

Архив недели @silyutinaolga
Понедельник
Привет! На этой неделе пишу твиты я, @silyutinaolga
Сейчас работаю аналитиком в команде Рекламы и бизнеса ВКонтакте, преподаю в Stepik Academy и karpov.courses, до этого работала аналитиком в PR отделе SEMRush. Окончила НИУ ВШЭ СПб с дипломом бакалавра Социологии
Быть по ту сторону аккаунта - необычный опыт, но рада этой возможности! Постараюсь рассказать вам о ярких моментах моего путешествия в мир продуктовой аналитики из академического мира социологии.
Надеюсь, мне удастся показать вам применения анализа данных под непривычным для этого аккаунта углом. А может даже вдохновить и поддержать кого-то, кто тоже заканчивает непрофильную специальность и интересуется возможностями в сфере Data Science.
Расписание
Опыт перехода в аналитику без профильного образования
Хакатоны и мой опыт стажировки
Что можно делать на стыке социологии и DS
Повседневные задачи аналитика
Data-driven культура в компании
Нужна ли магистратура аналитику
Преподавание на курсах
Прежде, чем начну рассуждать над первой темой, расскажите, какой у вас бэкграунд в плане высшего образования?
PS: Под DS понимаю и продуктовую аналитику, и Data Science, и различные подобласти; варианты ответов сильно упрощены из-за ограничений на символы от твиттера
Начну говорить о 1й теме на своем примере. Училась я не на классического социолога. У нас было введение в программирование на R, большая любовь к количественным исследованиям, много статистики, был даже теорвер и главное - майнор Data Science (по выбору). С него все и началось
Майнор Data Science electives.hse.ru/minor_data_spb/ длился 2 года, на нем нас учили кодить на R, агрегировать данные, применять модельки, понимать, как они работают, интерпретировать результаты и делать web-приложения на Shiny shiny.rstudio.com
Преподавали нам на майноре @dotsbyname, @AVSirotkin, Алена Суворова и другие классные преподаватели. После первого года обучения некоторые ребята и я примкнули к нашим преподавателям в качестве учебных ассистентов у первокурсников майнора.
Мы проверяли работы, составляли промежуточные тесты и ходили на каждую пару первокурсников, чтобы подсказывать им прямо на семинаре. Это был крутой опыт, мы видели горящие глаза студентов и сами хотели погружаться в тему еще больше. Если в ВУЗе можно побыть ТА - советую.
Уделяю майнору несколько твитов, тк считаю его успешным примером обучения DS-у востоковедов, экономистов, социологов, политологов с абсолютно разными уровнями знаний математики и, уж тем более, программирования на R. После опыта майнора особенно верю в будущее подобного обучения.
Но, несмотря на то, что у меня была такая возможность как майнор, я также проходила онлайн курсы. Особенно связанные с Python, тк его нам нигде не преподавали. Здесь я не буду оригинальной и назову специализацию от Яндекса и Физтеха на Coursera и ML Course Open.
Сейчас атмосферу нашего майнора успешно воспроизводят разные платные буткэмпы, @rustepik с его бесплатными курсами и Coursera/Edx.
Так что, если есть средства, буткэмп будет неплохим стартом еще и с социализацией, если не хочется материально вкладываться, то бесплатные курсы – это супер, только нужно иметь достаточно мотивации для них.
А мотивацию можно повышать, начиная делать проекты, участвуя в хакатонах, ходя на (онлайн)-конференции, общаясь с теми, кто уже работает аналитиком/data scientist-ом, вступая в сообщество ODS. Так можно найти себе role models и тех, с кем можно параллельно учиться.
Еще я люблю смотреть интервью с представителями индустрии. Это интересно не только новичкам, но и тем, кто уже в профессии. Вот примеры каналов
Towards Data Science youtube.com/c/TowardsDataS…
Karpov Courses youtube.com/channel/UCiZtj…
Women Data Leaders youtube.com/channel/UCJ_QT…
Канал из 3 ссылки ведет сообщество @wdl_hse. Оно образовалось после того, как @liddlle121 и Ко. выиграли грант от KDD Impact Program @kdd_news. В 2018 они организовали в Питерской Вышке выступление девушки, работающей на позиции Data Scientist в @NASA, в 2020 - сотрудницы @Tesla.
Я была волонтером в сообществе @wdl_hse. Будучи в Амстердаме на конференции WebSci’18 @websciconf, я записала пару интервью с женщинами, которые преуспели в сфере Data Science. Разговор с ними прибавил мотивации продолжать развиваться в сфере анализа данных и дальше.
@dsunderhood +1 в копилку к каналам: youtube.com/watch?v=I51Dup…
Lex Fridman, конечно, крут twitter.com/dubovitskyden/…
Я смотрю на тех кто лайки ставит и, судя по описанию профилей, практически каждому есть что рассказать. Уверена, у тебя есть много кул стори. А еще, насколько я знаю, вы можете сами писать организатору, если хотите участвовать. Еще много недель впереди :) twitter.com/snowy_robolamp…
Вообще там интересный тред образовался про личный бренд и про возможности, про то, что можно рассказать людям и тд
Чтобы стать востребованным аналитиком, помимо hard-skills не стоит забывать о business sense. Важно понимать бизнес-метрики, уметь генерировать продуктовые гипотезы. Например, в блоге @gopracticeio есть много полезной информации по теме.
В моем случае стажировка показала мне, как общаться с бизнес заказчиками, как представлять данные, на что делать упор в анализе. О ней чуть подробнее расскажу завтра.
А сейчас учусь в школе продактов compscicenter.ru/product-manage… от @compscicenter (да, там такое тоже есть!), чтобы закрепить у себя продуктовое мышление и получить новый опыт.
Как вы понимаете, перед тем как начать работать аналитиком, я занималась смежной деятельностью, лучше понимая себя и сферу, в которую стремлюсь. Это было очень полезно и сделало переход из “непрофильной” специальности и академической среды более плавным.
Сейчас я считаю, что образование в социальных и естественных науках вполне логично для перехода в аналитику. Потому что обычно на этих направлениях изучается статистика, научный подход, проверка гипотез, выборки, а это - часть повседневности аналитика.
А еще полученные доменные знания в университете могут очень круто сочетаться с анализом данных, позволяя делать экспертные выводы. Кроме того, знания социологии/психологии могут быть также полезны аналитикам в индустрии. Об этом поговорим в среду.
Вторник
Таковы результаты вчерашнего опроса, надеюсь, читателям, которые только собираются в DS, будут полезны сегодняшние твиты.
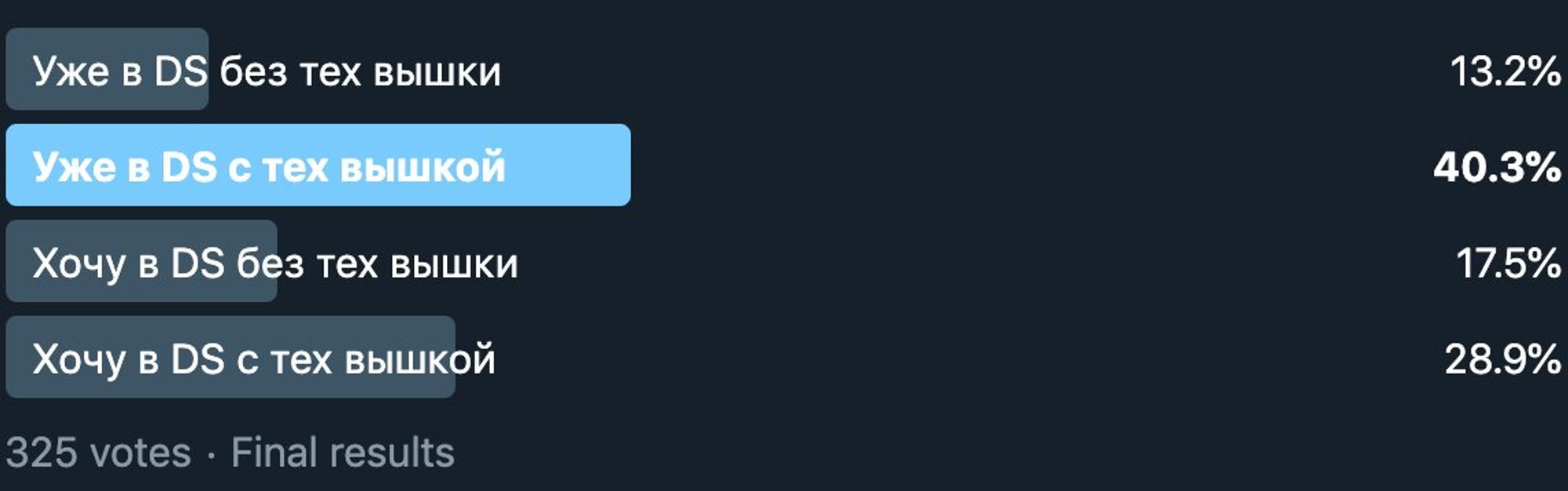
Сегодня расскажу про хакатоны и стажировку. Это два отличных способа начать работать в команде. На первых хакатонах я старалась следить за тем, что делают опытные участники, а еще искать для себя задачи, которые помогут проекту. Способность ставить себе задачи - полезный навык.
Первый значимый хакатон назывался AdHack и там мы делали рекомендательную систему в продуктовом магазине на основе данных со страниц из соцсетей.
Это был классный кейс с точки зрения аналитики, потому что я занималась эксплораторным анализом, рисуя графики, которые доказывали жизнеспособность идеи. А Ильдар Белялов делал face recognition. В итоге взяли 2 место и выиграли велосипеды :)
Еще был хакатон TilTech MedHack, после которого мы даже начали делать стартап. Там со мной в команде были Юра Макаров, Ильдар Белялов и еще врач-онколог в качестве эксперта. Идея была в классификации медицинских бумажных документов.
Там я уже делала байесовский текстовый классификатор, а ребята занимались распознаванием текста на картинках и ботом в телеграме. Тогда мы взяли 3 место и начали делать стартам Aivicenna.
В Aivicenna ребята занимались распознованием опухолей на маммограммах, а у меня было направление с дашбордом для врачей для быстрого реагирования на на начало рецидивов. Но сейчас стартап уже не развивается.
История про забавный фейл. Были мы на хакатоне Газпрома с @how_uhh и @anna_schatt, сидим пилим себе кластеризацию покупок на заправках. Придумали так классно, заказ - это слово, применили word2vec, получили фичи, кластеризуем. А у нас выходит ровно два кластера
Думаем, непонятно. Решили посмотреть на данные снова глазами, смотрим, а там колонка с двумя классами, которую мы нигде не учли - бензин и сопутствующие товары...
Про хакатон NASA и Junction рассказывал в этом аккаунте @mike0sv, мы были в одной команде. Там мы делали генерацию туманностей и моделировали эпидемии.
Теперь к стажировкам. Первая моя стажировка была в Дневник.ру. Ребята делают электронные журналы для школ. Я участвовала в их конкурсе бизнес-идей :), где нужно было придумать образовательный проект на базе Дневник.ру.
Я предложила приложение для синхронизации расписания школьной программы и заданий ЕГЭ. Чтобы к определенной теме школьникам приходили задания по типу ЕГЭ и он понимал как связана школьная тема с будущими экзаменами. Идея выиграла, мне дали мини-грант и стажировку в компании.
Стажировка была не совсем про аналитику. Она заключалась в том, чтобы посчитать экономику моего приложения и исследовать рынок. Но, при этом, я старалась применять методы анализа данных, чтобы самой себе нарабатывать опыт.
Например, для того, чтобы изучить конкурентов, я выгрузила подписчиков групп в ВК двух приложений-конкурентов по API и посмотрела на их сети дружбы, чтобы понять, насколько активно школьники друг с другом делятся инфой о полезных приложениях и скачивают одно и то же.
Стажировка прошла успешно, меня позвали на еще одну, там я занималась анализом рынка. Пока тоже без кода, но уже ближе к аналитике. Потом была возможность перейти в отдел, где нужно было кластеризовать пользователей и писать код, но я пошла работать джуном аналитиком в SEMRush.
Вывод таков, что иногда можно пойти не напрямую аналитиком, а начать сбоку, но делать задачи сверх нужд, чтобы набраться опыта и уверенности.
Вторая стажировка была после того, как я поработала джуном аналитиком в SEMRush. Это была стажировка в отделе Рекламы и бизнеса ВКонтакте. О ней мне рассказал @how_hhh. Сначала я думала, что подаваться нет смысла, но почему-то все равно подалась.
Внезапно меня позвали на собеседование. Потом на еще одно, а потом я стала стажироваться под менторством крутейшего Анатолия Карпова. Вы точно видели его курсы по статистике на Stepik.
Саню неправильно отметила, Саня вот @how_uhh
Первым делом я, конечно, была в шоке от количества умнейших людей на квадратный метр вокруг меня. Очень долго смотрела на всех восхищенными глазами :)
Потом появлялись задачи от менеджеров, параллельно ментор искал для меня какие-то более глобальные задачи вроде предсказания CTR. Я научилась использовать git, читать и немного писать PHP код, работать с биг датой с PySpark, попробовала Zeppelin и получила кучу soft-скиллов.
Имея опыт стажировок и работы джуном, я бы советовала сначала идти на стажировку, потому что там будет ментор, который сможет отвечать на кучу вопросов (а их очень важно задавать), плюс в больших компаниях часто проще пройти сначала стажировку, а потом уже плавно перейти в штат.
Среда
@dsunderhood А как искать стажировку и хакатоны для участия?)
Анонсы хакатонов vk.com/russian_hackers
Стажировки можно искать на сайтах компаний,
И есть еще вот такой канал с вакансиями для джунов t.me/jobforjunior
Если кто-то знает еще ресурсы, делитесь под этим твитом! twitter.com/datagirlAnna/s…
И, конечно, еще паблики университетов, в которых часто постят такие возможности, друзья, которые в нужный момент скинут пост, на который наткнулись (рассказывайте друзьям о том, что вы ищете работу). На HeadHunter тоже есть стажировки.
Сегодня поговорим о пересечении социологии и DS. За последние 5 лет стала набирать популярность дисциплина под названием Computational Social Science. В нее входят исследования, использующие компьютерное моделирование для описания социальных/экономических/политических процессов.
Это необязательно предиктивные модели, это могут быть описательные модели, основанные на заранее заданных константах. Пример тому - агентное моделирование. Известная иллюстрация из социологической теории - модель Шеллинга. Она описывает процесс сегрегации.
Томас Шеллинг изучал поведение жильцов в районах города и на основе наблюдений построил модель, на которой в зависимости от заданного уровня толерантности плотность кластеров с людьми одной расы различается. Т.е. при низком уровне толерантности, похожие люди будут жить рядом.

Если кому-то станет интересно погрузиться в агентное моделирование, есть курс на Coursera coursera.org/projects/abm-n…, популярный инструмент для построения подобных моделей - @netlogo, мы в универе строили в нем модели, где волки ели овец :)
Другое захватывающее пересечение DS и социологии - анализ данных из интернет источников. С появлением соцсетей и распространением интернета анализировать социальные взаимодействия людей в интернете становится все репрезентативнее.
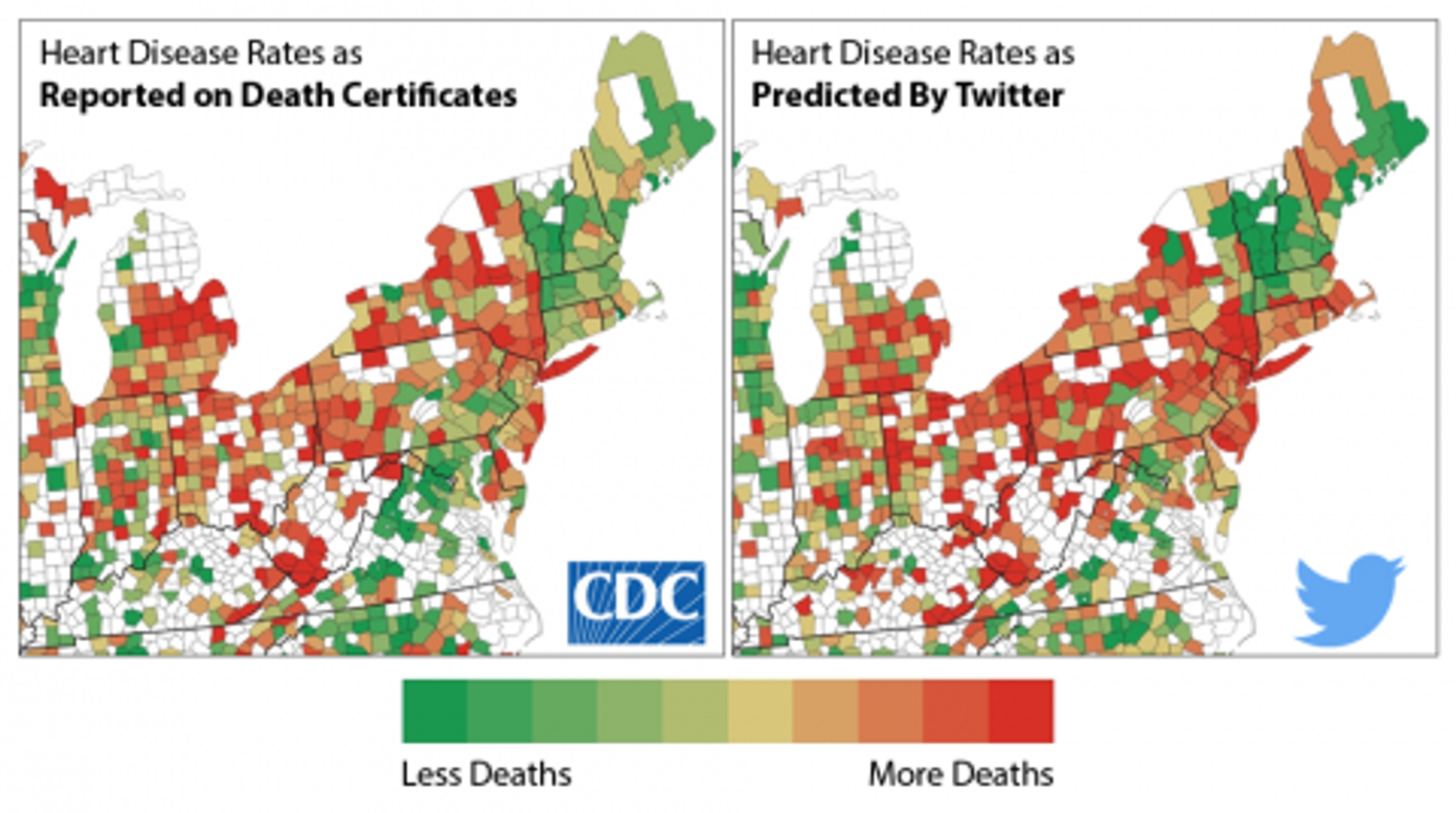
То, что раньше можно было измерить только опросами и скринингами, сейчас можно изучить на данных из Twitter API. Например, предсказать количество инфарктов в каждом штате в зависимости от настроения твитов его жителей. authentichappiness.sas.upenn.edu/news/twitter-c…
Ученые из университета Пенсильвании проанализировали тексты твитов, искали в них стресс, депрессивные настроения, агрессию. Использовали наличие таких сентиментов как предиктор и получили картинку, которая почти не отличалась от официальных данных по болезням сердца.
Анализ текстов блогов тоже открывает новые возможности. Исследовательница Lada Adamic показала высокий уровень поляризации американского общества (республиканцы/демократы). На основе данных политических блогов она построила граф цитирований, показав четкое разделение дискурса.

Расскажу вам и про исследование, которое мы делали вместе с прекрасной научной руководительницей и соавтором @shirokaner. Мы исследовали динамику дискурса об интернет регулировании в России. Кластеризовали векторные представления текстов, получали тематики по годам.
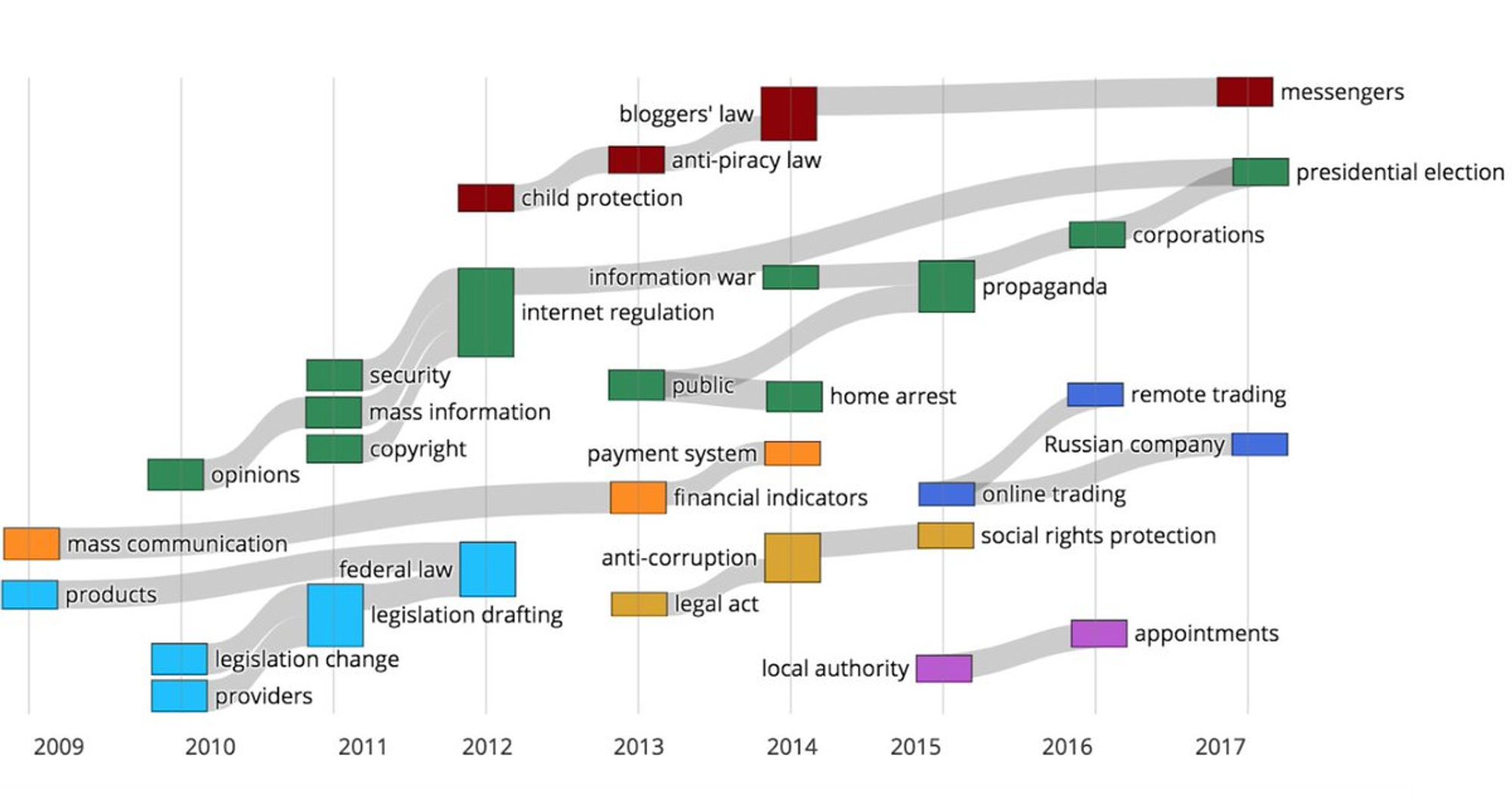
Тексты - статьи об интернет регулировании из российских СМИ. Мы выделили 7 сфер, которые оказались связаны с темой интернет регулирования. Это коммуникации и СМИ, ужесточение законодательства, государственные процессы, онлайн бизнес, политика, создание новых законопроектов.
График с динамикой изменений тематик дает возможность увидеть то, что активно обсуждалось в каждом году, а также увидеть всплески в количестве обсуждаемых тем. Подобное исследование дает ретроспективу и помогает лучше понять как государства пытаются регулировать сферу интернета.
На эту тему у нас есть пара публикаций в сборниках международных конференций, в твиттере сложно коротко описать все, поэтому вот ссылочки dl.acm.org/doi/10.1145/32…
link.springer.com/chapter/10.100…
Четверг
Сегодня расскажу о том, какие повседневные задачи бывают у аналитиков и поделюсь парой полезных ссылочек и лайфхаков. Но перед этим хочу начать с разнообразия сферы data-related профессий.
Мне нравится читать главного по экспериментам в Yelp на LinkedIn, в одном из постов он рассказывал о том, что сегодня на рынке есть огромное количество data-related ролей, каждая из которых по-своему ценна, а называть всех Data Scientis-ами не стоит. linkedin.com/posts/eric-web…
Последнее время в России стали разделять Data, Product, UX, Business аналитиков. Считаю, это хороший показатель того, что компании стали лучше понимать, почему аналитика важна и что универсального человека найти невозможно.
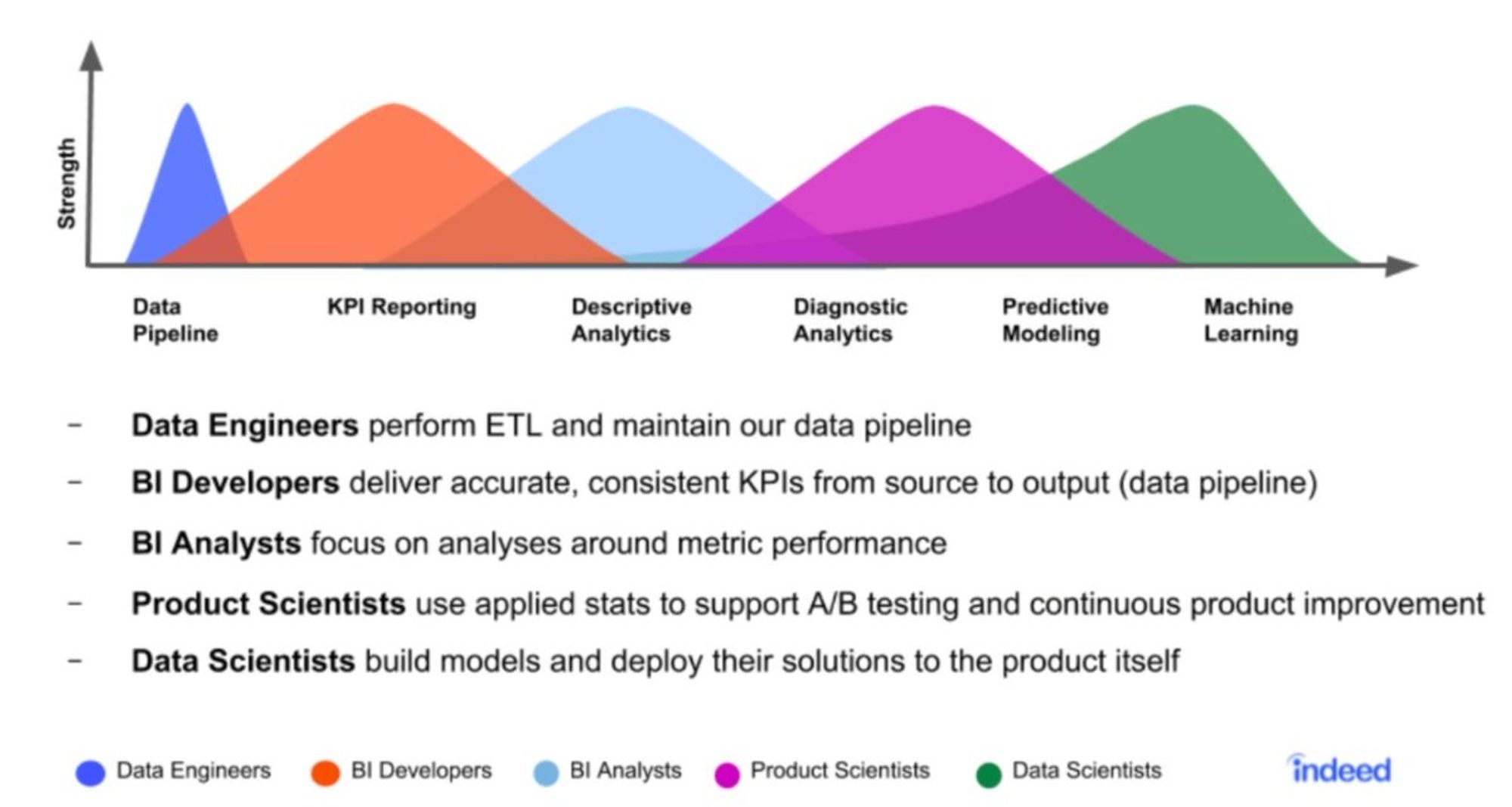
Помимо разделения аналитиков по доменам, происходит более гранулярное деление data-related ролей по наличию определенных скиллов. Мне нравится вот эта картинка от Indeed про скиллы разных специалистов.
Еще есть классный доклад от Spotify про то, как у них появилась позиция Analytics Engineer. Это тот, кто понимает, что нужно аналитикам и как это донести датаинженерам. Вот видео выступления, там еще много полезного про устройство аналитики в компании
youtu.be/AWG08n3VmYs
В моей повседневности есть примерно 4 типа основных задач. Это эксперименты, исследования, ETL, AdHoc запросы. Иногда каких-то задач больше, чем остальных, а иногда перед тем как провести эксперимент нужно построить какой-то небольшой ETL процесс, например.
Эксперименты. Первый этап - это дизайн эксперимента (A/B теста): объем выборки, ожидаемая длительность, условия попадания пользователя в эксперимент. Далее сбор данных (здесь главное не подсматривать за результатами раньше времени) и, наконец, анализ результатов.
Для того, чтобы лучше понимать, как проводить эксперименты можно почитать вот эту книгу, которую однажды в интервью Karpov Courses посоветовал @NMarshalkin, amazon.com/Trustworthy-On…. Ее написали аналитики из Linkedin, Google и других компаний с огромным опытом в экспериментах.
Исследования. Например, задачи оценки потенциала фичи, исследования поведения пользователей, иногда ML модели для категоризации пользователей или контента и другие. Это важная часть работы аналитика и нужно стараться, чтобы она занимала не меньше 30% рабочего времени.
ETL. Это задачи, для которых необязательно привлекать датаинженера. Вроде создания таблиц, агрегатов, пайплайны с заливкой данных из одного места в другое по крону при помощи, например, Airflow. Полезно уметь делать это самостоятельно, чтобы быстрее потом проверять гипотезы.
AdHoc. В компаниях есть много разных менеджеров, которые общаются с клиентам или развивают продукт напрямую. Всем им нужно принимать какие-то решения на основе данных. В таких запросах главное заранее понять, какие из них повторяющиеся и какие можно автоматизировать.
Есть удобное решение для того, чтобы справиться с потоком AdHoc запросов без постоянного мультитаскинга и переключения внимания - дежурства. Если в команде больше одного аналитика, можно назначать каждый день дежурного аналитика, который будет быстро отвечать на запросы весь день
Пятница
Сегодня говорим о data-driven подходе к принятию решений. Первым делом нужно наладить быстрый доступ к данным. Для этого нужно понимать, кто ими будет пользоваться и в каких ситуациях, куда лить данные, в каком виде. Начнем тред с выбора базы данных для аналитики.
При выборе аналитической БД нужно понять, в каком формате и кто будет работать с данными. Говоря об аналитике, нас интересуют OLAP сценарии работы — запросы делаются часто, а их результаты нужны быстро. В таком случае подходят колоночные БД. Например, всеми любимый ClickHouse.
В ClickHouse удобно писать события для аналитики, можно делать широкие таблицы с большим количеством колонок, избегая лишних JOIN-ов в запросах. Синтаксис CH также удобен для аналитики, есть много функций, разнообразие движков и супер оптимизированная обработка запросов.
Несмотря на все плюсы, CH сложно админить и поддерживать стабильность работы. Поэтому важно иметь еще один источник для хранения данных, например, hdfs. В Hadoop также можно хранить очень старые данные, чтобы не расходовать память на кластере с ClickHouse напрасно.
Также для принятия решений на основе данных нужен удобный инструмент визуализации. Мы используем Open Source BI систему Superset. Достаточно удобная система, в которой очень легко построить дашборды с основными продуктовыми метриками.
И, конечно, важнейшим инструментом для принятия решений на основе данных являются эксперименты. Очень важно, чтобы в компании появилось правило "не катить без AB теста", тогда риски что-то сломать снижаются в разы.
Еще полезная вещь - история A/B тестов. Ее можно автоматизировать или вести вручную в Confluence. Оставлять краткое описание эксперимента и результаты. Это поможет не повторять каких-то ошибок в будущем, плюс на данных экспериментов можно обучать предсказательные модельки.
О месте аналитика в команде. Эффективнее сразу включать аналитика в работу над конкретным продуктом, нежели обращаться к одному аналитику с запросами по разным направлениям. Так аналитик имеет возможность погрузиться в исследование и на его основе предлагать дальнейшие идеи.
Суббота
Сегодня поговорим об образовании для аналитиков. Обсудим, нужна ли магистратура, а если нужна, то какая и кому? Также поделюсь своим опытом учебы в магистратуре и совмещении ее с работой.
Итак, магистратура в моем понимании никому не помешает. Другое дело, что не всегда есть возможность ее получить, поэтому появляется выбор тратить силы на поступление и обучение или нет.
Магистратура может играть систематизирующую роль, обобщая знания, добытые опытным путем из разных источников. Может также быть способом формально закрепить свой профессиональный статус. Вторая функция особенно важна зарубежом, где от аналитика ожидают профильное образование.
Я столкнулась с необходимостью принимать решение о продолжении обучения, уже работая в индустрии. И сейчас я бы посоветовала людям с full-time работой реалистично оценить свои силы и понять для чего вам нужен магистерский диплом.
При выборе магистратуры, которую вы планируете совмещать с работой, важно обращать внимание на время занятий и важность участия в семинарах. На моей программе Human-Computer Interaction в Вышке занятия проводятся вечером, а накопительные оценки можно получить за домашние работы.
Также стоит основательно взяться за time management для того, чтобы не пропускать дедлайны. В доковидные времена мне это давалось особенно сложно, потому что часто не было возможности приехать на занятия. Сейчас с записями семинаров, вникать в происходящее намного проще.
Из этого опыта я сделала вывод о том, то online магистратура - это лучшее, что можно сейчас найти для работающих профессионалов, а концепция long life learning - это уже не светлое будущее, а реальность.
Сейчас российские (Вышка, МФТИ), американские и европейские университеты активно открывают онлайн программы, которые стоят в разы дешевле их оффлайн копий, либо даже дают стипендии на обучение. С наступившей пандемией онлайн образование постепенно становится нормой.
Не стоит ожидать, что знания в магистратуре (особенно мультидисциплинарной как у меня) будут идти параллельно с задачами на работе. Не факт, что они будут полезны сиюминутно. Это осознание поможет не терять мотивацию и оставаться открытым к новым знаниям.
Также будет круто, если вы сможете связать какой-то проект на работе с вашим магистерским дипломом. Так можно убить сразу двух зайцев и принести много пользы.
TL;DR:
Планируя совмещать работу с учебой, оцените свои силы и учебный план;
Найдите рабочий проект для диплома;
Присмотритесь к online магистратурам;
Не разочаровывайтесь в учебе, если знания нельзя сразу применить на работе;
Не забивайте совсем на оценки, вдруг захотите на PhD;
Ссылки на магистратуры в России, в которые реально поступить без профильного бакалавриата (список неполный, можно смело изучать сайты этих ВУЗов и дальше)
НИУ ВШЭ СПб
spb.hse.ru/ma/computer/
spb.hse.ru/ma/analysis/
НИУ ВШЭ Мск
hse.ru/ma/dataanalyti…
МФТИ + Skolkovo
skolkovo.ru/programmes/050…
СПбГУ
gsom.spbu.ru/programmes/gra…
Воскресенье
В заключительный день расскажу про опыт преподавания на курсах и о том, на что стоит обращать внимание студентам при выборе курса.
Мне удалось попробовать себя в преподавании начинающим аналитикам в курсе-буткемпе. Есть также и опыт преподавания студентам, которые уже работают на любимой работе, но хотят узнать больше про новые инструменты.
В случае с новичками сложность заключаетсч в том, что бекграунд у людей очень разный. Кому-то объяснение понятно, кому-то нет, поэтому особенно много времени нужно уделить методике преподавания.
Когда преподаешь людям из индустрии, удается не только учить, но и немного учиться. Ведь у студентов уже есть много релевантого опыта. В решениях домашек иногда можно найти интересные подходы и словить инсайты.
В целом, считаю, что сама идея платных курсов это ок. Но вот то, как за маркетингом стало невозможно увидеть, что тебя реально ждет, немного смущает. И сейчас киллер фича в рекламе курсов - это скорее честность, нежели идеализированная или преувеличенная картинка.
Говоря о пользе курсов с точки зрения студентов, то я бы искала те, в которых есть доступ к преподавателям напрямую или активная команда поддержки, продуманные проекты по ходу курса и покрытие тем, которые требуются в вакансиях вашей мечты.
Также не стоит ожидать, что курс будет длиться неделю, все же для погружения нужно больше времени. А перед покупкой стоит проверить, нет ли бесплатных альтернатив, а если есть, чего в них не хватает по сравнению с платными вариантами.
Неделя подошла к концу. Спасибо всем, кто читал, комментировал, лайкал и репостил. Мне было очень интересно провести эту неделю с вами, надеюсь, это взаимно.
Еще я люблю смотреть интервью с представителями индустрии. Это интересно не только новичкам, но и тем, кто уже в профессии. Вот примеры каналов Towards Data Science youtube.com/c/TowardsDataS… Karpov Courses youtube.com/channel/UCiZtj… Women Data Leaders youtube.com/channel/UCJ_QT…
Бонусом рандомные факты за неделю :)
5 дней подряд я начинала треды со слова “сегодня”;
содержательный твит с наибольшим количеством лайков - твит со ссылками на ютьюбчик twitter.com/dsunderhood/st…;
оказывается, в этом аккаунте есть много начинающих специалистов;
И по традиции - ссылочки на соцсети
Twitter: @silyutinaolga
FB: facebook.com/osilyutina
LinkedIn: linkedin.com/in/olga-silyut…
Inst: instagram.com/olchasilyutina/
VK: vk.com/o.silyutina






















