

Архив недели @rampeer
Понедельник
Привет, ребята. Эту неделю вести аккаунт буду я, Грозин Владислав (@rampeer). Сейчас работаю в constructor.io В DS уже шесть лет, занимался в основном рекомендательными системами в е-коммерсе. Кто-то меня ещё может знать как активиста ODS и основателя Pet Projects.
Тут модно рассказывать про кто откуда и где учился. И я расскажу. Я из Питера, увлекался олимпиадными программированием, и пошел в ИТМО. Совершенно случайно наткнулся на Data Mining Labs, образовательный кружок Алексея Натёкина. DS оказался круче олимпиадного программирования
потому что больше связей с реальностью, а хардкорная математика под капотом осталась. Перед тем как работать "по интересу", писал сетевые драйвера для Линкуса, мобильные игры под Андроид и админил сервера LAMP.
Планчик на неделю:
Рекомендательные системы - разрушаем некоторые мифы
Как выживают на удалёнке?
Графовые рекомендательные системы
Reinforecement Learning в рекомендательных системах
Продуктивность и планирование
Академия, инженерия, менеджмент. Что лучше?
Дальше работа в Diginetica. Делал поиск и рекомендашки для Юлмарта, Спортмастера, Красного&Белого, и других крупных игроков. Там поднялся с рядового аналитика до руководителя DS в компании. Из хайлайтов работы - "отбили" Медиамаркт от Yandex Data Factory ...
... сделав рекомендашку круче, чем у них. Сейчас работаю в Долинном стартапе, где делаю принципиально то же самое, но уже на американском рынке.
Параллельно со всем этим - опенсорс, отдельные проекты и консалтинг.
Рекомендательные системы - разрушаем некоторые мифы.
Поехали. Интерфейс и формат Твиттера мне непривычны; поэтому крепитесь держитесь - впереди стены текста.
Что такое "Рекомендательная система"? Англоязычная Википедия говорит, что это система для прогнозирования рейтингов для пары (объект, пользователь). Это старое определение.
Его ноги которого растут из Netflix Prize, соревнования, которое дало большой толчок развития области, и где и вправду надо было прогнозировать рейтинг для пар (пользователь, фильм).
Более современное определение - это система, которая может из большого набора подобрать необходимые объекты исходя из ситуации (пользователь, поисковой запрос, просматриваемый объект, ...). Да, это можно свести к регрессии/классификации, но это один из способов подойти к решению.
Вторник
Поэтому почти все современные пейперы меряют качество именно топа выдачи рекомендательной системы (и частенько - и оптимизируются прямо под него).
У многих "коллаборативная фильтрация" - синоним рекомендашек.На самом деле коллаборативная и контентная фильтрации - это предположения для построения рекомендашек. Эти термины очень старые - пожалуйста, используйте их осторожно. Сейчас все за редким исключением системы гибридные
"Коллаборативная фильтрация" - у нас пользователей так много, что они образуют кластера "интересов", и мы можем использовать информацию с соседей в кластере, чтобы сделать рекомендацию пользователю (т.е. пользователи "коллаборируются" друг с другом для построения рекомендаций).
По вышенаписанному, видам и типам рекомендашек - есть классный (пускай и старый) survey, где всё отлично разложено по полочкам: sciencedirect.com/science/articl…
Теперь касательно индустриальной части.
Реальная работа над рекомендашками часто сводится к определении того, под что именно должна оптимизироваться система (=много аналитики и графиков), где система лажает (=ещё аналитика) и добавлению фичей, которые должны это исправить.
Никто не сидит и не "имплементит коллаборативную фильтрацию" до посинения, выражаясь словами одного собеседуемого :)
Поэтому темы Multistakeholder RS и использование RL мне интересны. Они решают реальные индустриальные проблемы, так как часто надо оптимизироваться под пачку критериев сразу (выручка, оборот, остатки на складе); и многие сигналы - отложены. Поподробнее про это будет в четверг
По метрикам есть отличный обзор researchgate.net/publication/32…
Как выживают на удалёнке?
4 года я работал на удалёнке, делаю это по сей день, и сейчас поделюсь своими находками, наблюдениями и лайфхаками.
Сразу отмечу, что это не для всех. Почти всегда будет потеря в продуктивности. Некоторым тяжело без коллег рядом, которые тоже чем-то заняты, к которым можно подойти что-то спросить, и этой общей офисной рабочей атмосферы.
Это абсолютно нормально. Времени больше не становится.
Касательно времени. В удалёнке легко скиснуть, и важно быть честным с собой. Откладывать работу до часа до стенд-апа - очевидно плохая идея, но мозг может идти на невероятные уловки, чтобы не замечать этого. Ведь это видео с котиком очень милое, и всего пять минут длиной, да? :)
Тут помогают программы, которые отслеживают время (я пользуюсь rescuetime.com). ВНЕЗАПНО оказывается, что из 8-часового дня мы реально работаем только часа 4 (в том числе и в офисе); становится понятно, куда уходит время, и можно почерпнуть полезные закономерности.
Например, обнаружил, например, что если утром посмотреть какой-нибудь сериальчик, то день насмарку
А ещё однажды решил попробовать максимизировать эффективное время. Набрал 70 часов в неделю. Интересный опыт. Эксперимент сам повторять не планирую, но вам рекомендую попробовать:)
На удалёнке большую роль играют ритуалы. Если мы работаем постоянно в одном месте, в офисной одежде в и в одинаковых условиях, то голова привыкает это делать, и собраться проще.
Поэтому удалёнщик без штанов - это неэффективный удалёнщик :)
Если интересна работа из дома и удалёнка - то можете подписаться на блог Trello. Они пишут очень интересные штуки про продуктивность, и часто затрагивают эту тему.
blog.trello.com/work-from-home…
Другой немаловажный компонент успеха - наличие плана.
Список задач на день даст сконцентрироваться на важном. Подробнее про это будет в пятницу (символично). А график не даст циклу сна уехать непонятно куда; это ключ продуктивности согласно авторитетным биохакерам.
Последняя находка, которой я сегодня поделюсь - это про еду.
Доставка рационов питания, как оказывается, не так дорога, и не позволит отъестся в карантин. Дешевле только готовить самому.
Кстати, как ваша удалёнка? После перехода на работу из дома продуктивность
Среда
Графовые рекомендательные системы.
Это крайне обширная область, которую я для себя открыл только недавно, и сейчас расскажу про интересные штуками, которые успел нарыть
Думаю, базовая идея уже понятна из названия - мы представляем наши данные в виде разных объектов со связями между ними (т.е. взвешенного графа), и дальше применяем к нему всевозможные графовые алгоритмы для решения задачи генерации рекомендаций.
Давайте решать задачу ранжирования страниц в поисковике. Сделаем граф, узлы - страницы; связи - ссылки между ними. Будем случайно "гулять" по нему, переходя от узла к узлу по ссылкам (и иногда "прыгая" на новую случайную страницу)...
... Для каждого узла посчитаем вероятность того что мы в нём окажемся там в случайный момент времени (стационарная вероятности). Чем чаще на страницу ссылаются, тем выше будет вероятность, и тем выше надо показывать её в поиске.
Этот алгоритм - PageRank, который в основе Гугла.
Кстати, в статье про PageRank есть вот такая забавная фраза
> To test the utility of PageRank for search, we built a web search engine called Google (Section 5)
А ещё тут Page - это не только "страница", но и фамилия автора, Larry Page. Сочно, да?
ilpubs.stanford.edu:8090/422/1/1999-66.…
Можно эту конструкцию усложнять. Например - считать не просто стационарную вероятность, а если мы будем начинать блуждать с каких-то конкретных узлов (истории пользователей), и возвращаться на них же.
Так мы получим не один глобальный скоринг, а персонализированный.
Отличный обзор графовых методов, основанных на случайных блужданиях вот тут:
researchgate.net/publication/32…
Многие SotA методы в рекомендашках похожи: строим эмбеддинг юзеров и товаров; считаем дистанцию между ними / между парами товаров.
В индустрии не нужно считать схожесть ВСЕХ пользователей и ВСЕХ товаров - достаточно запомнить самые похожие. Если это сделаем, то получим... граф.
Поэтому в индустрии и на практике они часто всплывают, иногда в неожиданных местах.
Вот, например, Pinterest случайно блуждает (в онлайне!) по подготовленному графу: dl.acm.org/doi/pdf/10.114…
или Одноклассники делают хитрые штуки на хитром графе arxiv.org/abs/1310.7428
В прекрасной статье arxiv.org/abs/1907.06902 написано, что у многие популярные модельки не воспроизводятся / не бьют бейзлайн. И тут выделяется моделька SLIM, которая всех рвёт.
Знаете, что под капотом SLIM? По сути - обучение графа похожести объектов.
glaros.dtc.umn.edu/gkhome/fetch/p…
Четверг
И на закуску - пару слов про самые современные методы.
Прогресс и нейросети пришли и в графовые рекомендации, поэтому будут сеточки.
В графовых сетях идея простая: каждый узел генерирует соседям сообщения (вектора), которые зависят от эмбеддинга и типа связи. Затем каждый узел агрегирует входящие "сообщения", и обновляет свой вектор состояния. Потом - снова рассылка, и процедура повторяется до сходимости.
В разных моделях разные способы формирования сообщений, агрегации и лоссов. На 6й страницы этой статьи отличная сводка по разным графовым сеткам: arxiv.org/pdf/1812.08434…
А применительно к рекомендациям, пару примеров:
Graph convolutional matrix completion, который напрямую прогнозирует связь в двудольном графе: arxiv.org/pdf/1706.02263…
Похожая моделька чуть поновее и с хитрым семплированием, PinSage: arxiv.org/pdf/1806.01973…
В графовых сетках легко и естественно использовать контентную информацию (а в индустрии этой информации очень много).
Этим воспользовался KGAT, где к взаимодействиям пользователей добавлена контентная информация про объекты.
arxiv.org/pdf/1905.07854…
За наводки на статьи спасибо @nm_tismoney !
Reinforecement Learning в рекомендательных системах
Тема большая, интересная и интригующая - поехали.
Начнём с многоруких бандитов. Это ветка в RL, в которой агент должен найти оптимальное действие ("руку") среди предложенных. Конструкция простая и эффективная, часто применяется в индустрии.
Поподробнее про них тут:
youtu.be/4vsbzo-zmhQ
Рекомендательные системы - не исключение. Оптимизируемым действием, может быть, например, "какой товар показать в баннере", "каким цветом покрасить кнопку Купить", "какую картинку товара показать в превью". Вот, NetFlix оптимизирует обложки:
slideshare.net/JayaKawale/a-m…
Пятница
Это ещё не все по RL в рекомендашках. Завтра будет ещё пачка твитов и ссылок на статьи.
Stay tuned!
Также, multi-armed bandits являются хорошей заменой традиционным А/Б тестам. Ценой несложной инженерии мы получаем ускорение сходимости тестов.
towardsdatascience.com/beyond-a-b-tes…
Многорукие бандиты известны давно. Популярный Thompson Sampling, был сделан аж в 1933м году. Тогда задача считалась столь сложной и бесполезной, что во время Второй Мировой были жалобы, что учёные зря на неё отвлекаются
Возвращаясь в текущие дни - что же есть интересного сейчас?
Одна из статей, где "настоящий" RL прикручивается к рекомендашкам датируется 2007 годом. Тут "состояние" - последние просмотренные страницы пользователя, а действия агента - предложение пользователю посетить какую-то страницу. Агент максимизирует клики.
citeseerx.ist.psu.edu/viewdoc/downlo…
Отличная статья 2018 года. Авторы предлагают DEERS. Ключевые отличия от статьи выше - глубокая сетка вместо простой формулы для моделирования награды, и использование негативного фидбека (игнорирование пользователем рекомендации)
arxiv.org/pdf/1802.06501…
А в этой совсем свежей (опубликованы на AAAI'2020) статье используется RNN для кодирования последовательности объектов в сессии, и подключается информация о контексте запроса:
arxiv.org/abs/1909.03602
В чём загвоздка, если всё так хорошо, почему оно не едет в прод?
Ответ простой: для оценки качества работы используют "симулятор" и синтетические данные, и
>The simulator has the similar architecture with DEERS (самой моделькой)
Естественно, если генератор и моделька совпадают по форме, то моделька в итоге выучится. Но нет никаких гарантий, что этот моделька будет хорошим приближением того, что происходит в головах пользователей.
Эксперименты с реальными пользователями пока не наблюдаются.
Касательно фреймворков оценки. Два стула:
От Criteo:
github.com/criteo-researc…
но в нём поддерживается только симуляция.
Вот описание от Самсунга системы, которая не обладает этим недостатком
insight-centre.org/sites/default/…
но, похоже, это закрытая разработка, и потрогать её не получится
Подытоживая:
- Сейчас есть интересные статьи с нейронками
- Evaluation пока на симулированных данных
- Сама область перспективная; на практике оптимизировать отложенный сигнал нужно, и RL поможет решить вопросы типа "accuracy vs diversity".
Суббота
Продуктивность и планирование
Моя любимая тема, иногда я шучу, что это моё хобби: время, которое я потратил на чтение статьей и лекций вряд ли отобьется этим увеличением эффективности :)
Поехали. Как у вас ведётся список задач?
Почти все прочитанные мной книги примерно про одно: все мы предпочитаем известное перед неизвестным, простое перед сложным, и бездействие перед действием; наша память ненадёжна, а мозг нерационален.
Поэтому система записи задач должна быть, причём максимально простой и понятной.
Так, мы можем прямо сейчас сесть и задаться вопросом: "Что я могу сделать в ближайшие полчаса?", и составить список. Из него выбрать пункт, и пойти работать над ним на полчаса. Через полчаса обновить список и повторить процедуру.
Это техника Помодоро, рекомендую всем попробовать
Pomodoro прост и эффективен. А для более интересных штук и рекомендую две книжки:
"Getting Things Done" - пускай она ориентирована на управленцев с бумажным ежедневником, но приёмы применимы ко всем.
"Джедайские техники" - короткая и понятная компиляция работающих принципов.
Что я почерпнул из этих книжек (1/2):
- отделите "инбокс" от списка задач. В первый задачи попадают СРАЗУ после возникновения, во вторую - после формулировки
- сформулированная задача отвечать на вопрос "какое КОНКРЕТНОЕ следующее действие надо сделать"
(2/2):
т.е. "Сделать фичу Х" - не ок; "Написать менеджеру просьбу уточнить требования для Х" - ок
- все задачи должны быть в одной системе; должны быть дедлайны
- не надо строить сложных иерархий задач
- имеет смысл завести отдельную свалку "долгосрочные идеи"
Воскресенье
Академия, инженерия, менеджмент.
Давайте сегодня поговорим про карьеростроение.
Инженерю я давно. С бизнесом тоже знаком - родившаяся на хакатоне идея превратилась в реальный продукт (AnyQuery). Мой индекс Хирша сейчас 3 - что куцо для учёного, но неплохо для инженера.
Так что я видел DS с разных сторон баррикад. Поделюсь впечатлениями.
Иногда в DS этот вопрос ставится как "академия vs индустрия".
Заниматься исследованиями - для крепких нервами альтруистов, второй вариант проще и понятнее, и люди часто перетекают из первого (и крайне редко - обратно).
Академия: есть возможность писать пейперы в интересной тебе области. Минусы - процесс практически безвозмездный, трудоёмкий и крайне медленный; везде одни и те же люди и мало движухи.
А тем, что ты сделал, будет интересоваться два человека в мире (причём оба - из Индии).
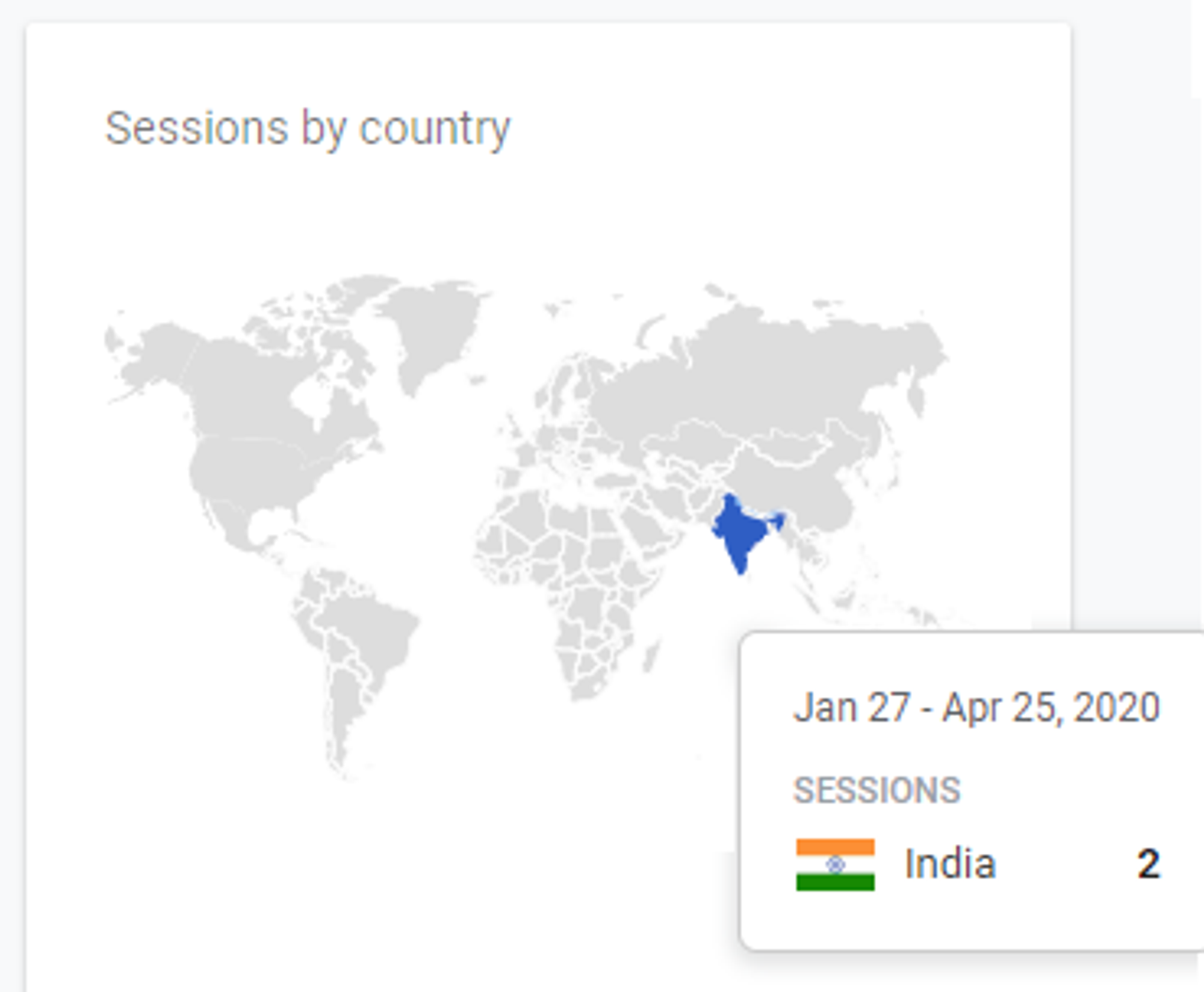
Индустрия: понятная карьерная лестница; больший выбор мест работы; но при этом много где задачи сводятся к написанию SQL запросов для трансформации JSON-ин и генерации фичей, которые дальше скармливаются готовому xgboost.
Но, хэй, зато хорошо платят

(1/2) Второй часто возникающий вопрос - "менеджмент vs инженерия - куда лучше расти". На мой вкус, это не удачная дихотомия карьеры.
По мере того, как ты растёшь как инженер, будет расти и зона твоей ответственности. Но большая зона ответственности требует работы с ...
(2/2) ... более абстрактными требованиями, делегирование и более долгосрочное планирование, а эти навыки относят к "менеджерской".
А продукт-менеджеры мне часто говорили, что им важно видеть особенности технической реализации, чтобы понимать ограничения и возможные препятствия.
Вот более удачное разделение карьеры на ветки есть видео от Алексея Натекина
youtube.com/watch?v=lDkTNU…
и моё развитие темы
youtu.be/x66OhRAHHok?t=…
Вкратце - есть три дерева скиллов, "доменные знания", "рисёрч" и "инженерия". Стоит сделать упор на каком-то одном скилле в одной ветке; но также иметь базовые навыки в остальных, иначе это станет ограничивающим фактором (см. T-shaped people).
На закуску - список литературы:

"Следующий уровень"
Эта небольшая книжка описывает вертикальную карьерную лестницу, и поможет тем, кто достиг своего потолка. (Спойлер - вместо того, чтобы делать продукты - обрастать знакомствами, и скейлиться - делать системы, которые делают продукты).
labirint.ru/books/511445/
Не могу не посоветовать книжку "45 татуировок менеджера", сборник кулстори управленца. Учатся на ошибках, а когда они чужие, то это можно делать безболезненно.
mann-ivanov-ferber.ru/books/paperboo…
По поводу карьеры целиком мне недавно умные люди посоветовали "StandOut 2.0", но я её пока ещё не осилил, поэтому прокомментировать не могу. Но навскидку - прикольная штука.
Про Kaggle. Выскажу ещё одно непопулярное мнение - он не эффективен для "набивания" резюме.
Для меня как собеседующего "занял 50е место в контесте" выглядит не так интересно, как проект, где была самостоятельно поставлена задача, собран датасет и натренирована моделька.
Kaggle относится к индустриальному DS примерно так же, как олимпиадное программирование к работе в компаниях.
Место в соревнованиях простая и понятная мерка; но, жаль, она мерит не то.
Вот и всё - моя смена подходит к концу.
Мне понравился опыт ведения Твиттера, и я планирую продолжать.
Я стратегично упустил тему инструментов ведения задач, напишу про это. Ну и буду постить про продуктивность, рекомендашки и DS в целом.
Подписывайтесь на @rampeer :)




















