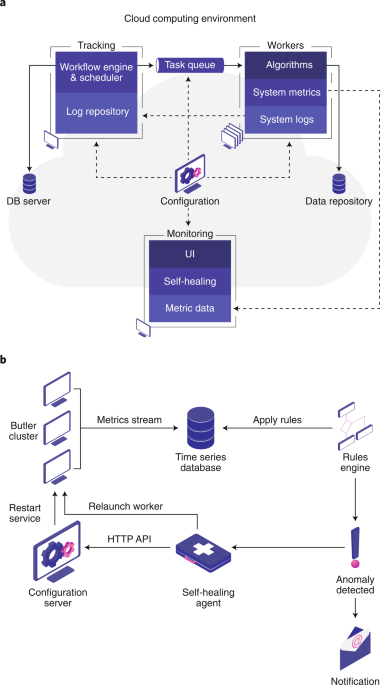
Архив недели @not_a_reptiloid
Вторник
Внимание внимание
Это не учебная тревога
Вам сказали что на этой неделе никто не будет вести этот твиттер
Вас обманули

Меня зовут Герман, я живу в Германии и я геномный биоинформатик
В этом аккаунте уже были биоинформатики - если вы всё уже узнали, можете на недельку отписаться
Я работаю в больнице, мы диагностируем разные редкие заболевания и подбираем терапию от рака
Разумный вопрос - почему биоинформатик ведет твиттер по DS?
Я скажу честно. Я не знаю что такое дата сайнс. Я использую статистику каждый день, визуализирую данные, прогоняю террабайты данных. Но я не назову ни одного фреймворка DS.
Усы лапы питон и Р - вот мои фреймворки
Пока у вас время замьютить аккаунт до конца недели, если вам (как и мне) надоела вся эта биоинформатика хуже пареной репы, а потом мы начнем говорить про войну и про бомбежку про большой линкор Марат
Шутка. Ничего кроме геномной биоинформатики и статистики.
План на неделю пусть будет такой:
исследования последних лет, использовавашие достаточно большие данные,
типы данных, с которыми приходится работать биоинформатику в больнице,
что можно предсказать по геному - геномные риски
как пропускать через себя тысячи историй болезни и не выгореть,
сражения с врачами за пи валью - тактика стратегия пути отхода,
редкие заболевания, сложные заболевания, онкология: где мы работаем вот сейчас и что у нас получается
Так как встал я на неполную вахту, должно хватить =)
Для затравки скину одну из своих лекций. Не, она не хорошая. Просто это способ познакомиться и там есть обзор данных разного типа, использованных в большой исследовании.
youtube.com/watch?v=Ij8QYP…
Еще сегодня утром я не знал, что буду вести этот твиттор, поэтому успел купить пива, и вести твиттор допоздна значит предать пиво. А я не такой.
Поэтому до встречи завтра =)
И это, если у вас какие вопросы, что еще добавить - скидывайте любую тему которая относится к ДНК + человек, всякие предсказания, ДНК-Тиндер и тому подобное, я постараюсь как-то ответить и какой-нибудь тредик придумать =)
Тред #1говорят не по форме представился!
Герман Демидов, 1990го года рождения, образование высшее, вредные привычки имеются. Закончил специалитет мехмата МГУ (теория чисел), но был отвергнут математикой. Закончил магистратуру СПбАУ РАН (биоинформатика)
ныне почившего в бозе. Дальше аспирантировался в Барселоне, стажировался в Сент-Луисе, ныне пребываю в тревоге и тоске в Тюбингене, что недалеко от Штутгарта. Здесь мировой центр машинного обучения, но мне это не очень помогает.
Ой ой ой забыл сказать - на личный твиттор автора подписываться стоит только если вам прям ну очень интересна тема. Там нет популяризации и это скорее профессиональный аккаунт.
А то сейчас наподписываетесь а потом наотписываетесь, а мне потом плакать что подписчики разбежались
Ночной твит - раз уж я занимаюсь всякими биологическими штуками и применяю стат методы, то наверное могу предположить когда ковидла уйдёт?
Мы будем жить плохо три года.
А потом привыкнем.
Анализ данных такого рода делают профессиональные эпидемиологи, но и они конкретно мажут с предсказаниями
А уж сколько «заслуженных научных работников» и даже эпидемеологов и даже из лучших универов впали в ересь по поводу предсказаний ковидлы - не сосчитать
Поэтому лучше было бы сказать «данные показывают нам что нужно немного потерпеть»
По тем сотням тысяч исследований по ковиду которые опубликованы можно делать специальные дата семинары и разбирать fallacies каждой работы
Нерепрезентативный семплинг, игнорирование неудобных исследований, игнорирование того что реальные числа не бьются с предсказаниями уже на момент публикации работы и прочая прочая - я был удивлён что мои в прошлом кумиры многие пали на дороге подвига и ввелись во искушение
Среда
Добро утро,
у нас первый вопрос - насколько генетическая компонента определяет политические предрасположенности (насколько помню, в том нашумевшем исследовании смотрели правых и левых, не то чтобы ген Единой России)
Я отвечу но не сейчас

Сейчас как я и обещал типы данных
Я пишу это не для общего развития, не для популяризации, мой сценарий скорее таков - как будто вы пишите мне и спрашиваете "завтра у меня собеседование на дата сайнтиста в геномный стратап Золотой Снег, что мне им говорить"
Ссылайтесь на конституцию, конечно, 51я статья.
Во всех правилах что я расскажу будут исключения (особенность области). В этом правиле исключений нет.
В общем, есть наверное три типа геномных данных с которыми вы столкнетесь - микрочипы (арреи), таргетное секвенирование, полногеномное секвенирование
Микрочип - набор из 100К-нескольких миллионов проб. Каждая проба = кусок ДНК, в котором закодирован какой-то человеческий частый (скажем >0.1%) вариант. Пробы слепляются с человеческой ДНК если этот вариант есть и начинают светиться
В итоге ваши данные (если перевести их в текстовой формат) выглядят как строчки: chromosome 1 position 666.666 reference A 0.99 alternative B 0.01. В нашем примере это будет означать, что интенсивность светимости варианта A гораздо выше чем B и наверное у нас есть только A
Важное отступление - референсный геном. Как бы мы не смотрели на геномные данные, по факту нас интересуют отличия генома от "эталона". Эталон или референс был собран титаническим трудом в 2001м (последний распространенный апгрейд в 2013м). Референс =
24 длинные строки (по числу хромосом) из букв ACGT и N (неизвестная буква), плюс куча обломков хромосом которые не получилось никуда присобачить, плюс митохондриальная ДНК.
Так вот секвенирование - это уже не просто заранее загаданный вариант слепляется с какой-то пробой и она светится, а мы уже реально читаем ДНК. Читаем мы обычно 100-150 букв за раз. Собрать эти короткие куски в одно сложно, гораздо проще найти место в референсе, откуда они пришел
(выровнять). Секвенирование бывает таргетным, скажем, экзомным - мы сначала извлекли ген-кодирующие участки из ДНК, их где-то 2% [конкретного человека] и секвенировали только их. Зачем нужен этот трюк - чтобы прочитать ген-кодирующие куски много раз. Секвенаторы нередко ошибаются
прочитав что-то много раз мы видим ошибки. Плюс секвенирование стоит денег - больше материал для сиквенса, дороже стоит. Многие заболевания вызваны проблемама в белок кодирующих частях, поэтому проблемы в таргетности для диагностики особой нет (гусары молчать!)
Если вы царь во дворца, вы можете секвенировать короткими прочтениями (100-150букв) весь геном и посмотреть не только на кодирующие участки, но и на "геномный мусор", который на самом деле часто оказывается "костылями", которые выглядят как мусор, "хм что если я это уберу"
бам всё зависло человек умер.
Сырые данные по чипу будут весить до гигабайта с человека, экзом 5-10ГБ, геном обычного покрытия (42х в среднем) 60-100ГБ.
Конечно это много данных. Чтобы перейти от сырых данных к данным для дата сайнса, нужно из сырых данных достать брульянты
а именно - варианты, отличия этого конкретного человека от референсного генома.
Проблема в том что варианты бывают разных типов и новые методы извлекают варианты более точно, поэтому даже когда мы достали только отличия, мы не удаляем террабайты данных, а пишем их в архив
Это значит что из хранилища они переезжают на магнитную ленту - дешево и сердито
Геномные данные в Германии и многих странах защищены законом, за утечку можно неиллюзорно сесть, поэтому все ваши облака докеры шмокеры - забудьте. Только локальный HPC кластер, как деды делали.
Был еще вопрос - как я, честный, порядочный, воспитанный человек, выпускник мехмата, стал валютным биоинформатиком
Что я могу сказать?
Повезло.
На последнем курсе мехмата (теория чисел и криптография) к нам приходили вербовать ФСБшники но это было так нелепо и смешно что даже не хочется писать. Оставался другой вариант - аналитиком в банк. Я прошел в несколько, но за несколько месяцев до того начал
читать книжки про эволюцию. Никогда биологией до этого не интересовался, но тут понял, что это любовь, барышня милая и все такое - я влип и в банки уже не пошел, а пошел в магистратуру по биоинформатике.
Отношения у нас абьюзивные, я пытался сбежать, один раз 5 лет назад прошел штук 5 собеседований в Яндекс на дата сайнтиста, но потом вне выслали тестовое задание и я сник. Неужели теперь до конца жизни считать какой из утюгов Тефаль значимо быстрее продается (no offence)
Мамы разные нужны, мамы разные важны, я уважаю труд любого дата сайнтиста (и в целом человека), но сам пойти в не-научный дата сайнс не смог.
Собственно, всё, мы живём с Биоинформатикой в одном доме с тех пор, бывает ругаемся, но знаете, милые бранятся
Уточнение: мои однокурсники ушедшие в Тиньковых Сбербанки хедж-фонды консалтинг сейчас получают миллион долларов в секунду и руководят полкАми
Да не собьет вас вся эта проникновенная речь с истинного пути - биоинформатик в Германии получает ок, но не сравнимо даже близко
@diimdeep Что-то такое я уже писал в медиум, но какие-то вопросы из списка затрону =) во многом ответы есть здесь medium.com/@german.m.demi… medium.com/@german.m.demi… medium.com/@german.m.demi…
мануальчик "что делать если вы сделали себе анализ ДНК"
там мнооого вопросов, в этом мануале нигде не подключается собственно больничка по сути, ответ на вопросы "что делать с моей ДНК самому/что делать с ней в больнице" разный twitter.com/dsunderhood/st…
Я решил по быстрому пробежаться по зависимости политических предпочтений (правые/левые) от генома
Ооо это горячая и противоречивая тема и видимо моё резюме - я не верю многому, но ассоциативная связь кажется есть
Давайте посмотрим на картинку из Атлантика, это корреляция между политическими предпочтениями одно/разнояйцевых близнецов ( theatlantic.com/politics/archi… ).
Вроде для близнецов выросших вместе у разнояйцевых корреляция меньше, как и доля общего унаследованного генетического материала
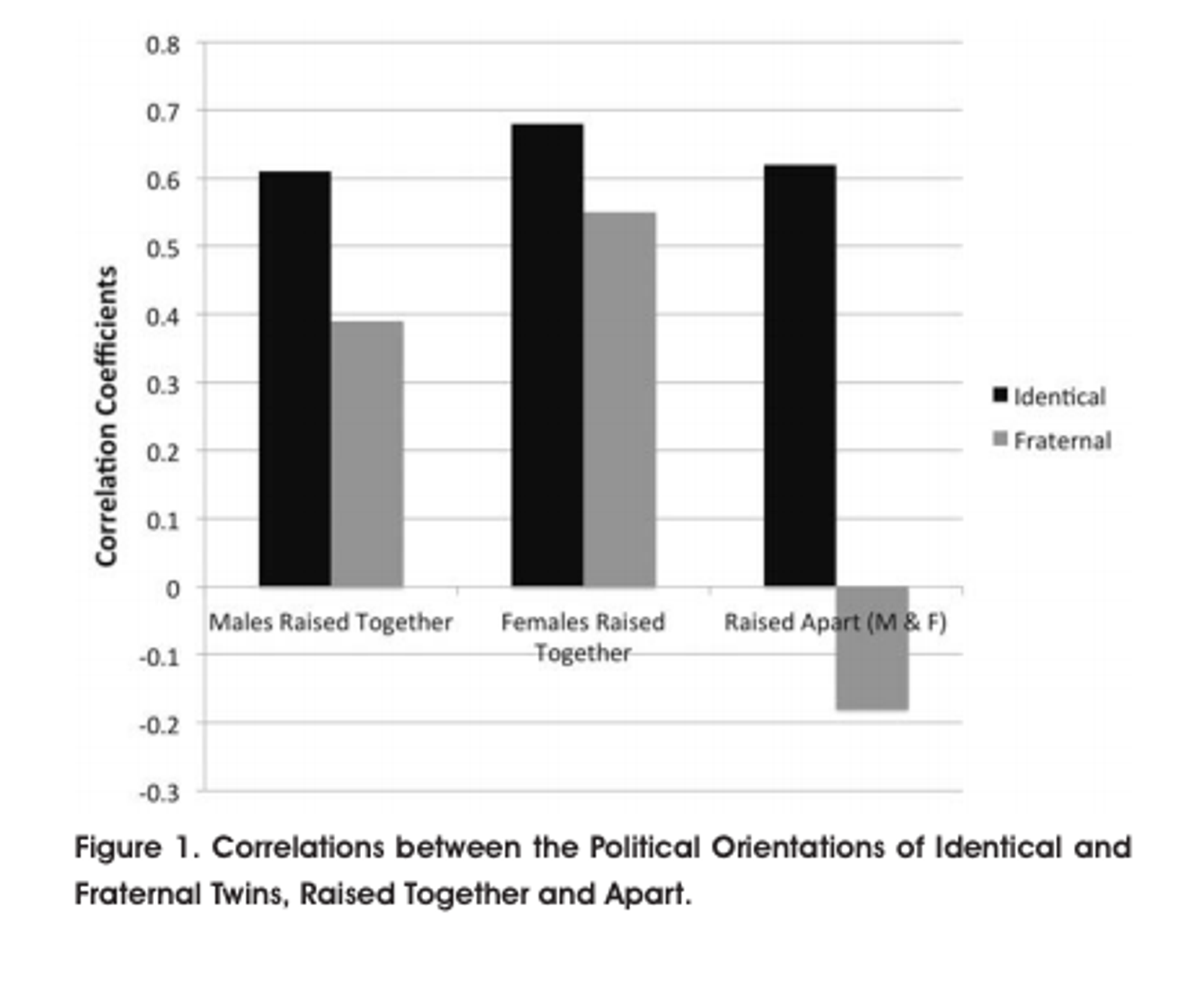
Но они и отличаются внешне от своих однояйцевых товарищей. Вдруг один из близнецов высокий и красивый, а второй маленький и толстенький (как я), и естественно первый будет тяготеть к такой-то стороне политики, а второй к другой? хахаха нет не скажу кто к какой мы тут не про это!
Генетика ли определила политические предпочтения? Через агента C, то есть не каузальная, а ассоциативная связь.
Почему корреляция для разнояйцевых близнецов, выросших раздельно, отрицательная - наверное дело в доверительных интервалах и что выборка раздельно росших мала
Я думаю можно сказать что это довольно вероятно, что генетика может определить политические предпочтения, но навряд ли это особый либеральный или консервативный вариант, скорее просто генетика сильно влияет на всю жизнь, а жизнь формирует политические предпочтения
биомедицинский дата сайнс - он всем дата сайнсам дата сайнс, проанализировав данные одним методом мы получим один вывод, другим - прямо противоположный, включил конфаундер X - написал статью что яблоки вызывают рак, выключил - яблоки лечат рак
Картинка из Атлантика серьезным источником быть не может и надо брать с десяток исследований по теме, мета-анализов, и взвешивать их на своих внутренних Байесовских весах, с добавками своего предыдущего опыта и интуиции. Поэтому don't take it serious, it is just for fun.
Байки нашего городка: в последнюю неделю по твиттору прошла волна возмущения модным стратапом, ведомым из Стэнфорда, который называется Orchid
Товарищи собираются отбирать эмбрионов по их полигенному риску заболеваний
Полигенный риск = общая сумма рисков, связанных с генетическими вариантами, рассеянными по всему геному. Каждый вариант практически не меняет риск, но в комбинации они могут давать серьезные изменения по части шансов диабета 2Т, сердечно-сосудистых, некоторых видов рака и тд
Отобрать эмбриона с низким полигенным риском это в целом интересная задача - вариант чуть-чуть понижающий риск рака груди может чуть-чуть повышать риск диабета (важно: это ассоциации а не причинно-следственные связи)
То есть нам нужно решать дикую задачу оптимизации рисков и всё для чего? Геномные риски не то чтобы радикально меняют всё в жизни. Процент объясненной вариабельности не больно-то и высок
В этой статье объяснена суть проблемы более строгими словами, но даже Стенфордские научные работники могут ввести людей в царство Абсурдистан
Мы обсудим полигенные риски в деталях позже, пока что очередная затравка
liorpachter.wordpress.com/2021/04/12/the…
Постепенно смещаясь в сторону темы 0 - большие исследования последних лет - затронем ФРЕЙМВОРКИ ФРЕЙМВОРЧИЩИ
вернее хотя бы просто инфраструктуру
nature.com/articles/s4158…
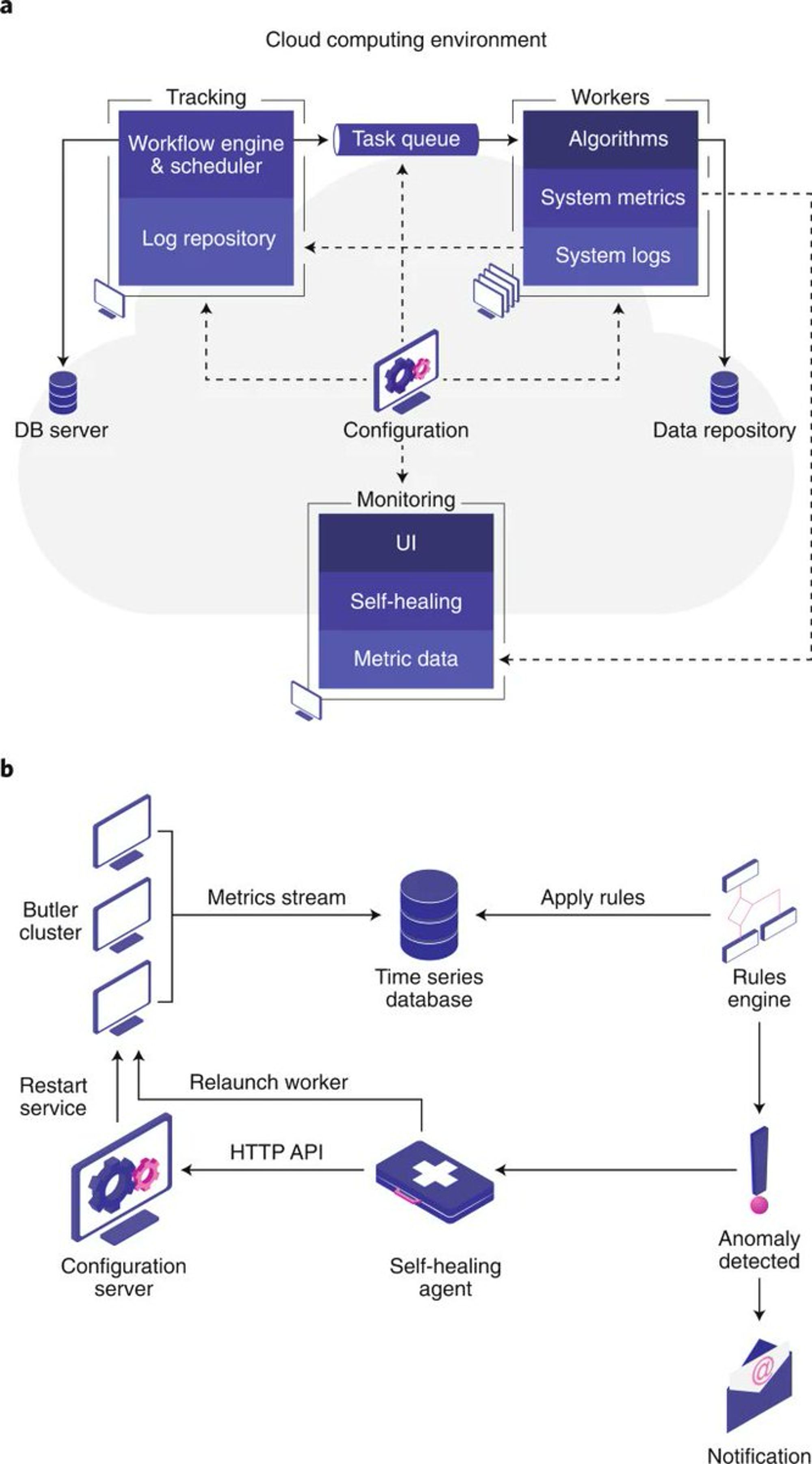
Вот таким образом пробежались по 725ти террабайтам данных.
В данном исследовании смотрели на около 2700 образцов рака, секвенированных полным геномом. На самом деле нужно делать двойную работу - чтобы понять, что там от рака, нужно смотреть сразу рак и не-рак от того же человека
We executed and successfully completed over 2.5 million computational jobs using 546,552 CPU hours.
The total amount of resources dedicated to the project by the Embassy Cloud was as follows:
1 PB Isilon storage shared over NFS
1,500 computational cores
5.5 TB RAM
40 TB local solid-state drive storage
10-gigabit network
Анализ был завершен кажется в 2018м году, поэтому сейчас возможно это не выглядит столь впечатляющим - в свое время меня сразило
лирическое отступление - наши [бывшие] "офисы"
расскажи этим сумрачным немецким парням как ты устал от своего кресла у окна в гуголе
(обратная сторона романтики научного датасайентизма)

зарплаты - TV-L 13
Зарплата растет с профессиональным уровнем, отработал год по теме - уровень (Stufe) 2, еще 2 года - Stufe 3, еще 3 - Stufe 4 и тд
HR сам по сути смотрит, по теме вы раньше работали или нет, и засчитывает или не засчитывает опыт
oeffentlicher-dienst.info/c/t/rechner/tv…
Цены по нашему городу не шибко актуальные по части продуктов, местами сильно завышены (где найти такие цены еще вопрос!), но в целом идею даёт - это очень дорогой для Германии город
завершая этот тред: поехал бы я делать то же самое куда-нибудь в СБЕР[банк] или Роснефть?
Было бы пару лямов
*****, у меня было бы пару лямов
Я бы поменял их не глядя
Хотя нет, не поменял бы
blastim.ru/job/3032/?fbcl…

переходим к крупным исследованиям
Проект 1000 геномов (около 2500 полных геномов со всех концов планеты)
PanCancer Atlas (около 10 тысяч пар рак-здоровая ткань, экзом + негеномные данные)
PanCancer Analysis Of Whole Genomes (около 2700 пар рак-здоровая ткань, полный геном)
UK Biobank Based studies (полмиллиона людей на чипах)
GnomAD (варианты в человеческих геномах и экзомах, всего около 200 тысяч)
Что такое, зачем нужны - всё расскажу в отдельных тредах
Забыл
RoadMap Epigenomics + ENCODE(эпигеномные данные с разных типов клеток)
GTEx (транскриптомные данные, около 700 человек разобрали на части и посмотрели экспрессию генов post mortem - ничего криминального, смерть не по причине исследования)
краткий тред до совещания
интересные курсы по ML из Тюбингена
Конечно школа MLSS. Я был в 2019м в Лондоне и там я понял что я не знаю ML.
mlss.tuebingen.mpg.de/2020/
Курс Probabilistic Machine Learning от Prof. Dr. Philipp Hennig
youtube.com/watch?v=M2fUmh…
Математика для ML от Prof. Dr. Ulrike von Luxburg
youtube.com/watch?v=PZwxF5…
Statistical ML от нее же
youtube.com/watch?v=WB8eYZ…
Долгими карантинными вечерами я смотрел эти курсы (хотя не закончил) - возможно, кому-то еще будет интересно
куда мы движемся, что ждать обычному человеку от анализа генома - в этой короткой заметке (США)
serious data flow is expected from there =)
я бы сказал - дата щас фонтаном забьет, поэтому при всех минусах профессии - скучно не будет
blogs.cdc.gov/genomics/2020/…
Тут будет тред твиттер аккаунтов которые я читаю и возможно рекомендую
Я не буду отмечать авторов через @ , буду приводить только ID, поэтому вам придется копировать и смотреть, если интересно
Порядка нет
CT_Bergstrom - эпидемиология, скандалы, интриги расследования. грамотные разборы.
robtibshirani - крутой биостатистик, на которого постоянно ссылаются на конференциях
statsepi - довольно циничный твиттер с высмеиванием разных плохих практик
segal_eran - новости из Израиля про пандемию, прямиком в твою твиттерскую ленту без фильтров телевизора/СМИ
ADAlthousePhD - тоже чаще всего репосты/высмеивания
BenWestphalen - клиинческая онкология, новости новых подходов и клинических испытаний
ChelseaParlett - мемасы тиктоки приколы про статистику
betanalpha - мега научный работник, ML с тяжелой математической нагрузкой
MaartenvSmeden - просто лучший, эпидемиология/статистика
cecilejanssens - много твитов про геномные риски, в целом много критики других работ
d_spiegel - супер понятный взгляд на пандемию из Британии, автор клевых книжек
lpachter - разнос всех по методам, 80го уровня
f2harrell - мой статистический кумир, записываюсь на все его курсы
healthstatsdude - тоже рассказы о тяжелой доле статистика
LaurelCoons - всё обо всём в удобной лёгкой манере
StatModeling - просто Эндрю Гельман
Я сейчас работаю в большом консорциуме, в который входит институтов 20, мало того что я скачиваю данные ВСЕГДА (их так много что за последний год я не скачивал что-то может пару недель, у нас I/O трещит на кластере), так еще и совещания постоянные по несколько часов
В таких консорциумах в геномной биоинформатике все зависят от всех, одни получают одни результаты, отправляют другим, те делают свой анализ - отправляют третьим - очень тесный граф и всё (в идеале) должно быть четко расписано по времени

Поэтому на сегодня я наверное все, а вы можете пока мне фидбека пачку накидать - что плохо? еще не поздно всё изменить и выгнать меня из-за штурвала (да не, шучу, уже поздно)
По вопросам помню - как из ненаучного ДС прыгнуть в какую-никакую геномику и иже с ним
Кажется в этом аккаунте так принято - давайте я расскажу о своих хобби
Я увлекаюсь осознанностью, криптовалютами, пикапом, развитием духовности, тантрой, еще я биохакер
В качестве дополнительного заработка продаю хурму и детей
Шучу, шучу, какая хурма в апреле
Все так напряглись, я чувствую
Никого обидеть не хотел, это прекрасные хобби!
На самом деле у меня нет особых хобби и я уверен что каждый подписчик мне сто очков в этом вперед даст, по части насыщенности жизни
Поэтому я буду рассказывать только то, что (надеюсь) интересно
Хотя...есть у меня одно хобби...даже два...
youtu.be/tg_-uIzzSRs
Last tweet in this thread. The Introduction to Machine Learning course is now complete. It was fun! Videos: youtube.com/playlist?list=… Slides: dkobak.github.io If you spot any mistakes, let me know. And see the same Youtube channel (Tübingen ML) for more advanced lectures! https://t.co/Hm3yE4bC0a
Забыл, забыл! twitter.com/hippopedoid/st…
Четверг
Тред про мои хобби
Осознанность. Мне чёто объясняли. В общем по ходу надо думать а потом делать, и думать прям без шуток. Осознавать.
Криптовалюты. Система такая. Бедные индусы видят, что биток растёт, и вкладывают свои накопления за жизнь (мб тыщу баксов) в биток. Разве твоя проблема? Не. Биток растет, а вечная мерзлота греется. Ну и что, что затраты на майнинг как вся электроэнергия Аргентины.
Тантра. Лет десять назад я слышал что есть тантрический секс. Это когда долго. Говорят, прикольно, не знаю, не пробовал
Духовность. Надо думать о высоком. Не то что как всякие тупые про биток и про тантрический секс, а про душу.
Биохакерство. Надо есть витамины и читать пабмед. Так проживешь до ста лет. Ещё надо бегать. Опять же, духовность и осознанность продлевают жизнь. В пабмеде должна быть статья.
Это сатирический текст, высмеивающий мой узкий кругозор. Прошу не обижаться!
Ещё пассивный доход это круто. Пассивный доход это когда ты богатый. Живешь себе, шашлык кушаешь, а деньги капают. Если у тебя есть пассивный доход, то есть ты просто богатый, можно не работать
Когда ты богатый, важно не просто заниматься тантрическими сексами, а быть осознанным и духовным, иначе удовольствия от пассивного дохода не будет
Доброе утро :)
Что общего между битками и биоинформатикой?
И для того и для другого есть специальное железо
Во втором случае оно плохо апгрейдится, очень дорогое, но насколько же Драген быстрый....
illumina.com/products/by-ty…

Секвенирование длинными прочтениями, поиск вариантов в них, гоняют deep learning ом на видеокартах, ясное дело, на чем же ещё делать дип лернинг
Чтобы дать идею насколько быстрый - «The DRAGEN Platform can process NGS data for an entire human genome at 30× coverage in about 25 minutes on premise vs. > 15 hours with a traditional CPU-based system.» Притом базовый софт оптимизирован и написан на очень низком уровне уже
Зачем нужно ультра быстро делать анализ?
Несколько лет назад мы шутили что мы единственное отделение в больнице где не бывает «тревоги» - застава в ружьё, все в пятую палату
Че нам там искать, делецию на 2p хромосоме?
А потом люди поняли, что некоторым новорожденным
Нужен моментальный анализ генома. Ultra rapid. Потому что понимать и лечить нужно вот сейчас.
Так что мы дошутились.
Засим располагаемся мы в 50 метрах от женской клиники, а раньше вообще в ней были, что послужило бесчисленным источником шуток среди моих знакомых
По быстрому накидаю мыслей, что делать если хочешь перейти в биомедицинский DS
Первое - нужно понять какая область биомедицины интересна. Люди с абстрактными идеями "хочу излечить человечество от рака" здесь не задерживаются. Хотя приходят и из гуглов.
Второе - есть четкое различие между биоинформатикой и (эпи)геномным дата сайнсом. Их можно смешивать (как я - где-то 50 на 50), но это разные области. Первое это Computer Science и алгоритмы, второе - классический DS со сдвигом в интерпретабельность
Есть еще много других областей биомеда, где я ничего не понимаю (скажем анализ изображений, гистологии, есть рак или нет рака). Сюда ждут хардкорных MLщиков и интерпретация каждой фичи здесь не нужна.
Курсы - из того что прям в мою область дает пинок, вот этот. Он не супер, видно что сделали и забили - но информация ценная. Для других областей нужны другие курсы и чем больше - тем лучше.
coursera.org/lecture/person…
Вообще если вы уже суровый дата сайнтист, я бы все-таки поискал бы вакансии, требования и подался бы. В этой области большая нехватка кадров - возьмут, куда денутся с подводной лодки.
Если вы только начинаете, у меня где-то валялся старый мануал - он не то чтобы мега устарел.
На мой взгляд главное - найти свой интерес, а дальше путеводная звезда выдаст вам тыщи видосов и курсов по вашей теме. Ну и пробовать подаваться!
habr.com/ru/post/390563/
Если интерес у вас уже есть - пишите тему сюда, я попробую по вашей теме найти что-то стоящее, возможно, я брал эти курсы (список у меня в линкедине вроде был).
И конечно NGSchool - временно в гибернации из-за ковида
ngschool.eu/ngschool2019/
Большие исследования (а значит большие данные)
1000 геномов
Если на клетке с тигром написано лев - не верь глазам своим
Там было 2.504 генома (нынче уже 3.2K)
internationalgenome.org
Это популяционное исследование, туда набрали ДНК людей из супер разных популяций (видно на карте). Секвенирование было не очень глубоким изначально, что позволяло слить образцы вместе и найти частые варианты, но не позволяло найти редкие варианты с хорошим False Discovery Rate
Для чего нужно: первое это конечно тесты вида "насколько ты индус". Можете скачать VCFки (variant calling format), положить туда свою геномную VCFку и увидеть где вы на PCA окажетесь
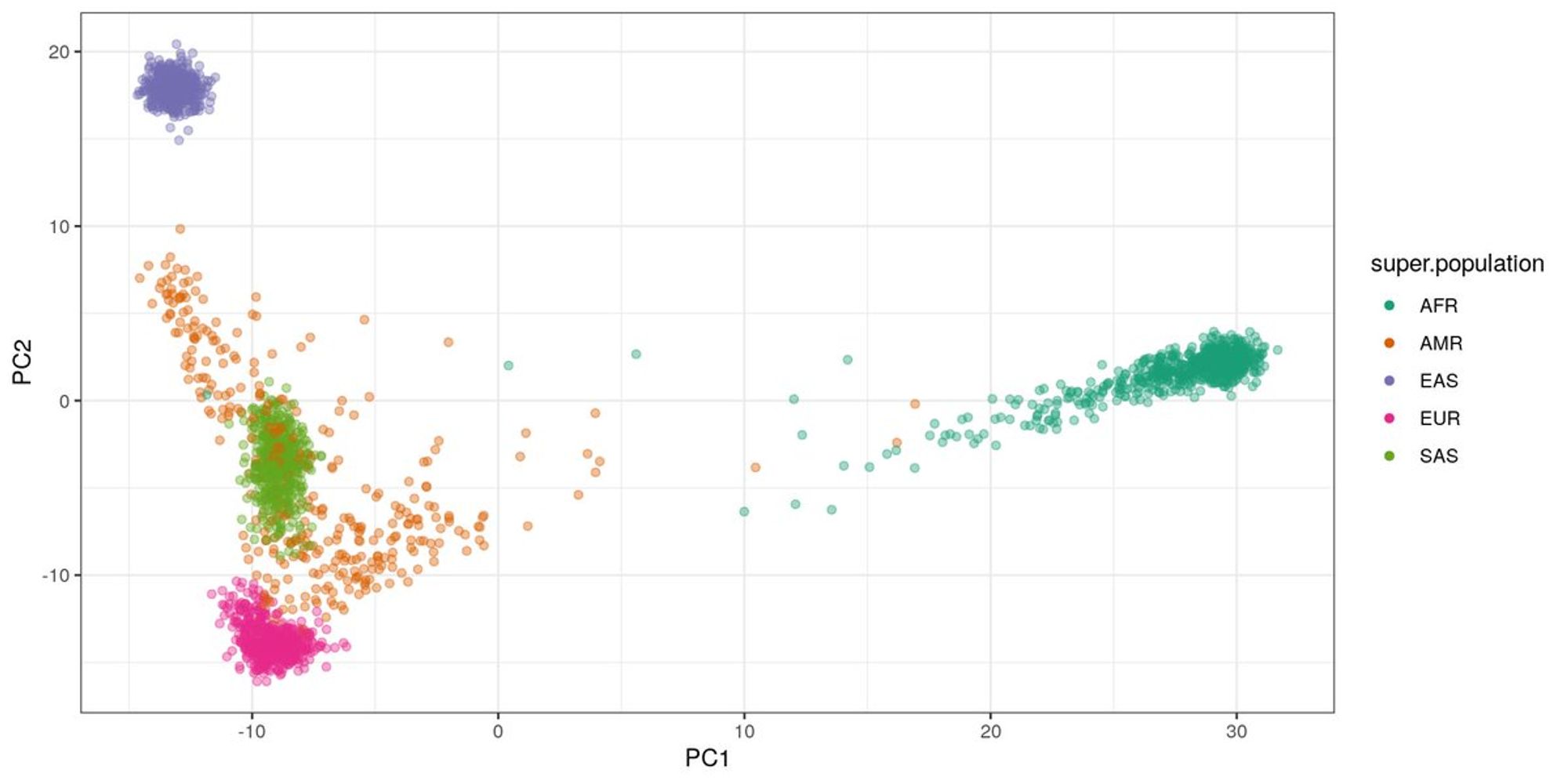
Второе - linkage disequilibrium. Мы знаем, что близко расположенные варианты часто наследуются вместе (потому что когда происходит оплодотворение яйцеклетки хромосомы не то чтобы часто ломаются и склеиваются, см кроссинговер).
Это позволяет нам, имея всего несколько сотен тысяч точек, разбросанных по геному, примерно понять, какие еще варианты у нас присутствуют. Это же используется для поиска ассоциаций с какими-то признаками - нам не нужен каузальный вариант, нам достаточно ассоциированного прокси
Третье - это хороший каталог структурных вариантов. Индивидуальный геном это не только точечные мутации, но и большие перестройки в 100-100K и более букв в ДНК. Искать структурные варианты сложно, потому что мы не можем [не могли] прочитать длинный кусок ДНК за раз
С помощью 100буквенных прочтений (попарных, мы знаем расстояния между парами прочтений), алгоритмов и такой-то матери мы можем примерно найти структурные вариации, но это все еще сложно.
Данные на поиграцца
internationalgenome.org/data-portal/sa…
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/
Я только что заметил что там есть геном чеченца и геном чукчи - вы знаете что делать, если вы уже делали где-то генетический тест
Я заранее извиняюсь
прозвучала критика - мол, если даешь список твитторов интересных людей, тегай их! тебе лень что ли!
я прекрасно понимаю что тема, которую я рассказываю, интересна ну процентам 20 от читателей этого аккаунта
если вам лень скопировать и вставить твиттор ID - вам оно и не надо
Сегодня я вылетаю правительственным рейсом в страну, где замедлен твиттор, поэтому возможно мучения тех 80% читателей, которым не интересно, закончатся раньше =)
Поэтому мне надо ускориться на всякий случай и выдать горку тредов, раз обещал - не пугайтесь количеству
Вообще, какой части читателей интересна ли эта тема? (датасайнс в пересечении с биоинформатикой)
Welcome to PanCancer Atlas
11 тысяч опухолей (в паре с нормальными тканями) из 33х типов самого распространенного рака
cell.com/pb-assets/cons…
Вот моя лекция с 2018го года с летней школы
youtube.com/watch?v=Ij8QYP…
Что прикольного? Помимо генетики, эти 10К образцов опухолевых тканей прошли еще кучу анализов - профилирование экспрессии мРНК, микроРНК, метилирования, протеомика
Каждый тип данных надо по-особому нормализовать и хочется узнать
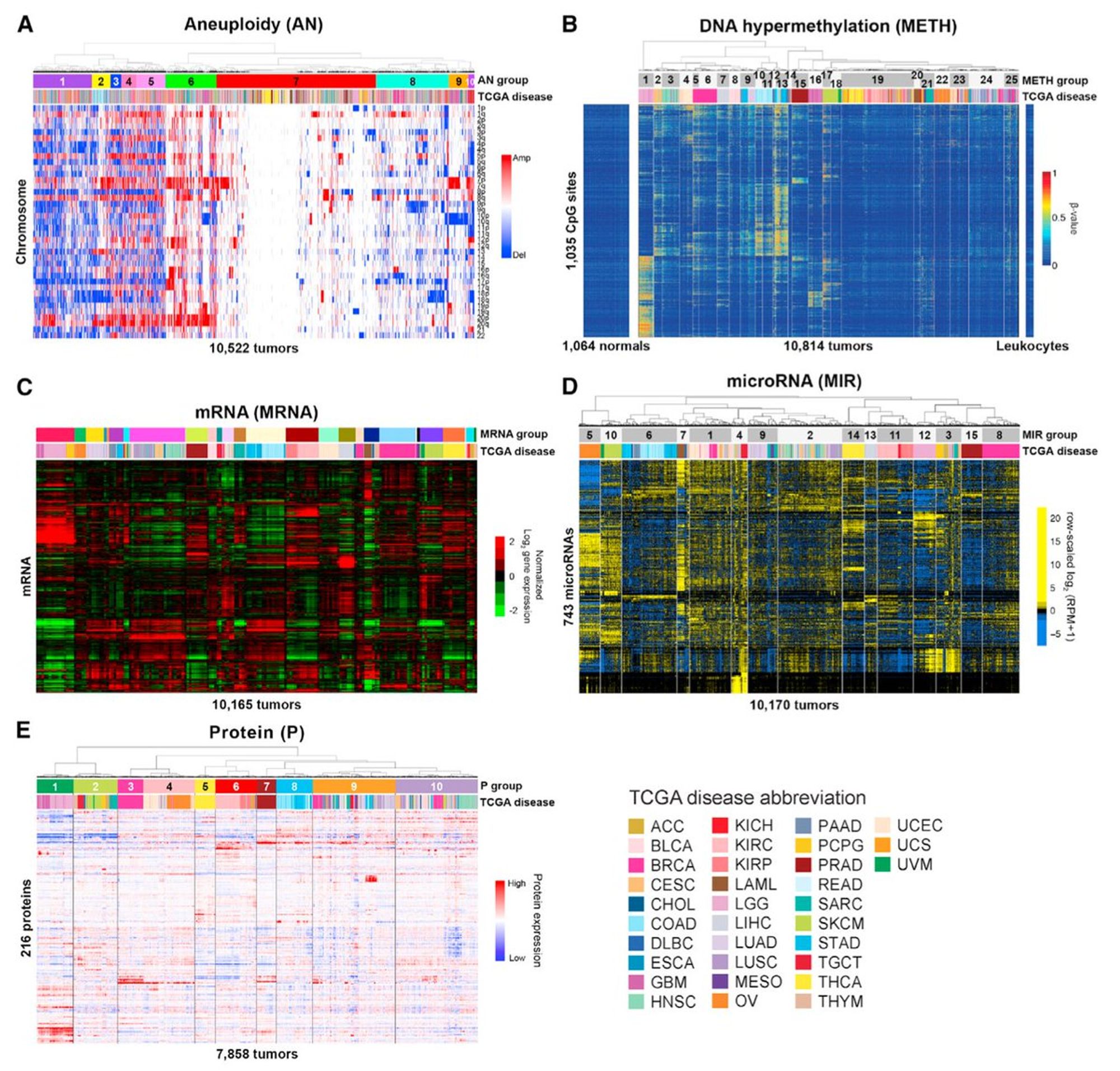
а правда ли клиническая классификация норм? Для этого использовались два метода кластеризации - Кластеры на Кластерах (CoCA) и iCluster
Благодаря этим методам мы можем узнать, какая именно размерность являлась определяющей для кластеров, какая характеристика общая
вот такая получилась кластеризация (2 верхних графика - по двум методам), снизу слева - профили кластеров (насколько они гетерогенные исходя из изначальных типов)
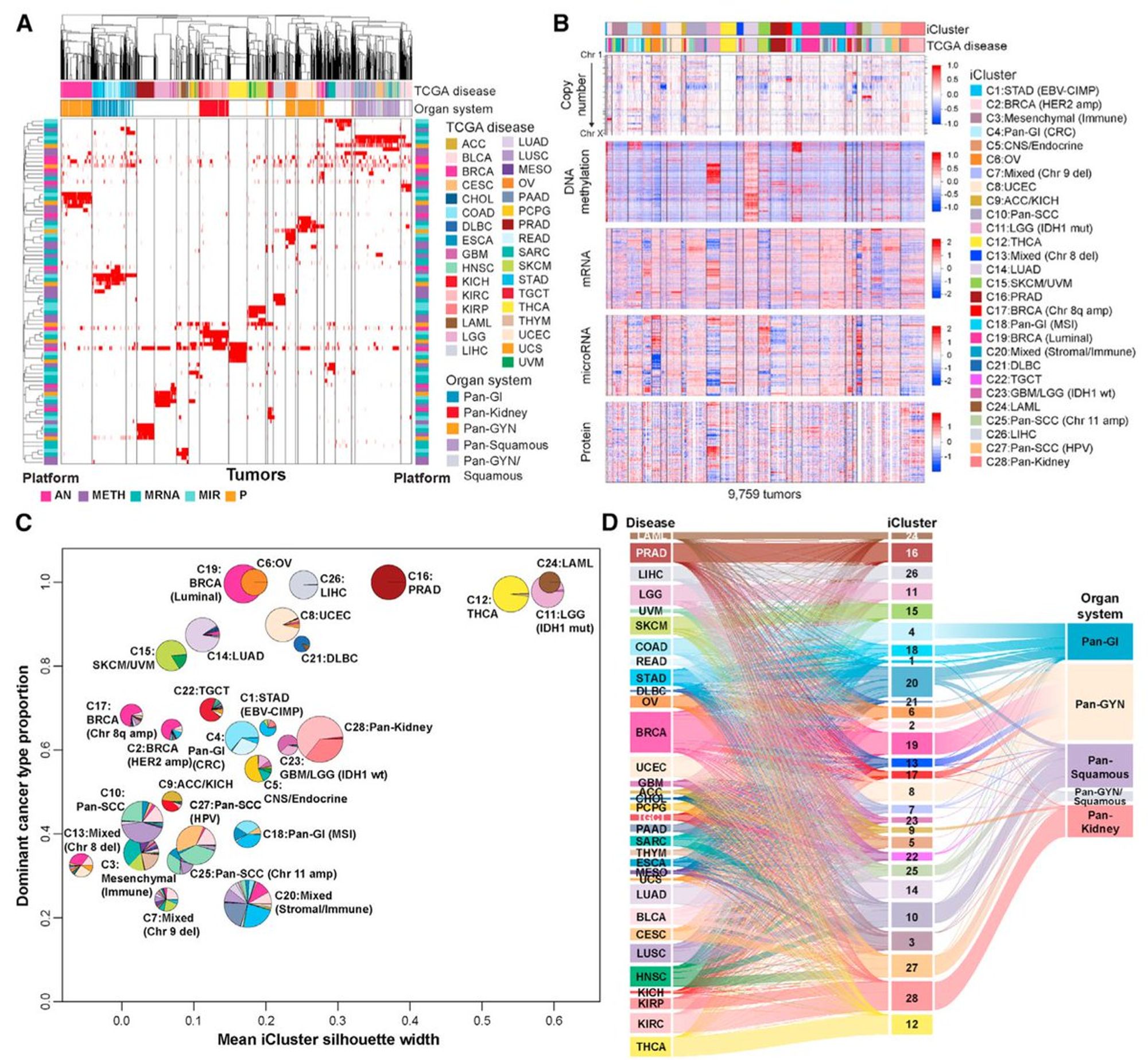
iCluster еще нарисовал такую замечательную картинку, которую можно вертеть и аннотировать и получать инсайты
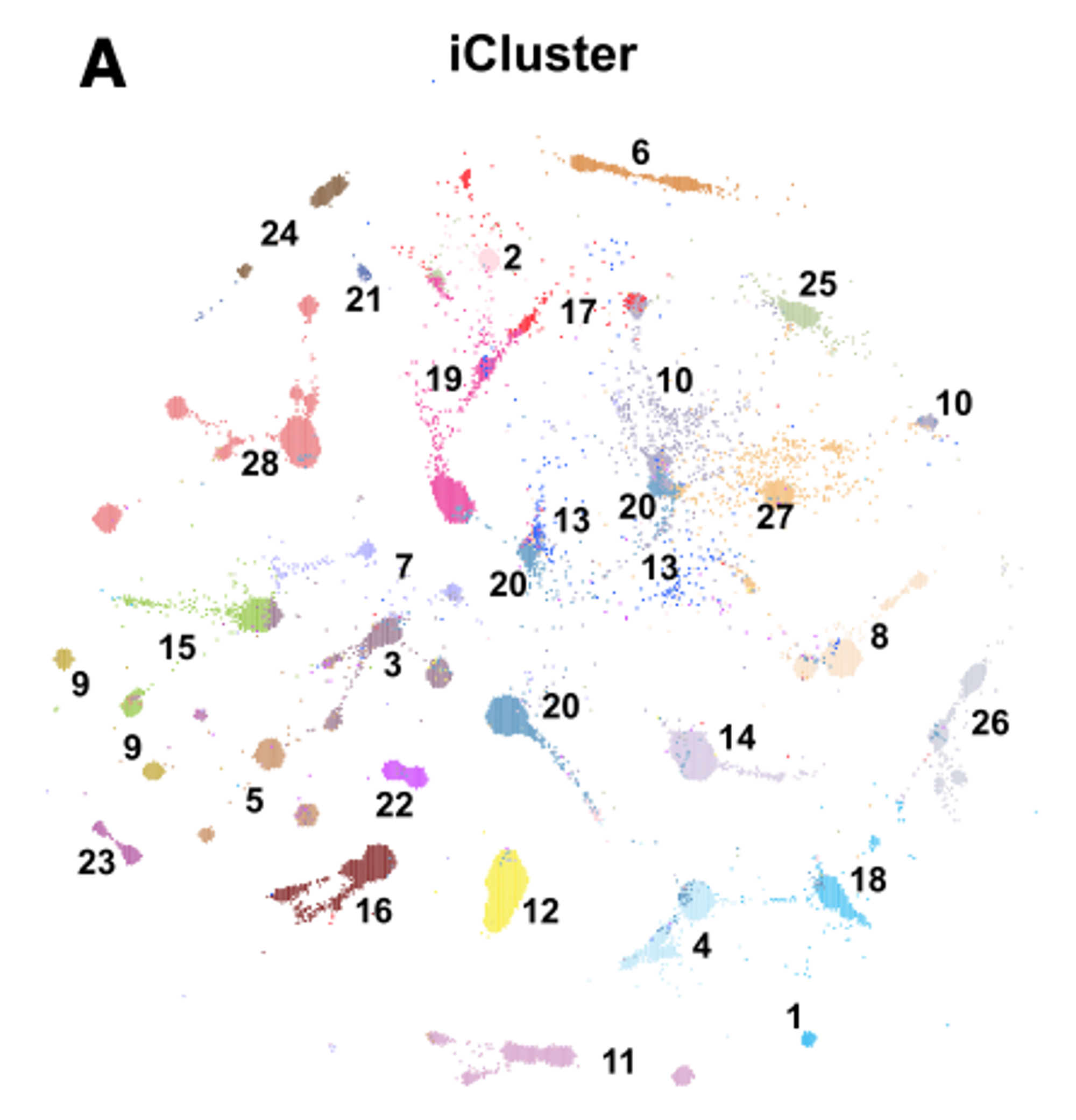
Summary: если вы будете заниматься чем-то, связанным с раком, вам необходимо прочитать десяток работ из этого атласа, скачать данные и понимать, как и что связано.
Многоуровневая кластеризация - тоже прикольный метод
cran.r-project.org/web/packages/c…
rdrr.io/bioc/iClusterP…
Все изображения принадлежат правообладателям и использованы в иллюстративных целях
Следующее большое исследование - PanCancer Analysis of Whole Genomes
2.7K пар опухоль-здоровая ткань, только геномика, только полный геном
Мои слайды тут docs.google.com/presentation/d…
Портал с данными dcc.icgc.org/pcawg
Что может быть интересно дата сайентисту?
Во-первых, такая задачка - у нас есть объект, он получает повреждения. Чем раньше происходят повреждения, тем большую доля "объекта" они затрагивают. Как статистически сделать тайминг этих повреждений?
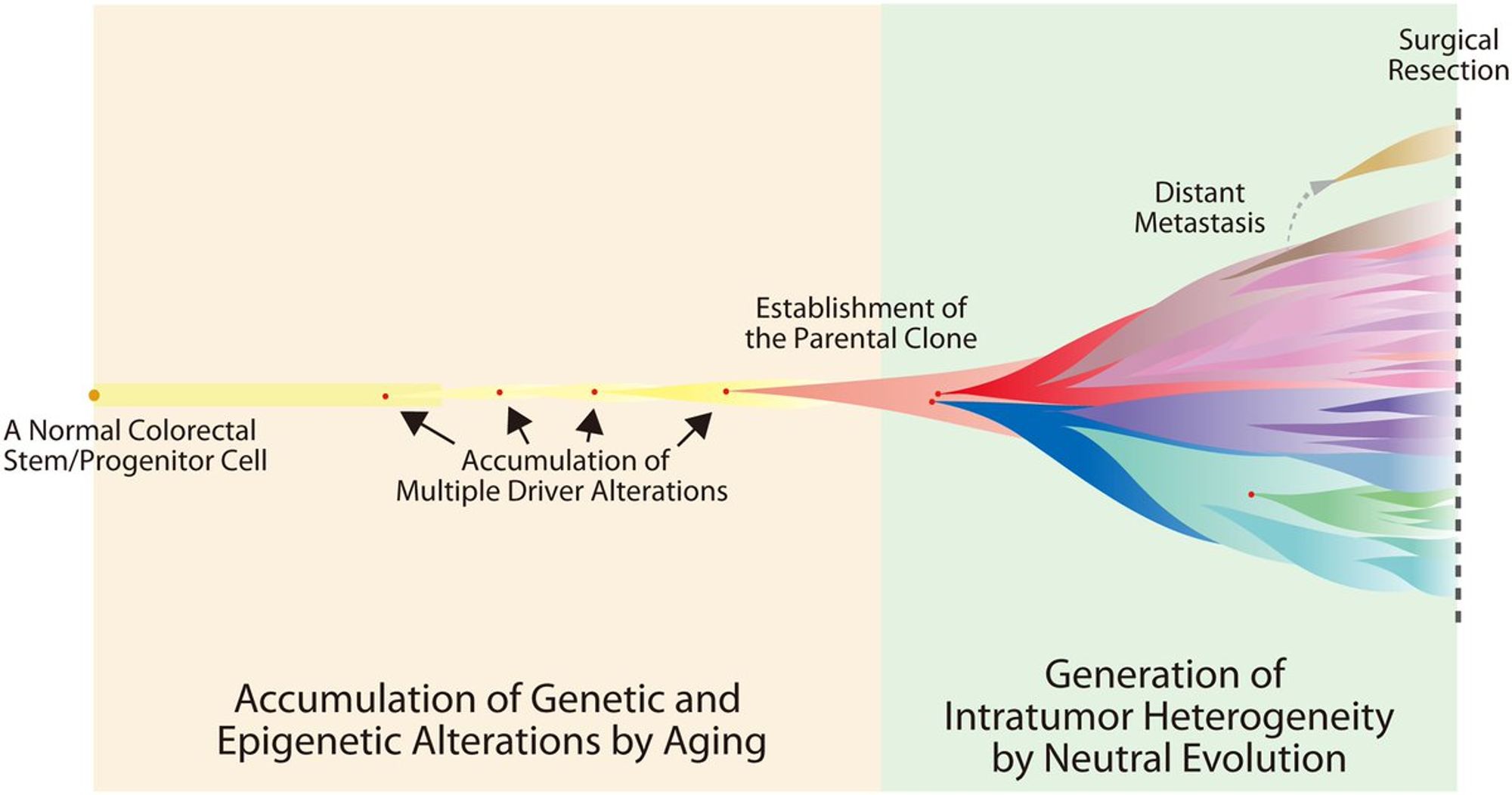
Вторая задачка: у нас есть процессы, которые приводят к повреждениям объекта определенного вида. В нашем примере скажем курение - не просто ломает геном, оно меняет буквы определенным образом в определенном контексте. Как разложить поврежденный объект по тому, что его повреждало?
Вот так скажем выглядит профиль повреждений от курения.
Задачка изначально - разложить матрицу 96 на 2800 (по числу образцов) по базису и присвоить названия типов повреждений векторам из базиса (non-negative matrix factorization)
cancer.sanger.ac.uk/signatures/sbs…
Вот так выглядит тайминг мутаций и разрушений разных генов для одного из видов рака - по оси X время, по Y гены/варианты, которые типичны для данного типа рака
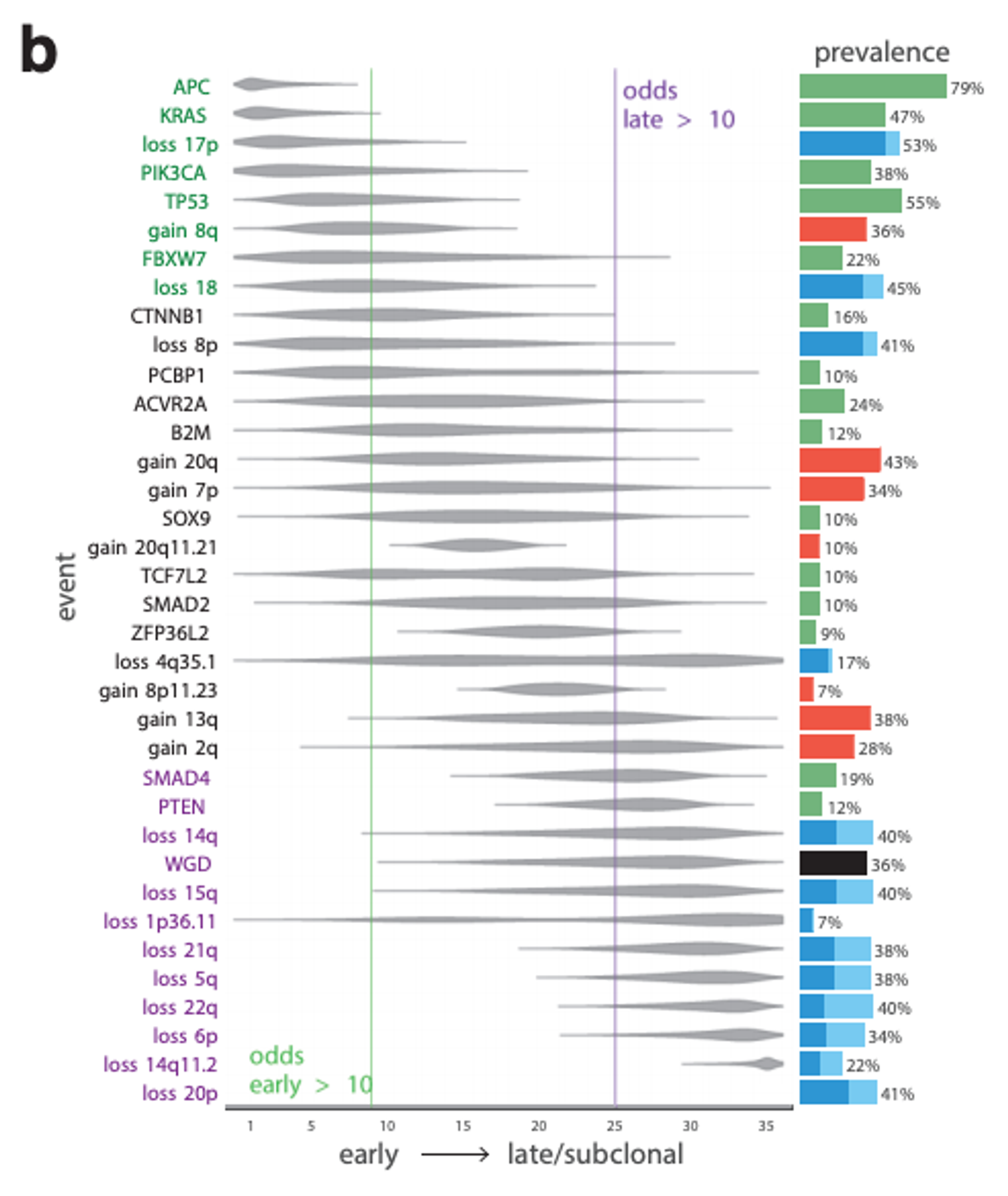
А вот временной тайминг - как много лет занимает развитие разных опухолей (под разными сценариями скорости эволюции). Какие-то опухоли, как видим, зреют долгими годами - было бы хорошо их находить раньше, но это биоинформатика и это я рассказывать не буду =)
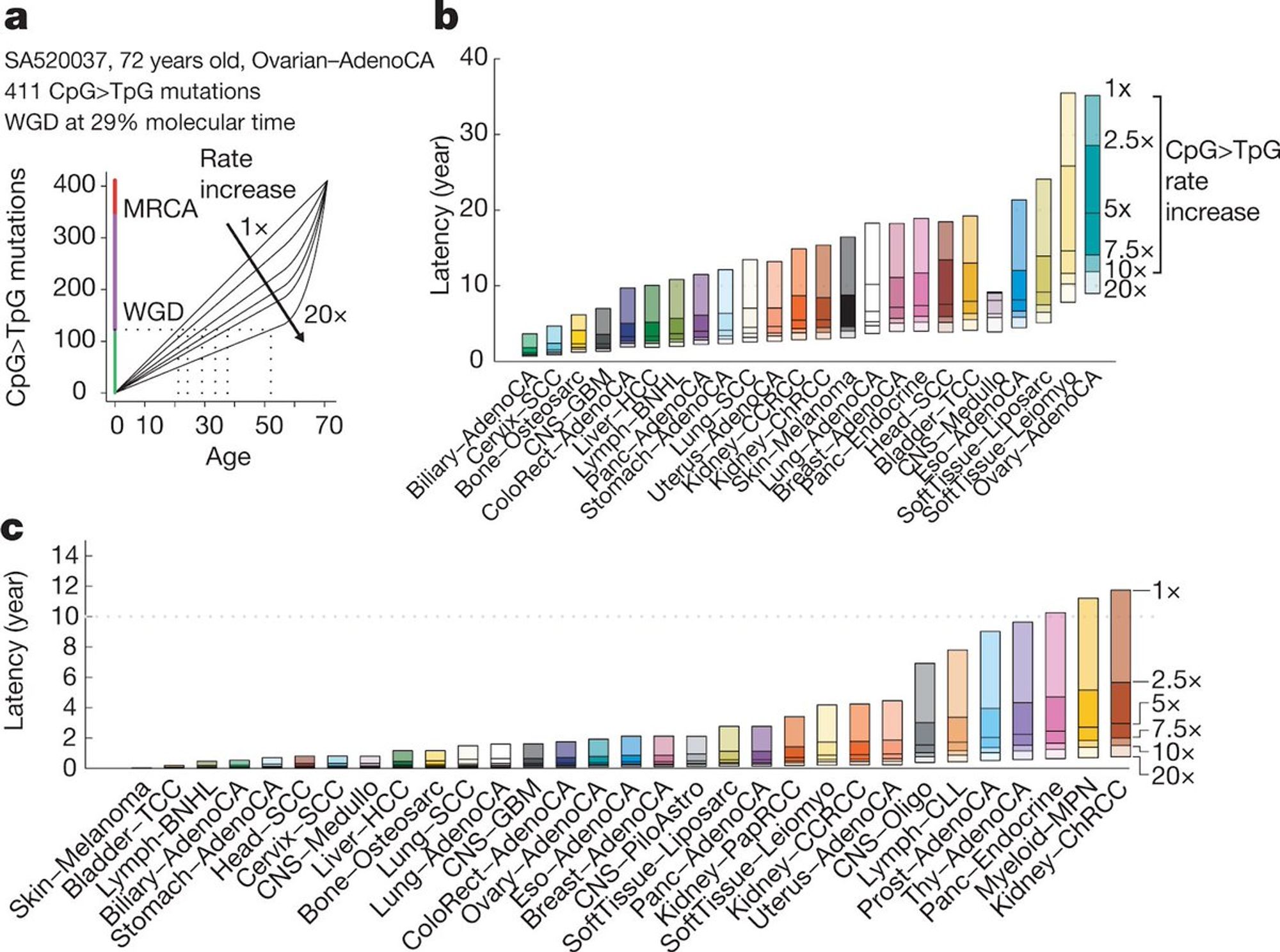
Такие пи ро ги, спрашивайте детали что непонятно, смотрите слайды
Забыл - следующая задачка, решается лучше всего дип лернингом
Клетки каждого типа сворачивают свою ДНК в определенных местах (она недоступна потому что компактно сложена) и разворачивают в других - как, не зная типа рака, только его мутации
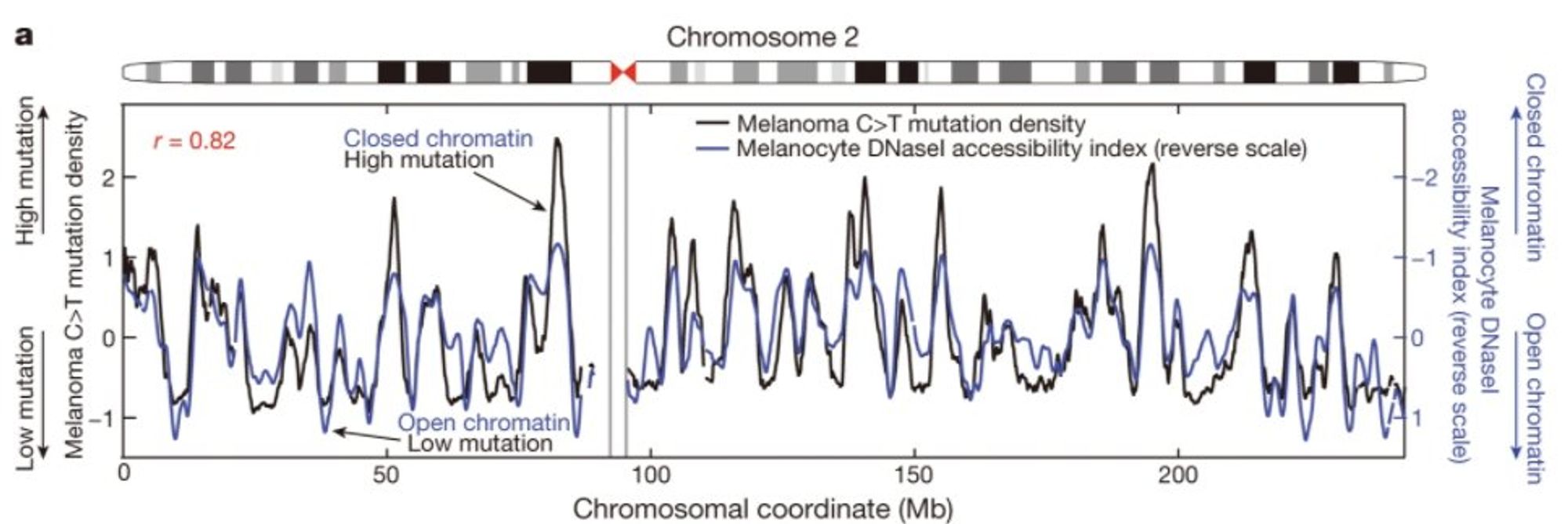
Понять в клетках какого типа он возник?
Натренировать нейронную сетку
Она будет сравнивать видимый профиль и возможные профили из разных клеток (скажем клетки кожи, или нейроны, или клетки печени) и находить нужный.
Нужно чтобы решать опухоли, которые пришли непонятно откуда
пока только 0.003-0.091 от читателей данного канала бешу лично я (95%CI, binomial) - это неплохой знак!
число людей которых бешу лично я растет - потому что они реже заходят на страницу и голосуют
я поступлю как типичный "эксперт политолог" - скажу что эти люди "на грани статистического шума"
кто-нибудь понимает, что имеется в виду под "3% это на грани стат погрешности"?
Кстати сообщество, а реально - твиттор тормозят? У меня как то vpn только по работе был
Меня каждый раз удивляет, когда кто-то говорит что-то вроде "твиттер худшая соцсеть"
Это вообще соцсеть?
Я тут только авторов разных фолловлю, препринты, статьи из первых рук с нулевой задержкой
Кажется, есть где то потайной твиттер - худшая соцсеть - но меня туда не пускают

А расскажите в реплаях, кто работал с геномными или вообще медицинскими данными? Кто работал в больнице, статистика или что подобное? Что делали? Что вам показалось странным?
Посмотрим сколько нас!
Чето нас ваще не много. Я когда на школе по ML (обычному) был, из 200 участников четверть наверное работало над этим непосредственно вот сейчас...
Пятница
Надо поменять в шапке профиля "из Германии" на "из деревки"
Твиттор тут не тормозят, сегодня один тред по плану, про то как работать с данными тысяч пациентов и не поехать кукухой
А пока всем хорошего дня, я тоже поеду наслаждаться постковидным обществом

Всем доброго вечера/дня, как обещал - способы не поехать кукухой делая дата сайнс в больнице
Кто я такой чтобы давать советы как не поехать кукухой? успешен ли я в этой сфере? нет.
Возможно поэтому я и решил раздать советов

Начнем с того, как описывается фенотип (совокупность внешних признаков) у больных в базе данных
Это делается через HPO terms. Есть такое дерево фенотипов - от корня к листьям, от общего к частному
ebi.ac.uk/ols/ontologies…
Соответственно задачки нечетких совпадений множеств на деревьях возникают постоянно
Гены и заболевания обладают некоторым маппингом, несколько ключей могут отображаться в одно значение в обе стороны
например вот этот лист дерева фенотипов описывает микропенис
это вообще не смешно и это реальный симптом
hpo.jax.org/app/browse/ter…
так как доступ к клинической информации есть только у докторов, то что имеют биоинформатики - наборы HPO термов, описывающих пациента
и да, сотни из них нужно зачастую смотреть глазами, сравнивать с тем что ожидается от гена, который ты предполагаешь что был нарушен
пропускаешь сотни таких историй через себя и они иногда очень тяжелые, и это тоже learning =(
когда упираешься в хорошую находку причины заболевания у кого-то из пациентов - находишь доктора и вы обсуждаете полную историю болезни пациента чтобы понять, подходит находка или нет
в начале когда я перешел из чисто научной работы (чисто дата сайнс на больших датасетах где не нужно разбирать отдельные строчки-образцы) меня прямо трясло от некоторых историй потому что они были мега страшными
самой жесткой историей была находка таинственного убийцы - поврежденного очень хитрым образом гена - который убивал членов одной большой семьи через рак кишечника
мы нашли этот вариант в образцах 10-ти летней давности и запросили данные что с этими пациентами сейчас
Все мертвы, майор!
В общем у меня было несколько ситуаций когда я падал на самое дно
Впечатлительным тут плохо
Особенно плохо когда дата сайнс подменяется биоинформатикой и ты спускаешься с уровня датасета на уровень пациента

Там уже полная ответственность, это ведь ты или твои коллеги не нашел или неверно нашел в своей время причины
И о за плохую интерпретацию могут и посадить и дать штраф, так что тут не только в чувствах дело
genomeweb.com/molecular-diag…
Еще хуже делает то, что пациентов мы видим. Не на приеме, но когда они идут с/на прием. Мы не знаем, кто этот пациент, с нашими записями в базах данных он не соотносится, мы не знаем имени - но мы видим
Особо тяжело для молодых людей с раком (таких часто не видно, но иногда прямо видно) - мы подбираем терапию с помощью всяких decision support system, но до сих пор не знаем насколько хорошо подбираем потому что evaluation в рамках одной клиники сделать сложно
WARNING графический контент следующим твитом
Это пациент лет 40ка с запущенной меланомой, слева до терапии, в центре через несколько недель после таргетной терапии (BRAF ингибитор, по результатам ген анализа) и справа еще через несколько недель
Пациент умер вскоре после того как сделали фото справа
melgen.org/can-trick-mela…
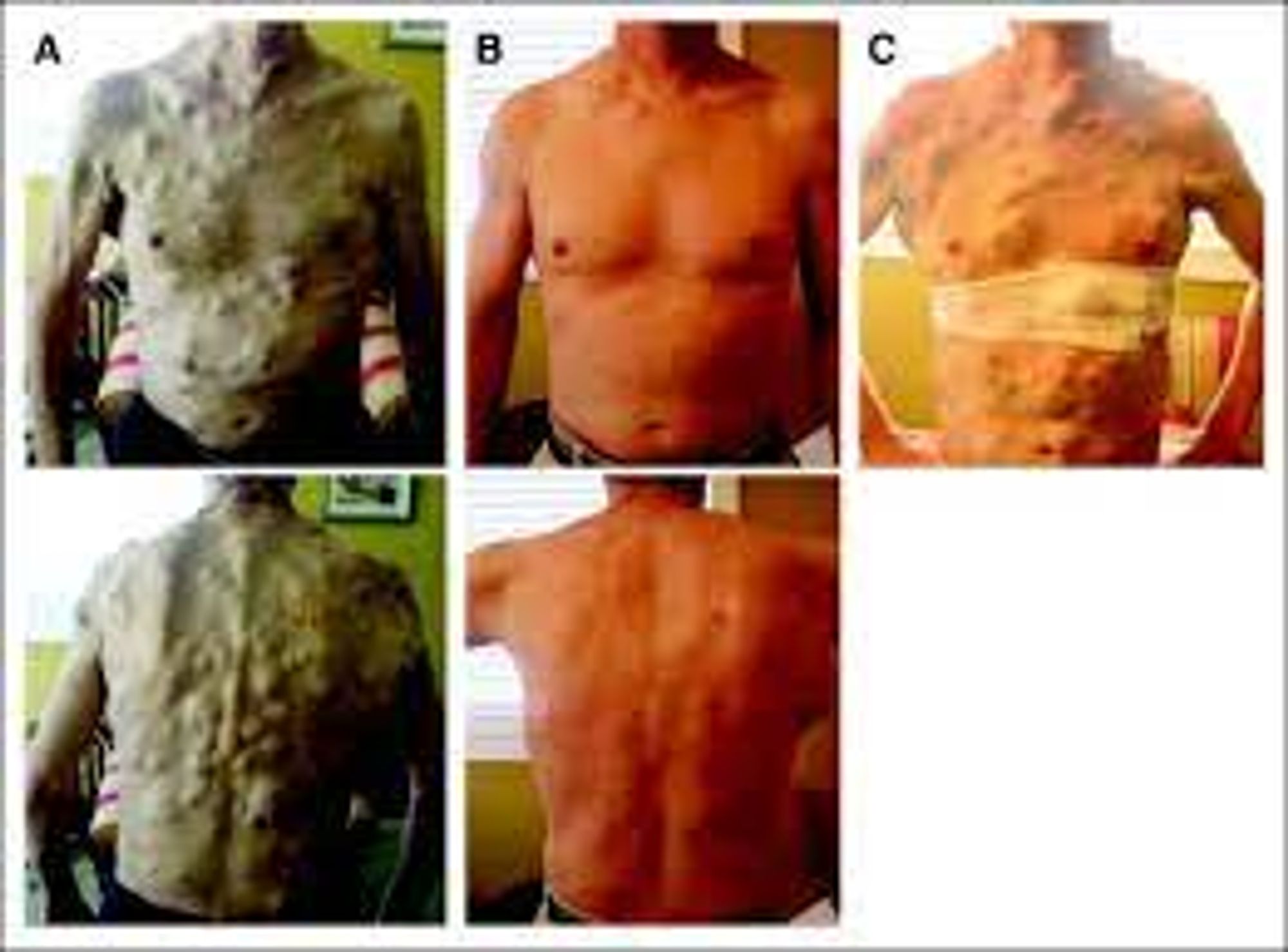
Рак избежал таргетной терапии
Мы не врачи и не были готовы ко всему такому
Мы не прошли мединститутов и у нас нулевая психологическая подготовка к таким вещам
Мы превращаемся в циничных (хуже чем врачи) мерзких дядек и тётенек - мне стыдно как мы шутим между собой
Такая форма психологической защиты
Мои советы: 1) избегать работы с одним пациентом - только дата сайнс, только датасет; 2) не оставаться одному, всегда стараться быть в компании друзей и если бухать то только в компании; 3) не брать больше ответственности чем на тебе есть
Решение принимает доктор. Наши системы только ассистируют ему в этом. Он(а) не должен(на) нам верить больше, чем наши параметры AUC или True Positive / FP Rate говорят.
Но попытаться oversell свою machinie learning систему в такой области - очень плохая идея
Берегите свою кукушечку, господа машин-лернеры и датасайнтисты, работающие с реальными данными и чьи результаты немедленно идут в клинику после валидации и сертификации

Want to detect cancer early and efficiently? Our new paper shows how to empower pathologists with AI to streamline the detection of a precursor of oesophageal cancer without using endoscopy. 1/11 https://t.co/aGZDc05OGG
forgot to recommend to follow! twitter.com/markowetzlab/s…
Суббота
Под впечатлением от увиденного в городе - немного вакцинного дата сайнса
Соотношение серьёзных рисков от вакцинации Ox/Az и риски оказаться в реанимации при разных уровнях заражения, по данным Британии, на 16 недель
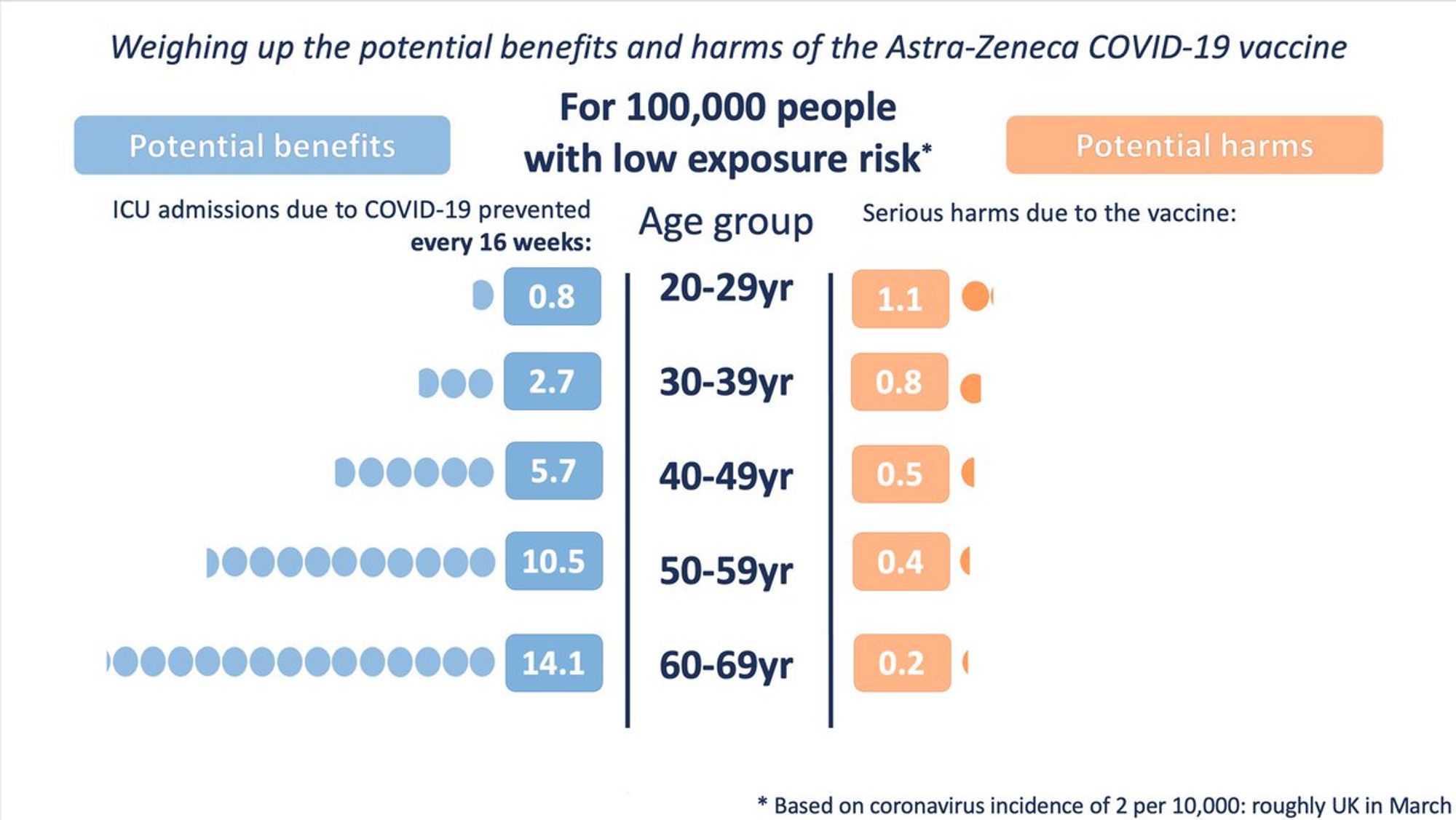
Я думаю все знают, но вдруг не все - тем кто заинтересован в статистическом моделировании - нужно региться на stats.stackexchange.com
Я оттуда узнал кажется больше, чем из многих специализированных курсов
Задаешь тупые вопросы - получаешь умные ответы
Тред про треды
Из-за того что в середине моей вахты был мой отъезд в Россию (и соответственно на работе потребовалось доделать вообще всё), многие объяснения скомкались
Если вы что-то не понимаете в этих тредах - это нормально, я их тоже не понимаю во многих местах
Геномные риски!
Варианты бывают редкие в популяции и частые
Частые варианты редко вносят большой вклад в какие-то важные признаки по отдельности (такие как здоровье), все что вызывает болезнь из-за одного варианта - редкое
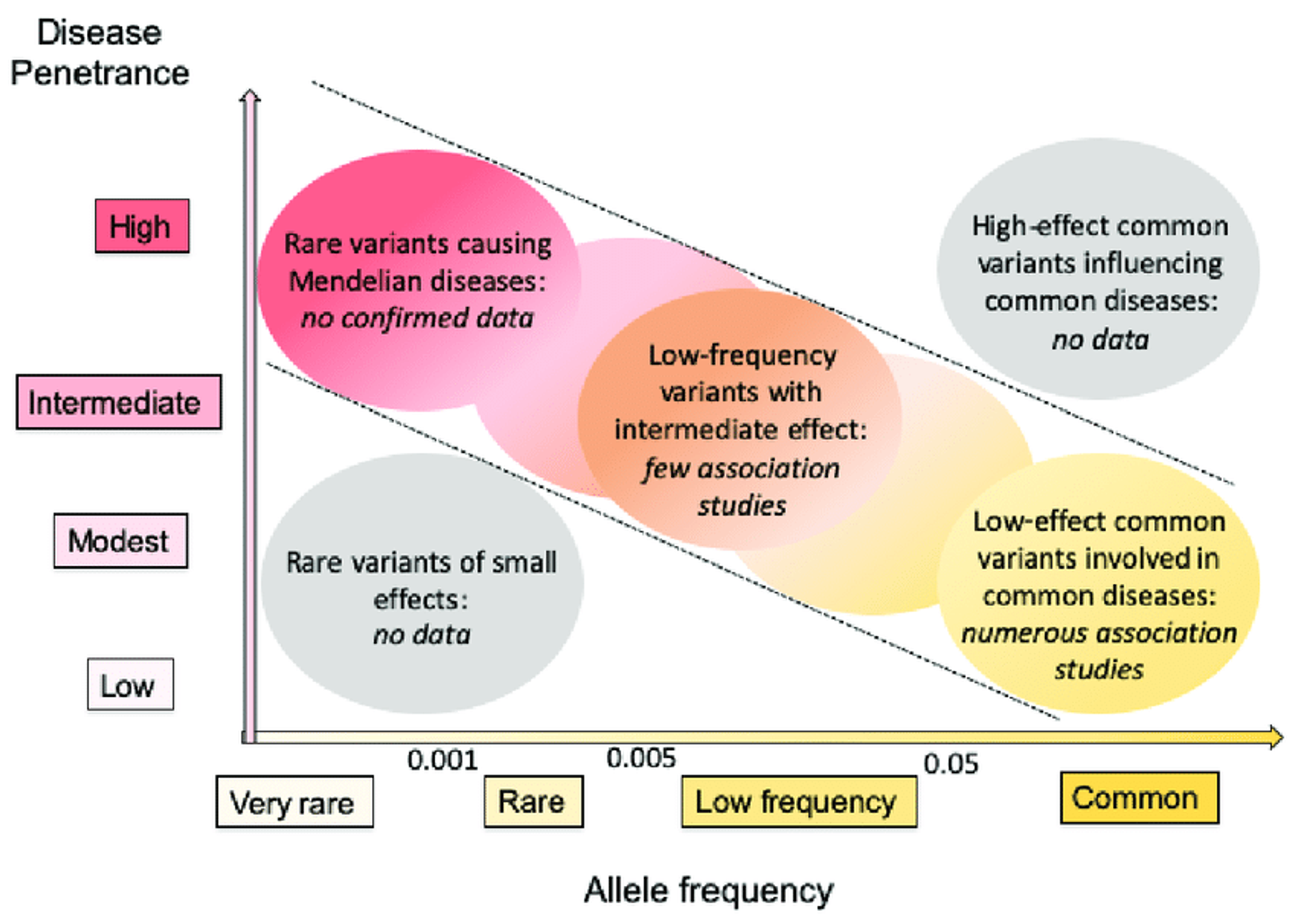
Задачку которую типично надо решать - найти ассоциации между вариантами и признаками (такие как болезни)
Применяется обычно классический позитив-негатив (кейс-контроль) подход, но в последнее время сильно выросло использование Unlabelled learning
Вот оказывается ЖБ сделали мануал по этому делу
habr.com/ru/company/Jet…
Сильно помогает оно потому что зачастую мы не можем точно сказать болеет человек уже или нет, все признаки налицо, он в датасете есть - но диагноз еще не получил
В редких вариантах нужно их как-то суммировать для поиска ассоциаций, скажем, рассматривать варианты из одного гена в совокупности, строить модель и узнавать, повышена ли частота каких-то особых вариантов в кейсах по сравнению с контролями. Это называется
Rare Variant Association Study (RVAS). Там много зависит от модели, потому что многие варианты никакого влияния на функцию продукта из этого гена не оказывают. Надо аккуратно положить всевозможные функции в регрессию, взять правильный линк, отфильтровать данные
Частые варианты редко оказывают большое влияние на какой-то важный признак, они работают в совокупности (генетический бэкграунд). Ищут частые варианты с чем-то ассоциированные при помощи Genome-wide association studies (GWAS)
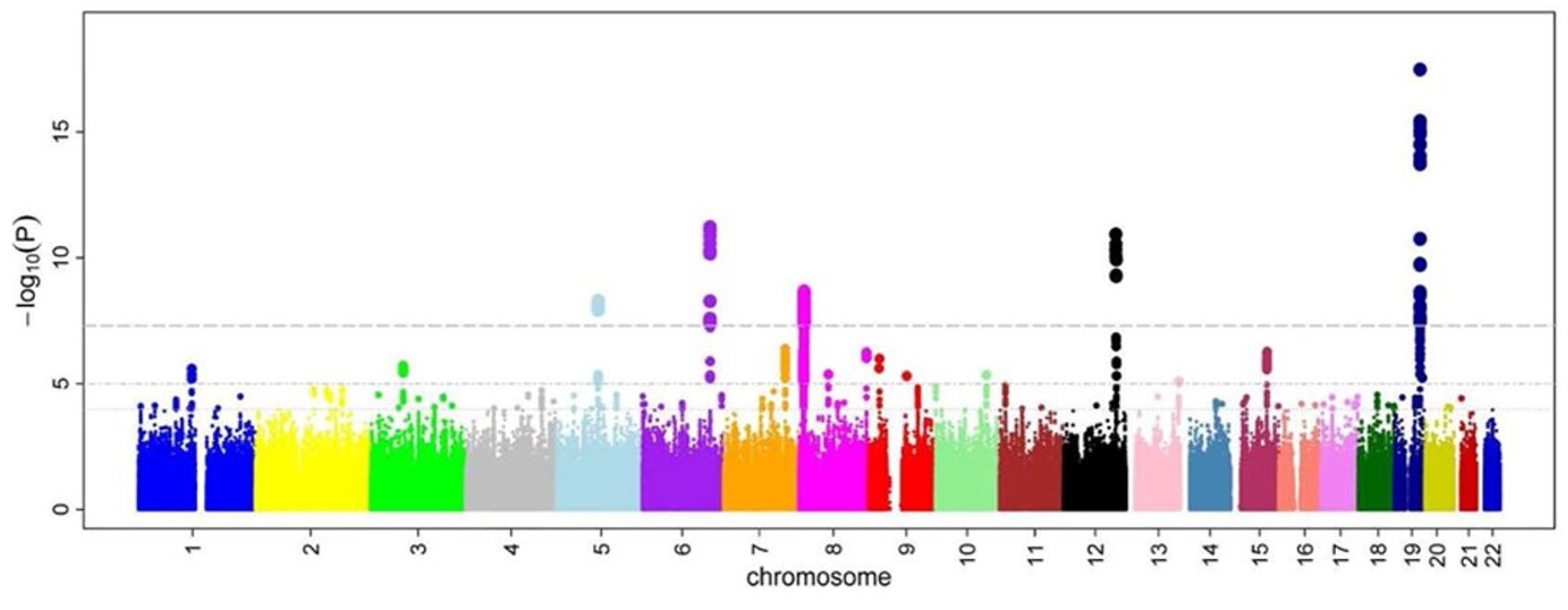
Данные GWAS можно положить в регрессию и найти риск-скор (или если по грамотному - просто риск) таких заболеваний как диабет 2 типа, болезнь коронарной артерии, рак груди или простаты и тд
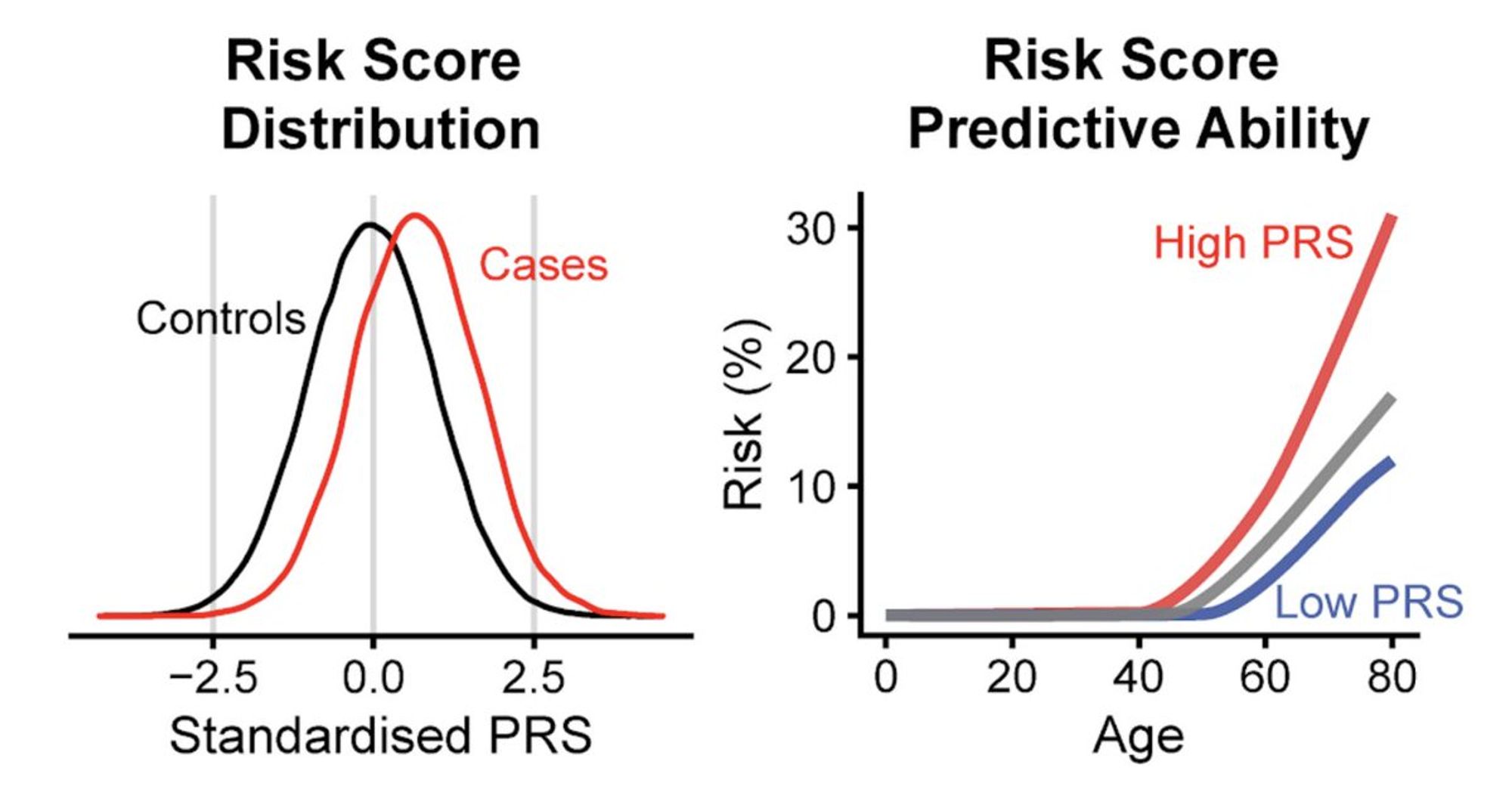
Итого имеем: 100% точно наступающие тяжелые болезни определяются редкими и сверх-редкими вариантами (зачастую возникающими de novo - то есть их нет у родителей заболевшего), а то что возникает в следствие генетического бэкграунда - обычно не определяет жизнь на 100%
Даже если у кого-то высокий генетический бэкграунд риска чего-то - часто можно модифицировать образ жизни (бросить курить, пить, того-сего делать, и вообще стареть) - и избежать заболевания либо его контролировать
Пока что ввиду того что нам приходится смотреть на весь геном (это миллионы вариантов) мы используем простые линейные стат модели с кучей ковариатов, но машин лёрнеры уже трогают носком мокасин зыбкую почву геномных рисков и несут продвинутый ML в область
Я нашел аворитетную толстовку в гараже
Всему что я тут говорю можно верить
Я биг дата мастер
Во всяком случае у меня толстовка

Справа человек с телескопом а не то что вы подумали
Воскресенье
Сегодня мой последний день и вы можете оставлять запросы, что еще рассказать!
У меня по плану пара ленивых тредов о том, каково состояние области в данный момент, и какой дата сайнс хотят врачи (которые и заказывают музыку)
Врачи и то, какой дата сайнс им нужен
Медицина до сих пор это смесь науки и искусства, дата сайнс решения помогают врачу, но ни одно из них не может заменить опыта, интуиции врача и ни одна модель не может включить всевозможные важные предикторы
Врачи и есть ML decision systems
Множество классификаторов, которые дата сайнтисты и статистики разработали, даже обсуждаются на мед конференциях в виде АХАХА СМОТРИТЕ Я УВЕЛИЧИВАЮ ВЕС ЧЕЛОВЕКУ ЗА 200 КГ И НЕ МЕНЯЮ ДРУГИХ ПАРАМЕТРОВ И РИСК УВЕЛИЧИВАЕТСЯ ТОЛЬКО НА 1%
В профессиональном коммьюнити почему-то преобладает мнение, что глупые врачи смотрят в табличку с двумя рядами "ЧЕЛОВЕК ПОСИНЕЛ: СПАСАЙ ЕГО", "ЧЕЛОВЕК НЕ ПОСИНЕЛ: БУДЕТ ЖИТЬ" и принимает решение по табличке, а мы, датасайнтисты с мощными лапищами, ща все пофиксим
Это не совсем так. Я был раз в десять в ситуации когда врач мне писал "я набросал какой-то код, можешь как эксперт посмотреть", я открываю код и - puta madre - там glm-net с умно подобранными параметрами, подбор лямб по кросс-валидации, фичи трансформированны и всё
написано красивым кодом. Конечно, были и обратные примеры, когда мне говорили "давайте уберем этот ваш моделлинг с взаимодействием между предикторами и умными фичами, давайте дихотомизируем результат и будем тестировать univariate значимость"
В таких ситуациях "ты начальник я дурак", приходится подчиняться тому, как хотят доктора (потому что в клиническом журнале в целом будет смотреться странно и непонятно статья со сколь-нибудь сложными стат моделями).
Но это не стопроцентное правило и
нужно быть готовым что врач (причем не только врач-исследователь, но бывает и практикующий врач) всё поймет в вашем методе и разнесет его в деталях. Высокомерие "ну что эти врачи понимают" рано или поздно накажет дата сайнтиста =)
Сейчас медицина действительно трансформируется.
Раньше врачу было критически важным умение посчитать предсказательную модель на листочке (по табличке скажем)
Сейчас компьютеры НАКОНЕЦ-ТО пришли в медицину и уже можно делать калькуляторы рисков без необходимости крайней простоты
Однако требования по интерпретации всё еще есть + в любой мало-мальски сложной модели нужно тренировать их как в условиях "все предикторы доступны" так и "у нас только половина входных данных, остальную половину мы получить не можем"
Резюме: 1) врачи умные и часот шарят в теме, 2) чрезмерно упрощать модель уже не нужно, 3) нужно считать missing data для реальных пациентов нормой и тренировать модель соответственно, 4) включить все предикторы все равно не получится и решение все равно остается за врачом
эта музыка будет вечной =)
какая-то специальная газета рак-диссидентов, 80е годы, репринт я сфоткал в Лондоне, забыл как музей называется, возле Империал Колледжа и Велком Траст фонд
забавное чтение для знающих статистику и понимающих почему так!

последний обещанный тред - где мы сейчас
сложные заболевания - модели, учитывающие факторы жизни + клинические анализы + генетический бэкграунд (редкие сильные и распространенные в популяции слабые варианты) уже начали появляться - осталось только понять, что с ними делать, что там каузальное, а что ассоциированное
как менять клинические рекомендации для людей с повышенными рисками "сложных" заболеваний типа диабета 2го типа - это вопрос ближайшего десятилетия. конечно, соревнования моделей по предсказанию продолжаются, но уже выжимают +0.01AUC дай бог
редкие заболевания - дата сайнс нужен для нахождения всех генов, ответственных за эти редкие и суровые заболевания, несколько тысяч уже открыто, но мы решаем всего 25-50% от больных с редкими врожденными заболеваниями
тому много причин и в частности - то что мы не нашли все гены приводящие к этим заболеваниям (ML + сложный анализ ассоциаций) и то что мы не можем интерпретировать многие варианты в уже известных генах (опять же ML но нужно смотреть на структуру белка явно, 3D моделирование)
рак и подбор персональных таргетных терапий - пока что рандомизированные клинические испытания (аналог AB тестов в медицине) показали что таргетная терапия не дает очень большого прироста в общей выживаемости,
то есть нам нужны новые стратегии по подбору терапий, новые клинические стратегии (скажем, не пытаться лечить таргетно только не ответившие на терапию или рецидивирующие опухоли, а таргетно смотреть весь-весь рак), и конечно только дата сайнс в этом поможет
How surgical skin markings faked out a deep learning #AI neural net-- a commercially approved product for algorithm-aided melanoma diagnosis. Highly instructive. Machines can be dumb. jamanetwork.com/journals/jamad… @JAMADerm by @UniHeidelberg https://t.co/KbSFlc8Ggd
отдельная тема анализ изображений, всякие гистологии, снимки лёгких, МРТ сканы, фото меланом - здесь ML уже показал свою эффективность но случаются досадные казусы типа вот этого
twitter.com/erictopol/stat…
Я конечно затронул только то, чего касался я сам - есть еще куча областей биомедицины, где я ничего не знаю, и где тоже пригодится дата сайнс =)
Спасибо за то что были со мной эту неделю, мне с вами очень понравилось =)
Надеюсь я улучшил сепарабельность классов - тех, кому нравится биомедицина, я подвинул чуть ближе, и оттолкнул чуть дальше тех, у кого другие интересы
@dsunderhood @tiulpin @crazyfrogspb и тут на замену выбегаю я! пас на тренера, пас на тренера! гол!
Мне очень понравились вопросы - видно что многим было прям интересно как все работает, я надеюсь, у вас сохранится этот интерес и дальше =)
Я не то чтобы готовился к этой неделе и всё началось как шутка - спасибо Виктору который вытащил меня "на сцену"
twitter.com/not_a_reptiloi…
Я решил по быстрому пробежаться по зависимости политических предпочтений (правые/левые) от генома Ооо это горячая и противоречивая тема и видимо моё резюме - я не верю многому, но ассоциативная связь кажется есть
Мои треды: типы данных в геномном дата сайнс
twitter.com/dsunderhood/st…
Как я перешел в эту область
twitter.com/dsunderhood/st…
Генетика и политические предпочтения
twitter.com/dsunderhood/st…
краткий тред до совещания интересные курсы по ML из Тюбингена
Стартап по выбору эмбрионов по генетическому бэкграунду
twitter.com/dsunderhood/st…
Вычислительные мощности и организация большого проекта
twitter.com/dsunderhood/st…
Курсы по ML из Тюбингена
twitter.com/dsunderhood/st…
По быстрому накидаю мыслей, что делать если хочешь перейти в биомедицинский DS Первое - нужно понять какая область биомедицины интересна. Люди с абстрактными идеями "хочу излечить человечество от рака" здесь не задерживаются. Хотя приходят и из гуглов.
Рекомендации по твиттер аккаунтам
twitter.com/dsunderhood/st…
Мои хобби
twitter.com/dsunderhood/st…
Что делать если хочешь перейти в биомед дата сайнс
twitter.com/dsunderhood/st…
Следующее большое исследование - PanCancer Analysis of Whole Genomes 2.7K пар опухоль-здоровая ткань, только геномика, только полный геном Мои слайды тут docs.google.com/presentation/d… Портал с данными dcc.icgc.org/pcawg
Проект 1000 геномов
twitter.com/dsunderhood/st…
PanCancer Atlas
twitter.com/dsunderhood/st…
PanCancer Analysis of Whole Genomes
twitter.com/dsunderhood/st…
последний обещанный тред - где мы сейчас
Как не принимать происходящее в больнице близко к сердцу
twitter.com/dsunderhood/st…
Геномные риски
twitter.com/dsunderhood/st…
Какой дата сайнс нужен врачам
twitter.com/dsunderhood/st…
Текущее состояние моей области
twitter.com/dsunderhood/st…
Enjoy your weekend 'n see you later!