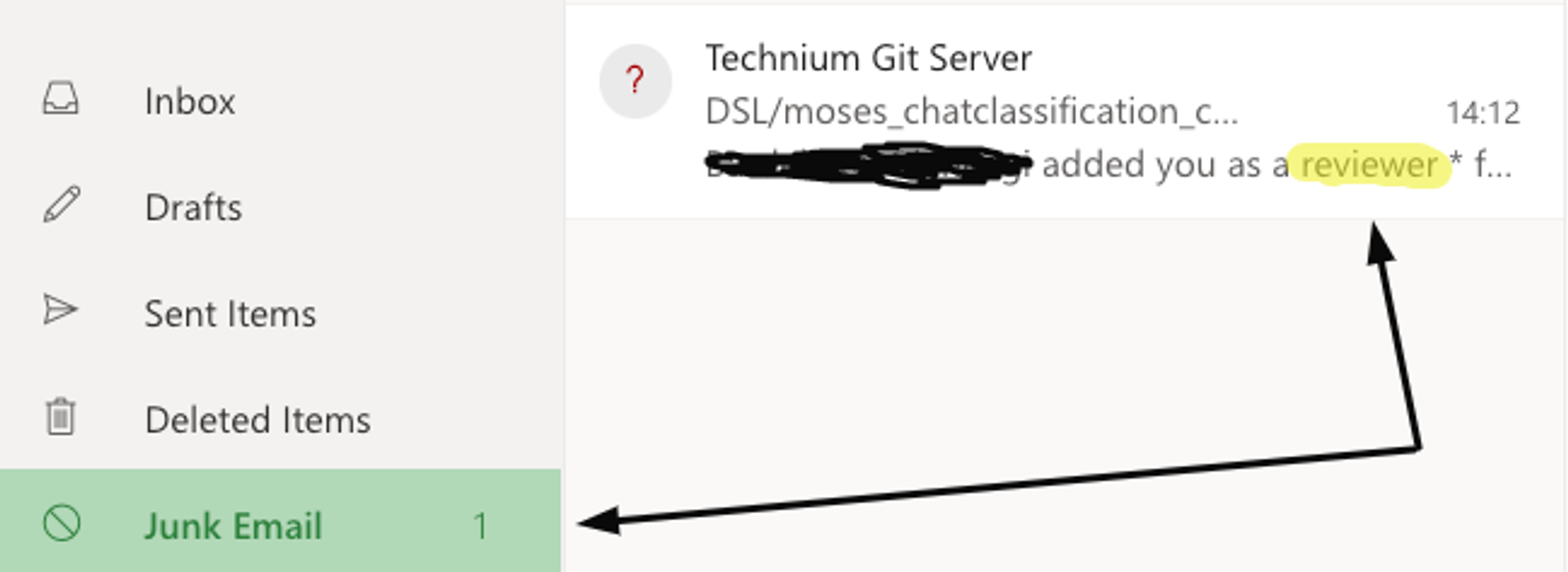
Про Deep Learning в реальных проектах рассказывать не буду, так как опыта у меня в этом не хватает. Но надо понимать, что DL-моделей в продакшене крутится сильно меньше, чем об этом говорят в Power Point слайдах.
Ну и с денежным выхлопом от этого все непросто, DL нашел свою нишу, а в остальном энтерпрайз-ML все же построен на бустингах и логрегах. Но так, чисто для себя следить за миром DL – очень круто (и опять вспомним тот тезис про пользу математики).
Среда
Ваш День Сурка будет не похож на вчерашний день благодаря этому твиттер-аккаунту. Сегодня и завтра – про pet projects и Kaggle. @AndLukyane про все это уже тоже рассказывал, так что будет еще одна точка зрения. А про Kaggle – немало минусов тоже.

Pet projects – это благо. Запереться в чулане и пройти всю обозримую часть Курсеры – недальновидный план, в нем не хватает командной работы. Pet projects могут быть и индивидуальные, и командные, но я как страдающий вымирающий экстраверт советую второе. И сейчас разверну мысль.

Если ты только погружаешься и готовишься к собесу на джуниор позицию, командный проект – это в миниатюре опыт реальной работы. С распределением ролей, лидерством, совместной работой с кодом (да, GitHub лучше всего на деле изучать), планированием и т.д.
Приведу сразу пример, у меня как раз такой потенциальный пет-проект простаивает.
Я как-то знакомился с SoTA в NLP, делал для одного стартапчика сентимент-анализ новостей о BTC.
Идея в том, что инвестор с утреца берет кофе, читает газеты и составляет некое своем представление о “тональности” новостей о крипте, это может косвенно влиять на его решения о купле/продаже битка.
Речь чисто о сентимент-анализе, прогноз курса битка гиблое дело (имхо) ни на какой стадии мной не рассматривался. Опуская детали, допустим, есть 50k новостей о крипте, часть из них размечена по тональности. Из этого может получиться неплохой сторонний проект.
Тут несколько интересных и не очень задач: обкачка новостных сайтов, разметка/доразметка данных (AWS mechanical turk / Толока), transfer learning с обучением языковой модели на корпусе этих новостей и дообучением (fine-tuning) классификатора, создание приятного веб-приложения.
При желании можно и с демо-версией production-системы поиграться, наладить CI/CD, автоматический деплой модели, покрыть код тестами. На деле изучить, как работают ML-системы, хорошо, если будет кто поопытней, перенять best practices.
В итоге и опыт командной работы будет, от кого-то точно чему-нибудь полезному научитесь. И на собесе можно взять и показать законченный работающий продукт, это позволит выделиться из толпы.
Добавлю, что в OpenDataScience ods.ai есть две релевантные инициативы – Machine Learning 4 Social Good (канал #ml4sg в Slack ODS) с рядом интересных проектов и #ods_pet_projects. И там, и там можно поработать с очень крутыми спецами.
Четверг
Сейчас со всей этой историей преподы сталкиваются с новой проблемой ухода в онлайн. YouTube дает стримить, если у тебя как минимум 1k подписчиков. В Казани есть один препод по ML & DL, чьи лекции достойны распространения. tinyurl.com/wtd947w история, как видите, не про деньги
Пока фоном растёт список +/- Kaggle, в качестве "cool story, Bob" поведаю о mlcourse.ai, хотя история скорее о синдроме самозванца и боязни повернуть карьеру тогда, когда что-то пошло не так. На англ, тут в виде скриншотов. Оригинал в слэке ODS tinyurl.com/sctdtlq

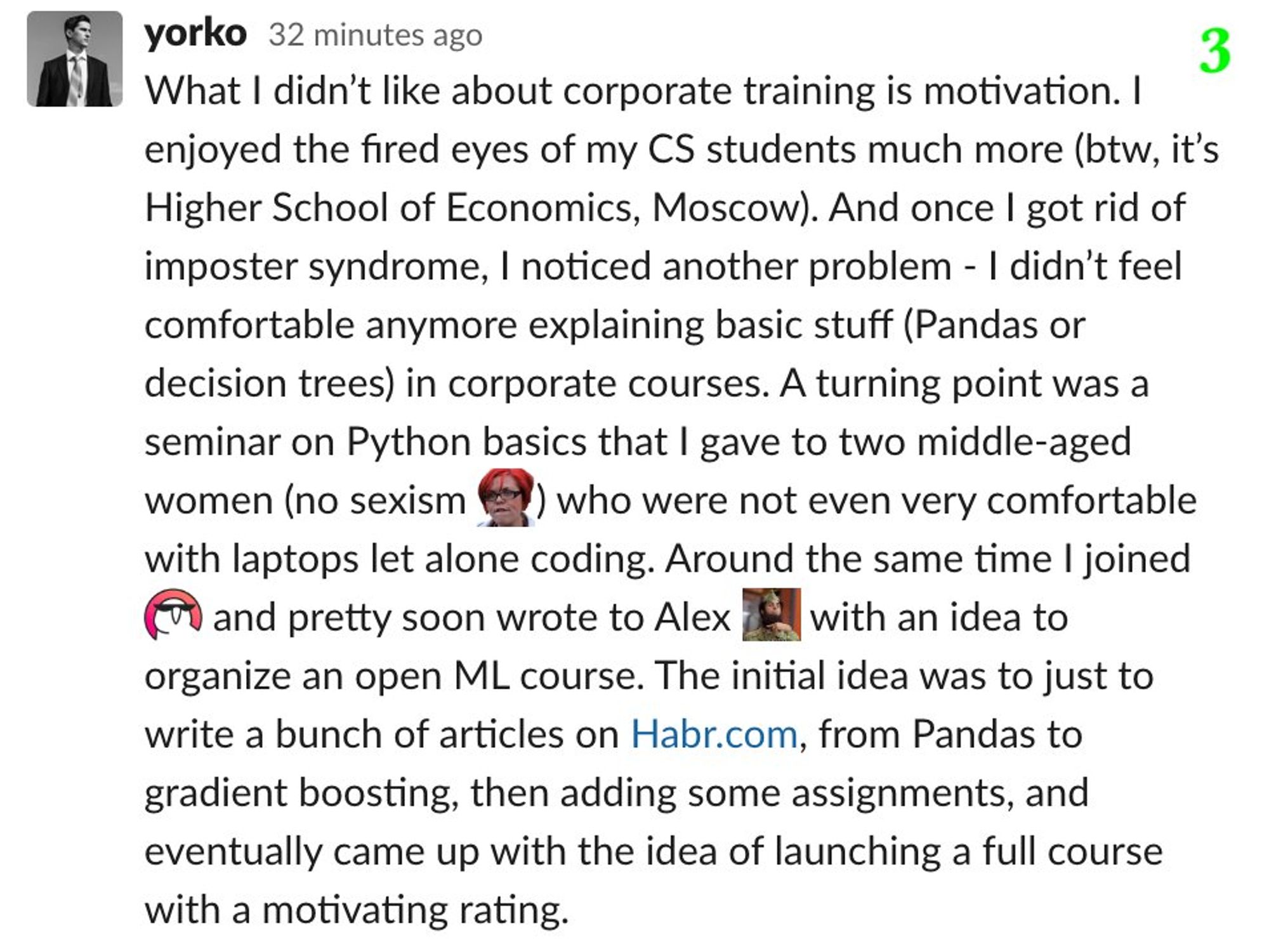
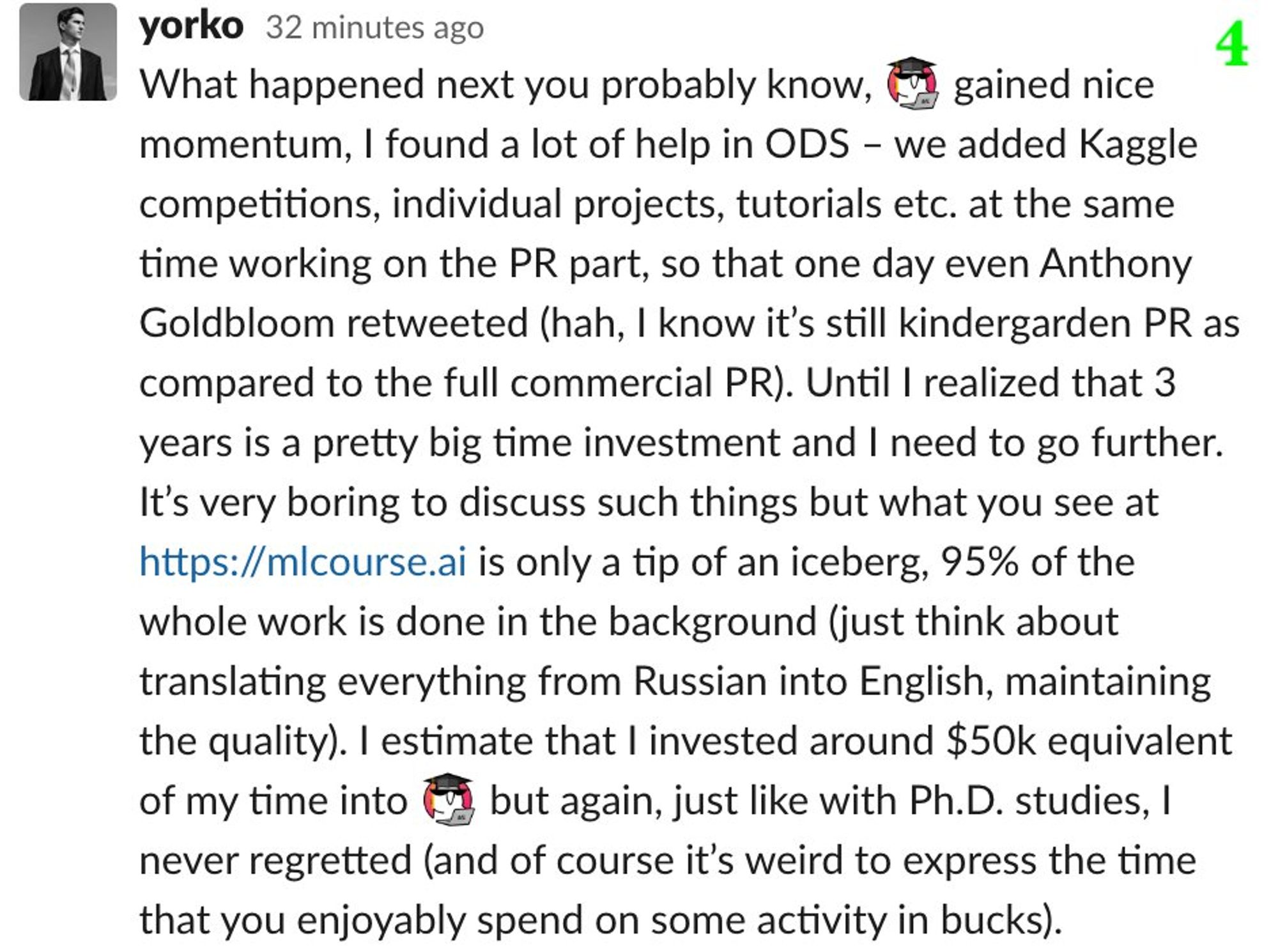
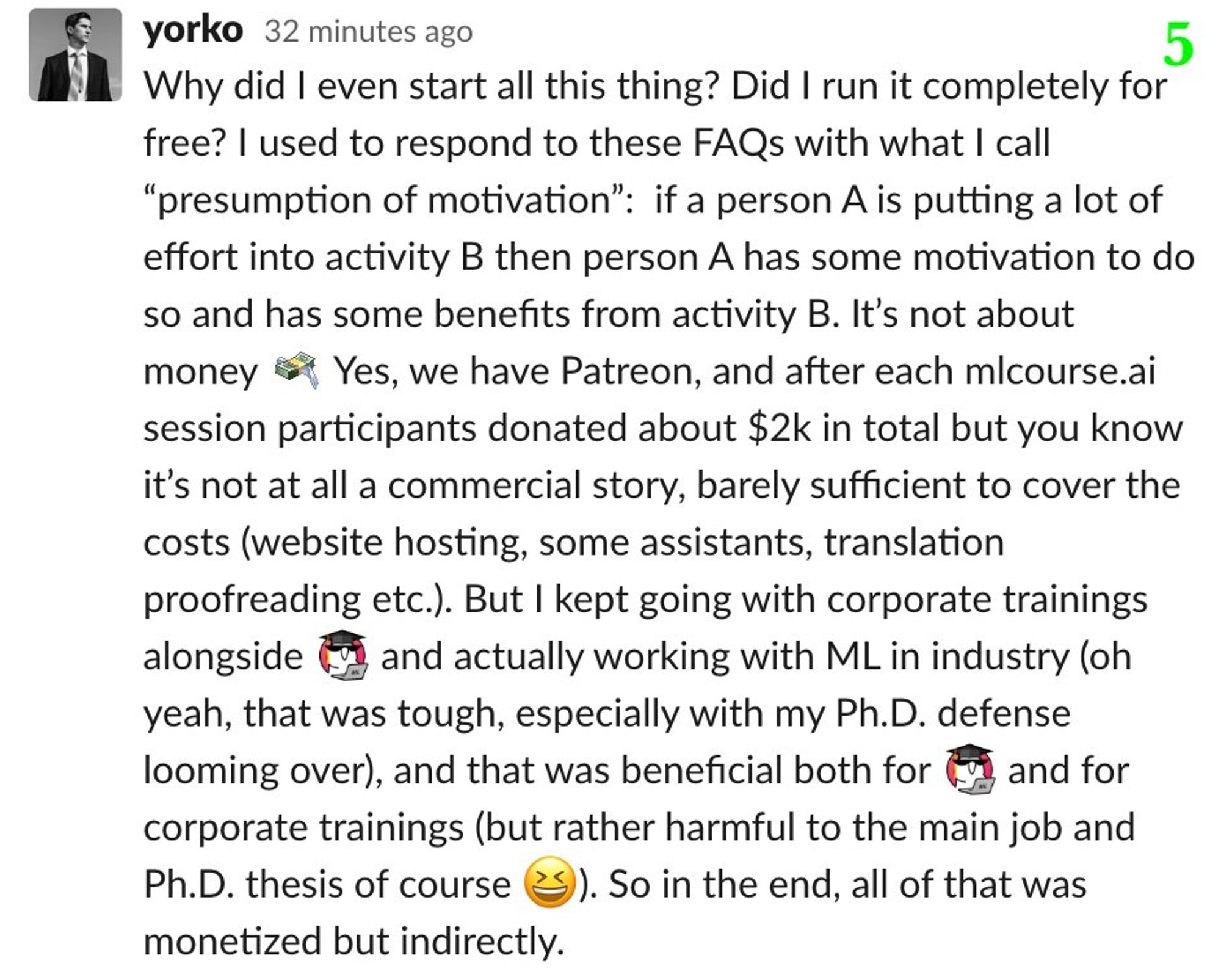
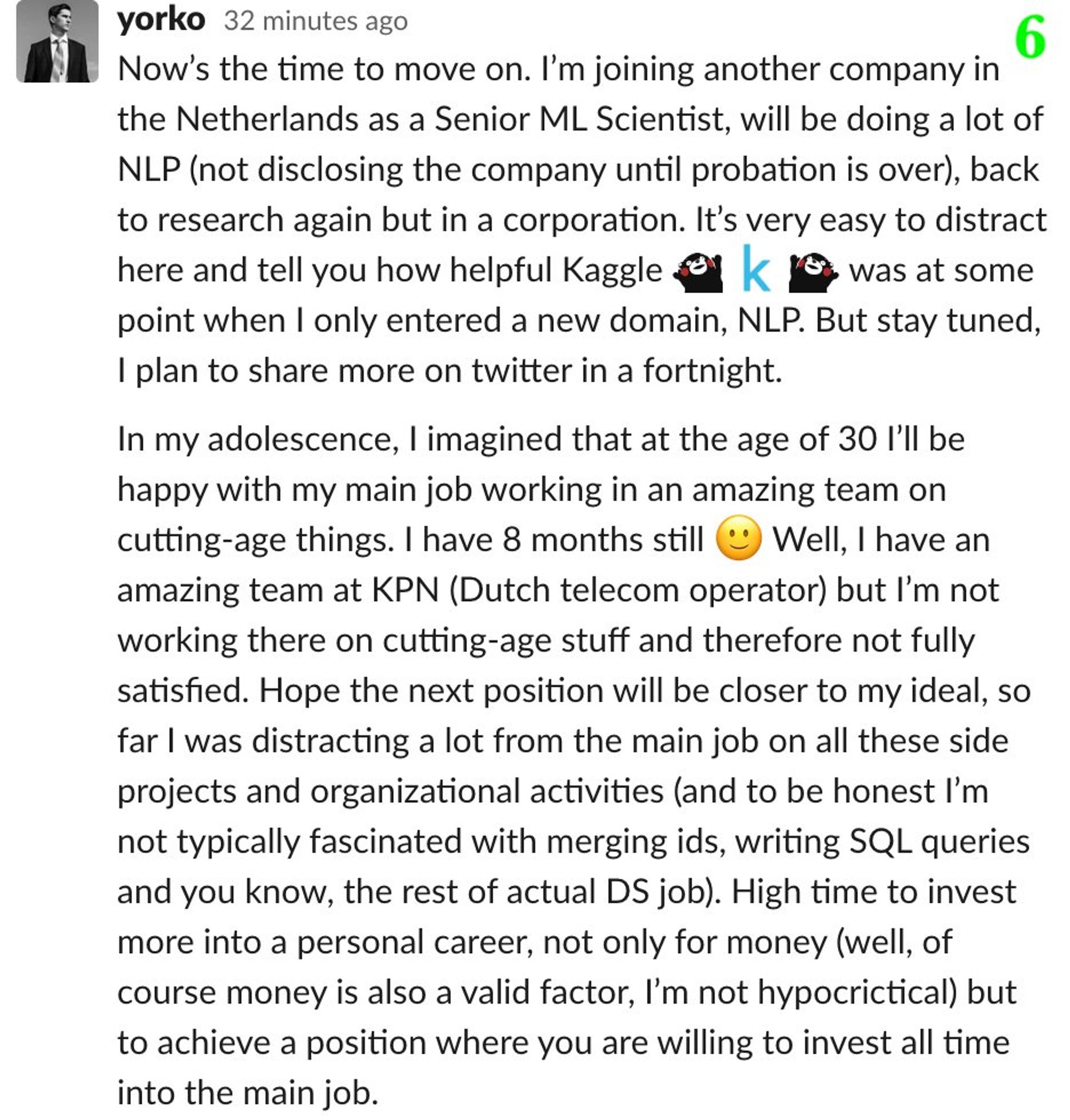
Давно хотелось поговорить про плюсы/минусы соревнований по Data Science (читай просто Kaggle, как копир – это ксерокс). Дождался, пока сам буду мастером соревнований, и можно начинать. Сначала плюсы, но потом и жестко критически пройдемся по кэгглу, получилось по 7 плюсов/минусов
#kaggle Плюс первый – команда.
Чуть ранее мы говорили о пользе pet projects, прежде всего социальной, как возможности поработать с классными спецами и перенять их опыт. Kaggle – это способ сделать то же в 4-5 раз интенсивнее.
Я уже немало всего организовывал, по большей части в ODS, и могу сказать, что мотивация фигачить зашкаливающая – именно в формате соревнований. Могут еще курсы сравниться, где тоже четкие дедлайны.
В противном случае, если цель отдаленная (типа порисечим transfer learning в NLP) или толком не поставлена (давайте применим ганы к фоткам ню) – то процесс будет идти ни шатко ни валко, слишком много усилий нужно от орга, чтоб не развалилось.
В команде Kaggle, напротив, обмен знаниями идет интенсивно, можно быстро освоить такие штуки, до которых иначе бы и не добрался. Да и само общение в команде как правило плотное, смех-шутки-праздничное настроение, отличный нетворкинг, потом кто-то тебя и зареферит условно в Fb.
#kaggle Плюс второй – “Большой человеческий гридсёч”.
Много копий сломано в спорах Kaggle vs. индустрия, индустрия vs. академия, kaggle vs. академия. Я бы относился к сообществу Kaggle еще и как большому механизму проверки научных идей.
К экспериментам из научных статей, честно говоря, доверия мало. Скажем, утверждает Джереми Ховард, что ULMFiT рвет трансформеры почти на всех задачах, верить-нет? А вот в сообществе Kaggle, да в академ-соревнованиях как-то трансформеры доминируют, и тут Ховарду я бы не верил.
И это касается почти любой новой идеи, в том числе из мира Deep Learning. Появилась, скажем, новая аугментация или новый LR scheduler, в статьях могут говорить что угодно, выжимать все соки из CIFAR и MNIST.
Но чтобы что-то закрепилось, нужна проверка временем среди практиков. А в этом Kaggle максимально эффективен. Каждый день появляются десятки новых алгоритмов/архитектур, и только некоторые проходят эволюционную проверку кэгглом
#kaggle Плюс третий – Трекинг экспериментов
Во время соревнований тестируешь множество идей, порой десятки. Волей-неволей задумываешься о каком-никаком трекинге этих идей и соответствующих экспериментов.
Мы сейчас не сравниваем это с полноценным воспроизводимым production-ML и соотв. инструментами (MLFlow, DVC и т.д.), нет, речь просто о переходе от кучки Jupyter ноутбуков к какой-то саморганизации в виде гугл-дока со ссылками на эти Jupyter ноутбуки, данные, сохранённые модели.
Так чтоб можно было взять и быстро воспроизвести эксперимент. Я не говорю, что Kaggle сразу научит тебя делать это правильно, но хотя бы заставит думать в нужном направлении. По себе знаю, в академии, как правило, беда с воспроизводимостью экспериментов.
#kaggle Плюс 4-ый – “Быстрый старт”
Когда ты погружаешься в новую область, например, в NLP, Kaggle может тебя прокачать очень быстро. У меня все так и было, я влился в соревнование по NLP.
Начал анализировать Кернелы признанных спецов, узнавать какие-то хаки, читать статьи, которые все на форуме обсуждают во время соревнования – и процесс пошел, по ощущению раза в 2-3 быстрее, чем если б я не кэгглил.
#kaggle Плюс 5-ый – Прототипы
Kaggle Notebooks – свои и чужие – это отличный “резервуар пайпланов”. Если мне сейчас понадобится обучить, условно, char-RNN для классификации твитов, я полезу не на StackOverflow, не на Coursera и скорее всего даже не на GitHub, а именно на Kaggle.
Лучше всего набрать свою коллекцию пайплайнов под разные задачи. Но если нужно что-то новое, с чем раньше не сталкивался, например, что-то из мира голосовых технологий (допустим, классификация речи по языкам), я первым делом посмотрю Kaggle Notebooks из релевантных соревнований.
Хотя, конечно, Kaggle Notebooks будут и в списке минусов, уж слишком много всякого шлака публикуется, надо аккуратно выбирать.
#kaggle Плюс 6-ой “Кругозор в ML”
Что я знаю о конечных автоматах и олдскульных “AI”-системах на правилах? Ровным счетом ничего. Но если я впишусь в соревнование “Abstraction & Reasoning Challenge”, то узнаю многое, причем не только в теории, но и своими руками что-то покручу.
Так вещи и запоминаются намного лучше (тут нужна ссылка на PubMed). И так с любой темой, будь то GANs, deepfake, табличный AutoML или Question Answering. Ничего не знаешь в теме – пошел на Kaggle, быстро разобрался в основах.
Впрочем, слово “кругозор” тоже появится и в списке минусов :)
#kaggle Плюс 7-ой “Хаки”
О многих хаках я узнал только благодаря Kaggle, это и adversarial validation, и всякие Group-KFold для корректной валидации и то, что препроцессинг текста надо адаптировать под предобученные эмбеддинги типа Fasttext, и eli5 для интерпретации моделей.
Да даже всякие удобные мелочи типа tqdm.pandas() и progress_apply, чтоб не скучать, пока обрабатываешь свой датафрейм. Счет идет на десятки хаков, многие их этих хаков потом используешь в ежедневной работе.
Пятница
Чукча не читатель, чукча – писатель. @AndLukyane уже на 1-ой неделе прошелся по плюсам/минусам кэггла, так что я взял set difference, и осталось 5 минусов (плохой код и перекос в моделирование – это опускаем). Но некоторые из них очень существенны, хочется обсудить.
#kaggle Минус 1-ый – Подсаживает
Да, кэггл реально подсаживает, надо это признать.Это может быть и гештальт “выбить мастера в соревнованиях”, или, как у меня, как у kaggle-топов - попасть/удержаться в топ-N. Есть и заложники амбиции стать grandmaster.

Нездоровая геймификация проявляется и в мелочах, типа накруток голосов за пресловутые Notebooks с откровенно помойным кодом.
При желании получить медальку у тебя есть риск тратить свое время на полною хрень. Все эти тюнинги параметров, стекинги/блендинги – занимают кучу времени и не дают особо прироста знаний, ладно, первый раз дают, но в (N+1)-ый раз это просто по сути прожигание жизни.
И тут вступающих на этот нелегкий путь хочется призвать максимизировать свои знания, получаемые на кэггле.
Этим коварны табличные соревнования с кучей признаков, часто еще и анонимных. Видно, как начинающие (да и порой продолжающие) убивают просто уйму времени на очистку этих признаков от всякого мусора и прочую возню в данных. И тут счет может идти на десятки часов.
Подумайте просто, насколько много знаний вы приобрели, если взяли грязный признак “city” и пофиксили в нем все опечатки. При этом каждый раз оглядываясь на лидерборд.
Опасность в том, что можно забраться в соревновании высоко, допустим, в серебряную зону (скажем, на 100 место) за 3 недели до конца (что для совсем начинающего неплохо) и потом выгрызать какие-то 5-6 знаки после запятой за счет огромного стекинга. Вот на что уходят десятки часов
Да еще и риск огромного разочарования при шейкапе (результаты на приватной части обычно отличаются от результатов на публичной части рейтинга). В-общем, максимизируйте знания, старайтесь не выгрызать результаты любой ценой. И да, все это сложно соблюдать в режиме гонки.
#kaggle Минус 2-ой – Здоровье, work-life balance, кругозор
Многие окунаются в Kaggle, уже работая фултайтм или даже имея вдобавок учебу/аспирантуру/подработку. А все же жизнь – это что-то большее, чем работа и уж точно куда большее, чем кэггл.
И тут та самая картинка-тизер

Я лично с большим удовольствием слезаю с иглы кэггла, поскольку в этих днях/вечерах напролет здоровье проседает. Вот реально сесть, задуматься, спланировать – и оставить время в жизни на спорт. Точно не пожалеешь! Я так и сделал, когда самый кипиш был.
Не говоря уже о ночах, многие кэгглеры реально сильно жертвуют сном, особенно перед дедлайном. Почитайте толковые материалы о пользе сна, жертвовать сном – значит жиреть и становиться менее продуктивным. Неплохое признание Kazanova делает в подкасте ChaiTimeDataScience
Я, помнится, задумался над своей адекватностью, когда вечером с субботы на воскресенье смотрели фильм, романтика, все дела, свечи. Но был дедлайн на кэггле, и где-то в 4 утра я побежал делать какие-то финальные посылки :el_risitas:
И в целом закапываться в один только ML, когда вокруг целая жизнь – так себе решение. Что есть вирус? Каковы признаки науки по Попперу? Почему “Черный квадрат” – это революция в искусстве? Ну вы поняли, что можно делать вместо выстраивания очередного трехэтажного стекинга.
#kaggle Минус 3-ий – Гонка
Да, на то оно и соревнование. Я замечал, что некоторые темы пролетали незаметно. То есть взял какую-то модель, запустил, как черный ящик, сработало – хорошо, не так нет, следующий эксперимент. А толком посидеть вникнуть времени нет.

Я бы с удовольствием прошелся по соревнованиям, в которых сам же и принимал участие, чтобы лучше "понять то что понято" – не спеша, с чистым кодом. Но жизнь тоже гонка.
Кстати, этим хороши выступления/преподавание. Вот уж когда реально надо понять то что понято.
#kaggle Минус 4-ый – Упование на удачу
Вскочить за два часа до конца соревнования, стащить топ-кернел, подшлифовать чутка и ждать своей медальки – is this learning?

Признаюсь, одна из серебряных медалек у меня ровно так и добыта, еще до того как я окунулся в NLP. Причин такого поведения как минимум две – для некоторых топов общего рейтинга это поддержание этого самого рейтинга (хотя куда лучше брать пример с dott & Singer, Dieter или CPMP)
Перечисленные благородные доны выкладываются на полную в каждом соревновании, в которое заходят. Хотя еще лучше Dmytro Poplavskiy, только золото, но это редкость. Но призыв понятен – выберите соревнование и окунитесь в него с головой, не надо тащить несколько параллельно
Это отчасти исповедь, так как я сам поначалу поступал ровно наоборот :) поначалу мне еще казалось, что вот я сейчас запилю autoML, когда еще такого хайпа вокруг не было. Позже я понял, что это был детский сад :)
И вторая причина упования на удачу – “изи-голд”, особенно в соревнованиях с сильным ожидаемым шейкапом. Что лицемерить – каждый хоть раз хотел халявно отхватить медальку. На удачу надейся, но тем не менее имей долгосрочную стратегию – накопление знаний и опыта.
#kaggle советы. Ладно, минусов насчитал 4. Ну и хорошо, все же мы Kaggle тут обсуждаем не просто так, плюсов больше. И я дам некоторые советы начинающему кэгглеру, немного в кучу, более стройный гайд – на хабре tinyurl.com/rre8558

- Избегай соревнований с кучей анонимных признаков
- Не окунайся в соревнования с первого дня. И баги еще найдут, и поделятся такими идеями, которые изменят ход всего соревнования
- Начинай в одиночку, читай все главные дискуссии, просматривай код (Notebooks), подмечая идеи
- Не впадай в сильную зависимость от чужого ноутбука, в нем и ошибки могут быть, и плохой код отнимет много времени на усваивание/рефакторинг/дополнение
- Не распыляйся сразу на все задачи – таблички, CV, NLP. Выбери актуальную для себя тему, желательно ту, что с работой связана
- Не больше одного соревнования за раз!
- Несколько соревнований лучше пройти в одиночку, накопить опыта/знаний, “набить пайплайны”
- Как наберешься опыта, поучаствуй в команде, это уникальный опыт
- Но не объединяйся в команду слишком рано (по ходу соревнования), будет неприятно видеть, как энтузиазм падает, есть риск “протащить балласт”
- Еще раз: максимизируй знания, не медальки. Медальки позже придут. Да, терпения нужно много
- И так шаг за шагом, если не будешь грохать часы и дни на хрень и не выгоришь, – то неплохо накопишь опыт и увидишь, что его хватает на довольно уверенное серебро.
А там и до золота недалеко, но конкретно сложно говорить, уже роль удачи сказывается. Не сдавайся! В конечном счете, ты всегда побеждаешь, получая знания (опять же, если следуешь советам и не смываешь своё время в трубу, очищая руками 39 признаков)
Суббота
Истории про собеседования и алгоритмы/брейнтизеры/”гномики” я начну с описания самого странного собеса в моей жизни. Компания НИКС (компьютеры и комплектующие) – та самая, где получаешь штраф в 0.5 дневного оклада за опоздание даже на 1 минуту.

Говорят, у них в совете директоров был выпускник МФТИ – своего рода технократ: считал, что если все сотрудники будут шарить в математике, физике и программировании, то все будут ответственны, честны, продуктивны, 5-летка за 3 года и вообще удой коров x4.
А поэтому и собесы были... физтеховские. Независимо от желаемой позиции. Хотя начинался этот марафон с задания на внимательность. Перед тобой лист A4 с тремя столбцами, в каждом около 60-ти 7-8-значных чисел. Надо просто в каждом столбце посчитать сумму, калькулятор прилагается
На это уходит около 35 минут, после которых перед глазами уже все плавает. Рядом со мной женщина пришла уборщицей устраиваться, держала калькулятор чуть ли не в 1.5 метрах от себя из-за дальнозоркости, бубнила вслух каждую цифру, потратила 1.5 часа – и все три столбца неправильно
Далее матан, физика и гномики (гномиками будем называть далекие от практической пользы задачи типа этой habr.com/ru/post/190242/, ставшей классической). С матаном проблем не было, уравнение Шрёдингера даже вспомнил, а про похожих гномиков рассказали, вроде одного только не одолел.
Типичные: есть там остров, бревно, по нему может с фонарем пройти только один человек, папа за 2 минуты, мама за 3., и т.д., за сколько все семейство переберется. Рядом чувак на программиста собеседовался, слышал, как он тоже мучился, Шрёдингера вспоминал.
В конце 5-го часа донесся громкий мат и стук в дверь – это бомбануло у амбала, который на грузчика пришел устраиваться. В-общем, взяли. А дальше философия компании такая: каждый сотрудник должен пропахать как минимум 2 недели, “похавать жизни с самого низа”
Физтехов потом брали уже учиться прогать и далее якобы быстрый карьерный рост. Я бегал между складом и магазином с флешками, наушниками и прочей хренью. Публика конечно... базарчики только про компы, гамы и девах. Ну и мы, физтехи :)
На 3-ий день все должны были сдать анализ мочи и крови, наркоманов отлавливали. У моего друга типа нашли следы амфетамина в крови, уволили и еще фотку на доску позора повесили.
Дело было после 1-го курса, побегал я так 5 дней - и погнал в Карелию на байдарках гонять. Не пожалел.
История вроде и не про Data Science (хотя гномиков могут задать и на DS-собесе). Просто задуматься о том, на какие унижения ты готов ради работы.
По поводу «гномиков», и чем это отличается от вопросов по алгоритмам и структурам данных.
Пример “гномика” – докажите, что между 100500 и Гуголплекс не менее Гугол простых чисел. Посыл мой ясен: спрашивать такое на собеседовании – как минимум, спорно.

Все это весело, но заниматься этим можно в рамках кружка-квадратика юных математиков, чтоб тебя называли сыном маминой подруги. Ну и для персонального развития. К карьере SWE/DS никакого отношения не имеет, даже Гугл подтвердил, что корреляции riddle performance с KPI нет.
Если тебе задают гномика на собесе, я бы советовал вспомнить, что за компания. Если The Only One – ты должен был знать заранее и ботать этих самых гномиков. Если нет – вежливо прощаешься, запасные варианты всегда должны быть.
Алгоритмы и структуры данных – это совсем другое, основа основ для любого человека, пишущего код. Хочется пояснить, почему это не надо путать с гномиками типа “почему люки круглые” или "реализовать ROC AUC на SQL"

Это как начитанность. Ты ж наверняка человек начитанный, но будет сложновато в целом сформулировать, зачем это нужно, на книги тратить время. Но в случае Algos & Data Structures даже все легко примерами и опытом подкрепляется.
Надо тебе, скажем, много раз в цикле проверять, лежит ли что-то где-то. Если ты это в список положил и 100500 раз в него смотришь, придется идти на SO и жаловаться на бигдатку.
А если понимаешь, что lookup в множестве за константное время происходит (а в списке – за линейное), то положил все в множество и радуешься жизни.
Иногда такие "мелочи" приводят и качественным изменениям, не только количественным. Мои коллеги-аналитики как-то вместо Беллмана-Форда запускали Дейкстру для каждой пары вершин и не могли масштабироваться ("памяти не хватало"). Примеров много на самом деле.
Пример вопроса на собесе: "реализуйте Python класс Очередь с такими-то баковыми операциями"
Если ты подобные вопросы помечаешь у себя в голове тегом «гномик» – это самообман. Можно идти делать свой фит-предикт и ждать, когда AutoML вытеснит тебя из этой профессии.
Чтобы изучить алгоритмы и структуры данных, стоит пройти пару фундаментальных курсов, например Robert Sedgewick и/или Tim Roughgarden, практика на LeetCode тоже не помешает.
Решение алгоритмических задачек, требующих написание кода, часто так и называют литкодингом, хотя появились ресурсы и поинтересней типа Interviewbit (но по своему опыту тут ничего не посоветую). Еще полезно прочитать “Cracking the coding interview”.
В целом, в контексте собеседований, я призываю иметь фундаментальное понимание алгоритмов и структуры данных, не бояться с нуля написать, скажем, реализацию алгоритма Дейкстры на Python или структуру Очередь. Не по памяти написать код, а именно порассуждать и реализовать.
А тратить ли часы на литкодинг, чтоб уметь за 2 минуты написать любой базовый алгоритм – это уже твое решение, зависит от той компании, куда готовишься, да, в FAANG это все еще требуется. Все последние собеседования, которые я проходил, были без литкодинга, отчасти, это мой выбор
Про поиск работы за рубежом. Да, прямо сейчас не очень актуально, но все же, надеемся, хотя бы через год все вернется на круги своя. Две неожиданно важных вещи (помимо самой работы): английский и деньги на переезд.
картинка из паблика VK vk.com/weirdreparamet… damned GDPR!
Сперва база: работа за рубежом (по крайней мере, в Европе) ищется в основном на сайте Glassdoor, там же можно и нужно читать отзывы о компаниях, анализировать статистику зарплат сотрудников этих компаний.
Но не только Glassdoor-ом единым, даже на LinkedIn можно вакансию найти. И в OpenDataScience в канале #_jobs проскакивают DS-вакансии в США и Европе.
Для соотнесения зарплаты с ценами на проживание, продукты и в целом на жизнь – есть сайт Numbeo, можно прямо взять и сравнить, например, N рублей в Москве с M евро в Берлине.
Как только ты готов, прошел базовые курсы, поработал год джуном, есть что показать (Kaggle/pet projects) и хочется повидать мир – подключай связи, хорошо, если тебя кто-то зареферит. Этим особенно крут OpenDataScience как социальный капитал.
Очень важно иметь разговорный английский хотя бы на уровне спокойной беседы по скайпу/слэку/зуму, в том числе с носителями языка.
Я провел немало собеседований, вот реально очень обидно, когда крутой спец, условно, из Восточной Европы, не проходит тупо из-за недостаточного свободного владения английским. Правда жаль. Ботай английский!
Как банный лист, приставай к знакомым, переехавшим в выбранную тобой страну X. На хабре тоже легко найти истории, как кто-то навострил лыжи и обосновался в стране X, можно и на Хабре в личку писать.
Когда будешь торговаться с будущим работодателем, обязательно настаивай на relocation bonus, в моем случае это было 5k евро. Также перед переездом в Нидерладны я за месяц заработал больше трех своих месячных окладов… и (внезапно!) было туговато.
Поначалу возможны такие приколы: мой HR не загрузил какой-то документ в системе – и у меня первое время налог считался по максимальному рэйту (52%) вместо прогрессивного.
В-общем, как бы цинично сейчас это ни звучало, но нужны запасы, чтоб переезд был не слишком стрессовым. Посуетиться и так придется, еще не хватало на мель сесть.
Это из ключевых вещей про переезд. Если я что-то забыл – спрашивай. Завтра еще изложу свою историю про чух-чух миграцию в Нидерланды. А, и DevOps упомяну, все более и более важным требованием в DS становится.
Воскресенье
DevOps – это упрощенно говоря, все техники разработки, направленные на поддержание жизненного цикла продукта (ПО). Главное, что хочется сказать – от дата саентистов все чаще требуют навыков разработки, не только фит-предикт, так что разбираться в основах DevOps нужно.

Средства DevOps включают в себя инструменты для контроля версий (GitHub), системы автоматического тестирования (например, Jenkins), контейнеризации (Docker) и оркестрирования ресурсов (Kubernetes) и т.д.
Тут не так много специфичного для DS, речь скорее о разработке. Но вовсю развиваются и системы контроля версий модели (а-ля MLFlow). К сожалению, с контролем версий данных не понятно, что делать, (да есть Data Version Control, DVC, но не все проблемы решает), если их реально Tb
Посыл такой: разберись хотя бы с GitHub и Docker. Всегда, когда ты сотрудничаешь с другим разработчиков, тебе нужно работать с GitHub, и если кто-то за тобой будет, условно, мержить ветки, это очень раздражает.
То же с Docker, чуть только речь пойдет о production, без докера не обойтись. На самом деле много без чего не обойтись, но если пришел на собес на позицию Junior DS, имей представление хотя бы о GitHub и Docker.
И вообще сейчас локальный тренд на ML Engineer, говорят даже, что на LinkedIn про себя выгоднее писать как ML Engineer, а не Data Scientist.
В целом требования к Data Science со стороны бизнеса растут, зарплаты постепенно устаканиваются, и часто от DS команд требуется и навыки создания/поддержания бизнес-продукта. А для этого нужны скилы нормальной разработки, то есть в том числе DevOps.
Конечно, может быть и вроде бы идеальная для дата саентиста ситуация: написал скрипты для извлечения данных, прочий ETL, запилил в Jupyter модельку, отдал pickle-файл и Readme команде разработки, а те уже заботятся о всем остальном продакшене. И где-то даже такая схема работает.
Но я бы не советовал на это рассчитывать. Твоя ценность на рынке будет сильно выше, если разрабатывать неплохо умеешь и поддерживать модель в продакшене (логи/алёрты вот это все). Да и если в продакшн совсем не умеешь, будешь раздражать команду девелоперов.
Запилишь catboost, условно, на CSV в 2 Mb локально тащит, а в проде по разным причинам по памяти упадет. Ну и вообще все это выводит на философскую беседу, что скоро и “пузырь лопнет”, и AutoML будет базовый фит-предикт делать, а вот базовые навыки разработки никогда не устареют.
Про мой переезд в Нидерланды, собеседования и работу. В конце еще накидаю скриншотов уже описанной истории про плюсы/минусы жизни в Нидерландах. На сей раз скриншоты хотя бы с текстом на русском :)

Сначала, конечно, с букингом собеседовался, если сидеть где-то вдалеке от Амстердама и просматривать нидерландские компании, то Booking.com заметнее всех. В том числе и тем, что у них годный технический блог.
Там онлайн-тест, его я написал лучше всех за 2 года, по словам эйчара, но дальше не прошел. Там дальше удаленно с двумя DS-ами, описываешь подробно свой проект, причем они тоже любят cool story так чтоб с завязкой, кульминацией и развязкой.
Потом кинули бизнес-кейс, и я лажанул. “в поисковой выдаче букинга у некоторых предложений есть пометка good deal. Как это определить и как предсказывать?“. Я там лик допустил – у меня оценки отеля были и в определении таргета, и по ним же я предсказывал good deal. Бывает 😀
Потом я нашел чудо-вакансию букинга – поднимать с нуля Neural Machine Translation, но решил, что слабоват для нее, так и есть. Это им надо было кого-то, скажем, из Я.Перевода переманить. Вроде у них даже зашел Перевод, хотя с нуля его делать – кажется диким решением.
Далее меня зареферили в eBay, и поехал я к ним на онсайт. Спрашивали только по проектам, попутные вопросы на здравый смысл. Но у них что-то мутное, подковерное, отшили с левой отмазой, что и так по резюме было понятно.
Босс, которому меня зареферили, был в отпуске, они как-то без него побыру решили меня не брать. Есть подозрения, конечно, почему и как, но скажу, это из-за того, что я умничал, про рисерч там спрашивал… Ну и ладно – сказали, рисеча у них никакого нет, невыгодно. Мне не подошло.
С телеком-оператором KPN все получилось очень быстро, по скайпу. Опять же никаких гномиков, даже никаких толком вопросов – просто еще раз подробно рассказал про свой опыт проектов. С командой очень повезло, по человеческим качествам, по юмору – все топ.
Только компания все же очень голландская, где-то традиции все еще, условно ad hoc запросы бизнеса и эксель. Мы по сути R&D команда, море свободы, но все же есть ощущение, что DS для компании типа KPN – это пока как крутая тачка, которой непонятно как управлять.
Вот на днях выхожу на новое место, ближе к рисёчу опять, Senior ML Scientist c уклоном в NLP. Пока не буду говорить, что за компашка, потом все равно мой LinkedIn расскажет.
Тут, кстати, еще раз хотелось бы отметить социальный капитал ODS. На новую работу меня наняли в обход публично оформленных вакансий – чисто DS VP написал мне email :)
А дело все в том, что в рамках Amsterdam Data Science я с коллегой запустил сотрудничество по transfer learning в NLP, по сути хотелось просто научиться обращаться со всеми этими бертами и прочими SotA NLP моделями.
Пошло вяловато, в Нидерландах никто особо не будет что-то делать в будни вечером или в выходные, и тогда я нашел немало народу, просто кинув клич в ODS. И в целом моя NLP-активность оказалась заметно, поэтому и с вариантами работы интересней.
Все это не только к тому, чтоб похвастаться, но и к тому чтоб использовать вовсю социальный капитал Open Data Science.
Теперь про минусы/плюсы жизни в Нидерландах (именно в таком порядке), ссылка на пост в Slack ODS tinyurl.com/vpjysou (если откроется)

Минусы
- Расслабленность
- Отсутствие мотивации пахать, зп синьоров/лидов не так велика
- Рынок Data Science не такой разнообразный и богатый, как в Москве
- Сторонние заработки, свободные деньги

Минусы
5. Медицина (также в списке плюсов)
6. Плохой сервис, обслуживание в кафе
7. Новый иностранный язык (также в списке плюсов)
8. Дорогие детсады

Плюсы
- Налоговые поблажки
- Work-life balance, отсутствие стресса на работе
- Все хорошо говорят по-английски
- Безопасность, честность, доверие

Плюсы
5. Ипотека
6. Погода
7. Спасут при серьезном заболевании
8. Открыта вся Европа

Плюсы
9. Возможность получить гражданство через 5 лет

Вот и всё, с вами на этой неделе был Юрий Кашницкий twitter.com/ykashnitsky (думаю повещать примерно о том же, но на англ., пока можно не подписываться), в Slack yorko. В этом метатреде – ссылки на главные посты за неделю. Если хотите стать автором недели, пишите Виктору @tiulpin
Про SQL кратко – так просто его не ботай, пойди лучше спортом позанимайся. Освежить SQL можно уже перед собесом. Здоровее быть никогда не помешает, а ботая SQL лишний раз, ты и здоровее не станешь, и SQL не освоишь – все вылетит только так без практики. * картинка из ∏ρ؃uñçτØρ https://t.co/NgSSC0aszx
План недели, интро twitter.com/dsunderhood/st…
Тред про Python twitter.com/dsunderhood/st… почему тебе в Data Science скорее всего не нужен C++ и про ограничения курсов
О том, почему не надо просто так, для забавы ботать SQL twitter.com/dsunderhood/st…
Математика для Data Science – фух, обширная и холиварная тема. Мне нравится пафосная фраза, что “Data Science – это математика для бизнеса”. Но вот вопрос, а сколько реально математики в этой математике для бизнеса? https://t.co/qAUFaqUycp
История о корпоративном рабстве и карьерном повороте в нужный момент twitter.com/dsunderhood/st…
“Data Science – это математика для бизнеса”. twitter.com/dsunderhood/st… а сколько реально математики в этой математике для бизнеса?
Pet projects – это благо. Запереться в чулане и пройти всю обозримую часть Курсеры – недальновидный план, в нем не хватает командной работы. Pet projects могут быть и индивидуальные, и командные, но я как страдающий вымирающий экстраверт советую второе. И сейчас разверну мысль. https://t.co/b9S589fUzO
Про курсы глубокого обучения twitter.com/dsunderhood/st… cs231n, dlcourse.ai и fast.ai
О пользе pet projects twitter.com/dsunderhood/st… Прежде всего как о возможности поработать с крутыми спецами
Пока фоном растёт список +/- Kaggle, в качестве "cool story, Bob" поведаю о mlcourse.ai, хотя история скорее о синдроме самозванца и боязни повернуть карьеру тогда, когда что-то пошло не так. На англ, тут в виде скриншотов. Оригинал в слэке ODS tinyurl.com/sctdtlq https://t.co/RzQAqXN0FM
Об истории mlcourse.ai, о синдроме самозванца и боязни повернуть карьеру тогда, когда что-то пошло не так twitter.com/dsunderhood/st…
#kaggle Плюс 4-ый – “Быстрый старт” Когда ты погружаешься в новую область, например, в NLP, Kaggle может тебя прокачать очень быстро. У меня все так и было, я влился в соревнование по NLP.
Плюсы Kaggle:
команда twitter.com/dsunderhood/st…
“Большой человеческий гридсёч” twitter.com/dsunderhood/st…
Трекинг экспериментов twitter.com/dsunderhood/st…
Быстрый старт twitter.com/dsunderhood/st…
#kaggle Плюс 7-ой “Хаки” О многих хаках я узнал только благодаря Kaggle, это и adversarial validation, и всякие Group-KFold для корректной валидации и то, что препроцессинг текста надо адаптировать под предобученные эмбеддинги типа Fasttext, и eli5 для интерпретации моделей.
Плюсы Kaggle:
5. Прототипы twitter.com/dsunderhood/st…
6. Кругозор в ML twitter.com/dsunderhood/st…
7. Хаки twitter.com/dsunderhood/st…
#kaggle Минус 4-ый – Упование на удачу Вскочить за два часа до конца соревнования, стащить топ-кернел, подшлифовать чутка и ждать своей медальки – is this learning? https://t.co/O8eJZcZ8al
Минусы Kaggle:
Подсаживает twitter.com/dsunderhood/st…
Здоровье, work-life balance, кругозор twitter.com/dsunderhood/st…
Гонка twitter.com/dsunderhood/st…
Упование на удачу twitter.com/dsunderhood/st…
По поводу «гномиков», и чем это отличается от вопросов по алгоритмам и структурам данных. Пример “гномика” – докажите, что между 100500 и Гуголплекс не менее Гугол простых чисел. Посыл мой ясен: спрашивать такое на собеседовании – как минимум, спорно. https://t.co/EBaDPvbPit
Советы начинающим кэгглерам twitter.com/dsunderhood/st…
История про “гномиков” и одно упоротое собеседование twitter.com/dsunderhood/st…
О “гномиках” поподробней twitter.com/dsunderhood/st…
DevOps – это упрощенно говоря, все техники разработки, направленные на поддержание жизненного цикла продукта (ПО). Главное, что хочется сказать – от дата саентистов все чаще требуют навыков разработки, не только фит-предикт, так что разбираться в основах DevOps нужно. https://t.co/Ba9Kvc4cmm
Про алгоритмы и структуры данных twitter.com/dsunderhood/st… Почему это не “гномики” и почему это нужно в Data Science
Про devOps и почему датасаентисту лучше тоже в этом разбираться twitter.com/dsunderhood/st…
Про мой переезд в Нидерланды, собеседования и работу. В конце еще накидаю скриншотов уже описанной истории про плюсы/минусы жизни в Нидерландах. На сей раз скриншоты хотя бы с текстом на русском :) https://t.co/c63BOF9oAo
Про поиск работы за рубежом twitter.com/dsunderhood/st…
О переезде в Нидерланды, работе и жизни twitter.com/dsunderhood/st…