Архив недели @generall931
Понедельник
Привет, меня зовут Андрей Васнецов (@generall931) и на этой неделе андерхуд веду я.
Я lead ML Engineer, работаю, в основном, с NLP, последние полгода живу в Берлине.
Свой твиттер я давно забросил, но зато веду телеграм-канал про нейросети (нет, это не обзоры статей про берт!).
Заходите, подписывайтесь: ttttt.me/neural_network… часто отвлекать точно не будет.
Примерный план на эту неделю такой:
ПНД: Расскажу про себя
ВТР: Про релокейт, карьеру вот это все
СРД: Буду набрасывать на каггл и академию
ЧТВ-ПТН: Про ML в индустрии: тулзы, лайфхаки и т.п.
СБТ-ВСК: Про свои пет-прожекты
В отличие от предыдущих ведущих, я буду адвокатом от индустрии.
В ML я пришел из низкоуровневой разработки на C++ через бэкенд-разработку на java.
Успел поработать в крупных корпорациях, немного пофрилансить, и вот теперь работаю в стартапе.
Начал свою оплачиваемую разработческую деятельность я стажером в mail.ru group, в отделе поиска.
Занимался низкоуровневыми оптимизациями поискового движка, параллельно писал шедулеры для внутренних задач - Airflow тогда еще не было.
В то время я еще учился в универе, только начинал ковыряться в ML и считал, что обязательно нужно стать минимум PhD - ведь только там будет весь cutting edge и сильный AI. Работа, соответственно, уходила на второй план.
Как следствие, не могу похвастаться какими-то особыми достижениями на той работе, да и не думаю, что тимлид был сильно доволен моей вовлеченностью в проект.
Так, получив скилл отладки в gdb, использования bash и осознав важность тестирования кода, я решил перейти поближе к "науке".
Перешел маленький в калифорнийский стартап, где работал мой научрук и еще пара его студентов.
Стартап хотел заниматься матчингом людей, интересных друг другу.
Например выбирать на конференциях людей из одного города\школы\универа и рекомендовать друг-другу.
Или организовывать студенческие группы по схожим интересам.
К сожалению интересная задумка, сулившая много возможных ML-применений, натолкнулась на отсутствие каких-либо данных.
Поэтому написав базовые эвристики, команда из 3-х студентов занималась full-stack разработкой, которую пытался продавать американский начальник.
Со временем и под давлением запроса от маркетинговых компаний в стартапе начали появляться идеи, напоминающие скорее астрологию, чем data science.
Мы начали сопоставлять цвета фоток из инстаграмма с покупательским поведением, влияние любимых жанров музыки и другие странные вещи.
В какой-то момент мы даже организовали настоящий научный эксперимент на людях!
Чтобы проверить эффективность наших алгоритмов мы просили студентов оценить насколько точное описание мы даем их покупательским привычкам.
Для исключения эффекта Барнума у нас даже была контрольная группа, которой мы показывали случайное описание.
Полученный результат не опроверг нулевую гипотезу, но начальник решил, что это не повод для изменения подхода.
Такое состояние дел демотивировало команду, и в результате из стартапа разбежались почти все разработчики.
Тогда и я решил попробовать себя на фрилансе. К тому же в то время я только дописывал свой диплом и искать полноценную работу было сложно.
Дипломом, к слову, я тогда очень гордился. Там была модификация одного из ML-алгоритмов, расширяющая его применимость, бенчмарки на разных датасетах.
Была статья, оформленная по всем канонам arXiv org. Он, конечно, оказался полностью неприменимо на практике, но об этом позже
Благо, за счет ежедневных интерконтинентальных митингов удалось прокачать английский на достаточный для технического разговора уровень.
Что позволило искать заказчиков на upwork-е. Заказы были абсолютно разные - от помощи с подготовкой статьи, до бэкенд разработки.
Но один из заказов был особенно интересный. Нужно было с нуля написать сервис, который бы мог делать умный автокомплит для текстов вакансий на английском и голландском языках. В этом проекте было все - и веб-сервис, который должен быстро отвечать на запросы, и рисёрч, и деплой.
Успешное завершение этого проекта принесло мне, пожалуй, наибольшее на тот момент удовлетворение от своей работы.
Это был не просто очередной таск в jira, а полноценный самостоятельный продукт.
К тому времени я уже защитил диплом и начал искать фулл-тайм работу. Искал я ее в ODS.ai в #_jobs.
Удивительно, как ODS удалось создать, по сути профсоюз, который, например, запросто продавливает требование открытой публикации вилки ЗП даже крупными компаниями
Спустя несколько собеседований устроился в один Желтый Банк мидл ДС-ом, или как это называется у меня в трудовой - "старший разработчик-аналитик".
За почти 2 года работы там было много интересных проектов с #NLP и не только.
За это время я начал вести канал, успешно поучаствовал в хакатоне, параллельно вписывался в стартапы, стал техлидом и даже, в какой-то момент, одновременно менеджил две ML-команды. Подробнее об этом завтра.
Затем летом 2к19-го я сходил выразить гражданскую позицию на Трубной площади, провел 2 ночи в камере ОВД, после чего решил, что пора заводить трактор.
Через 2 месяца трактор успешно завелся, о чем я тоже расскажу завтра подробнее.
С тех пор я работаю в @moberries, ставлю таски, делаю код-ревью, обучаю нейросети, пинаю metric learning,
заворачиваю все в сервисы и деплою в кубернетис. На этом, пожалуй, все на сегодня, пишите ваши вопросы.
Вторник
Привет, на сегодня у меня запланированы две частично связанные темы - про релокейт и про карьеру.
Точкой пересечения тут будут собеседования, на которых мне приходилось быть по обе стороны баррикад. Иногда в один и тот же день.
Начну с релокейта.
Задумываться о переезде в страну первого мира я начал намного раньше, но от активных действий меня удерживала лень и нерешительность.
Усилий воли, хватало, максимум, на нерегулярные занятия английским, чтобы не растерять устного общения.
И если после описанных ранее событий нерешительность и улетучилась, то как побеждать лень на протяжении довольно продолжительного поиска работы - оставалось для меня не решенной проблемой.
Пока LinkedIn не принес неожиданное решение - личный менеджер по релокейту!
Релокейт менеджер - это такой чувак, который делает за тебя всю скучную работу:
-ищет вакансии, подходящие под твое резюме
-заполняет формы (видели какие они огромные у гугла и амазона?!)
-Назначает созвоны, ведет начальные переговоры
В идеале остается невидимым для компании
Он финансово заинтересован устроить тебя на работу твоей мечты:
-Если тебе не понравится вакансия - он ничего не получит
-Если тебя уволят раньше первого года - он получит меньше
-Его вознаграждение зависит от твоей ЗП
Плюс, договоренности помогают не забить из-за лени
Да, я тоже находил в интернете много контор, которые обещабют работу в FAANG.
Но, как мне показалось, интересны они могут быть, разве что, джунам.
Во-первых, заламывают конские проценты. Во-вторых, открыто пишут, что для успешного устройства нужно прорешать 50+ задач с leetcode
Кстати, если вы выбираете страну для переезда, то сравнивать варианты удобно в numbeo.com/cost-of-living/. От себя могу подтвердить, что все цифры про Берлин достаточно близко совпадают в реальностью
За время поиска работы мой менеджер разослал мое резюме в почти сотню разных компаний,
американские компании часто даже не утруждали себя отказом, все-таки в последнее время переехать туда стало намного сложнее.
Среди европейских городов IT движуха есть в Лондоне и Берлине.
Однако в Лондоне предложение по деньгам намного более скромное, если брать в расчет стоимость жизни.
Поэтому основное количество моих собесов проходили именно в Берлин.
Практически все собеседования, продвинувшиеся дальше скринигово созвона с HR, включали домашнее задание и технический собес по его результатам.
Домашнее задание, кстати, может быть полезно не только работодателю, но и соикателю.
По нему можно понять какие задачи на самом деле вам достанутся на работе.
Там например в одном из задании было требование оформить результаты обучения модели в виде power point презентации.
Продолжать собеседования на эту позицию, я, конечно, не стал.
Как я готовился к собеседованиям? Никак.
Серьезно, если вам нужно готовиться, не значит ли это, что интервьюер спрашивает что-то не то.
Имеют ли такие интервью что-то общее с реальными задачами? Конечно нет.
В результате это привело к нескольким заваленным собеседованиям, но хотите ли вы работать в компании с настолько сломанным отбором?
Если вы в свой ежедневной работе не занимаетесь выводом формулы для лог-регрессии, то не стоит и на собеседовании ее спрашивать.
Компанией с самым сломанным отбором, без сомнений, является Амазон.
В ней все с этим плохо настолько, что рекрутеры сами вам высылают ссылки на материалы для подготовки и в предварительном созвоне рассказывают как именно лучше угождать своим техническим коллегам.
@dsunderhood @moberries #deep_metric_learning 🤙 тоже им занимаюсь
В NLP или CV? Расскажи как успехи twitter.com/artsiom_s/stat…
Среда
Привет, сегодня еще неменого продолжу вчерашнюю тему с карьерой, а потом перейду к набросам.
Расскажу как стал техлидом и какие перки это дает.
Глобально, чтобы вам доверили управлять проектом, должны сложиться 2 фактора:
должен быть проект, который кому-то нужен, и вы должны быть тем, кто лучше всех в этом конкретном проекте разбирается.
Тут важно заметить, что не самым умным вообще, а только к конкретном проекте.
Наш отдел был функциональным юнитом, к нам приходили "заказчики" из других отделов с ML-like задачами, а мы их решали.
Такая организация была удобна для рисёрча - все ДСы сидели рядом, обменивались опытом, могли месяц пробовать новую идею из понравившейся статьи.
Однако были и проблемы, полученные решения, в лучшем случае, годами допинывались в прод силами самих ДС-ов, в худшем - пропадали у заказчика без какого-либо фидбека.
Периодически возникало желание конвертировать такую задачу в проект и отвечать, в том числе, и за его эксплуатацию
Получить такой качественный переход удалось не сразу, понадобилось несколько заброшенных задач, прежде чем первый проект начал жить более-менее автономно.
Лучший совет, который я могу тут дать - старайтесь представить вашу работу как можно более наглядно.
Прошло огромное число совещаний, где я показывал какой выходит ROC-AUC, как замечательно выглядит схема деплоя. Все эти совещания давали ничтожный импакт.
Но стоило сделать самую простую веб-демку, в которую может потыкать кажный менеджер, как сразу появлялась заинтересованность
Понимаю, что совет не универсален, сложно сделать демку для моделирования аплифта. Однако если ваша задача связана с NLP или CV, у вас есть пространство для маневров.
Для этого придется овладеть азами веб-разработки, но оно однозначно того стоит.
После того, как ваш проект одобрят, вам нужно будет собирать под него команду.
Тут все сильно зависит от проекта, но можно сказать точно - если вы хотите делать полноценный продукт, не рассматривайте участие в каггле и PhD как преимущества.
В случае же, если вы собеседуете начинающих дата саентистов, то участие в каггле, при отсутсвии минимального опыта разработки, я бы считал даже негативным фактором.
Не спешите отписывать, дальше я попытаюсь мотивировать такое непопулярное мнение.
В RL тусовке, есть замечательный термин - reward hacking. Он описывает явление, чем-то схожее с переобучением.
Приводит оно, например, к тому, что роботы-уборщики надевают себе на голову ведро, чтоб не видеть мусора.
Такое явление не является побочным эффектом какого-то конкретного алгоритма.
Появляется, если пытаться заменить реальную метрику (чистый пол) на вычислительно простое прокси (камера не видит грязь).
Короче - когда метрика становится целью, она перестает быть хорошей метрикой
Любая состязательная система, так или иначе сталкивается с этим явлением. И в попытке сделать цель удобной и прозрачной, каггл дисцилировал ее до состояния лидерборда, сортирующего всех учасников от лучших к худшим.
Тем самым создав идеальную среду для ревад-хакинга.
Отсюда регулярные скандали с читерством - @ppleskov, семинары по эксплуатации дата-ликов - t.me/mltrainings/, мемы про more layers.
Печально, что проклятье лидербордов просачивается и в акадению. Причем в академии это могут быть не лидерборды могут принимать изощренные формы.
Тут это не только лидерборды в чистом виде, но и KPI на количество статей, разные индексы цитируемости и тому подобное.
А приводит это к ужасному write-only коду, который, под прикрытием бренда известного универа, толкается, например, для прогнозов по пандемии.
github.com/mrc-ide/covid-… lockdownsceptics.org/code-review-of…
Reading the OpenAI GPT-3 paper. Impressive performance on many few-shot language tasks. The cost to train this 175 billion parameter language model appears to be staggering: Nearly $12 million dollars in compute based on public cloud GPU/TPU cost models (200x the price of GPT-2) https://t.co/5ztr4cMm3L
Или к тому, что некоммерческая компания сжигает $10M+ на обучение модели, которую невозможно использовать, и не видит в этом ничего зазорного.
twitter.com/eturner303/sta…
Примечательно, что в IT это случается не впервые. В спортивном программировании тоже решают задачи, вроде бы, близкие к реальным проблемам. Однако использование в продакшене кода, порождаемого спортсменами, занятие из разряда программирования экстремального.
Четверг
Привет, сегодня и завтра буду рассказывать какие частые ошибки встречаются у дата саентистов, когда дело доходит до прода.
Также поговорим о тулзах, которые существенно облегчают жизнь, и которые полезно иметь ввиду.
Основано на вымышленных событиях, все совпадения случайны
Первое, с чем сталкивается начинающий дата саентист перед внедрением модели в продакшн - это обеспечение вопроизводимости результата.
Тут речь даже не всегда идет о том, чтобы через год модель могла нормально обучиться. Нужна возможность банально запустить проект на сервере.
Тут может подстерегать сразу несколько проблем. Во-первых, DS проекты часто начинают разрабатывать в anaconda, в которой из коробки установлено несколько ГБ библиотек.
Если вы делаете регулярные обновления, то прогонять такой объем лищней нагрузки через CI/CD будет очень больно.
Поэтому разработчики стараются не тащить в прод ничего лишнего. Из этой ситуации возникает проблема, что окружение дата саентиста может отличаться от откружения продакшена,
что может привести к мучительно отладке прямо на боевой системе.
@dsunderhood В CV. Вот недавняя статья с CVPR github.com/CompVis/metric… #deep_metric_learning
Избежать этого лекго - не используйте anaconda и всегда трекайте свои зависимости.
Звучит банально, но за негативным примером ходить далеко не нужно.
twitter.com/artsiom_s/stat…
Тут мы видим репозиторий, в котором авторы не указали requirements.txt и теперь желающие воспроизвети их результат должны выискивать все нужные зависимости в коде.
Вообще этот репозиторий изобилует типичными недоработками DS, наверняка мы к нему еще вернемся сегодня
Пятница
Продолжаем вчерашнюю тему!
Помимо зависимостей, большую проблему досталяют сами файлы с данными и моделями. Возникает вопрос - как хранить и доставлять модели до продакшена?
И самым худшим решением тут будет положить их прямо рядом с кодом в git.
Во-первых, git изначально не предназначен для хранения бинарных данных, diff считается не эффективно, операции происходят медленно. Во-вторых, вы будете страдать каждый раз, когда нужно будет склонировать репозиторий, git потащит за собой всю историю изменений.
Даже если вы попробуете удалить файл из репозитория, то обнаружите, что это не решило свою проблему. Git все равно все запомнит, на случай, если вы попытаетесь откатиться. Тут вам могут помочь только тулзы вроде этой rtyley.github.io/bfg-repo-clean…
Правильным решением тут будет хранение моделей в специализированных хранилищах, например S3. Код, при этом, должен содержать информацию о актуальной версии файла и откуда его можно достать.
Из коробки такую функциональность можно получить используя dvc.org, который сделает все красиво и удобно. DVC также имеет функции построения дата-пайплайнов, но лично я считаю её избыточной. Есть тулзы, которые для пайплайнов подойдут лучше.
Кстати, если вы используете docker для деплоя, то dvc pull удобно включить прямо в Dockerfile, тогда собранные образы не будут зависеть от доступов к хранилищам и всегда будут готовы к работе. Это полезно, если, например, понадобится срочно откатиться на старую версию.
Еще одна типичная недоработка в DS - отсутствие тестов. Может казаться, что раз модель дает хороший результат на кросс-валидации, то все и так работает правильно. Однако тесты нужны не только для того, чтобы проверить работоспособность в данный момент.
Когда нужно вносить изменения, связанные с каким-то фрагментом вашего кода, хорошо написанные unit-тесты могут служить своего рода документаций для функций и классов. И иногда бывает гораздо проще разбираться в коде, зная ожидаемый результат при данные параметрах.
Также, при разработке новых функций, полезно иметь регрессионные тесты, проверяющие, что новые изменения не ломают старого поведения. И при случае помогут обнаружить источник проблемы. Согласитесь, отлаживать модель, в которой внезапно просели метрики - удовольствие ниже среднего
Кстати, в моем блоге есть пост про интересный подход к отладке нейросетей, который я несколько раз применял на практике. Он больше подходит для разработки новых архитектур, чем для unit-тестирования, но, думаю, должно быть интересно comprehension.ml/posts/neural-d…
После написания тестов важно не забывать их запускать. Тут, конечно, можно понадеяться на собственную пунктуальность, но лучшим решением было бы использование CI\CD.
Если вы работаете в компании, где есть другие разработчики, то в каком-то виде CI\CD наверняка уже существует, спросите у них. В минимальной конфигурации вам понадобится автоматический запуск тестов при push-е в определенные ветки.
Если разрабатываете в одиночку, попробуйте настроить github actions или любую другую систему, у которой есть бесплатный лимит и которую не нужно хостить у себя. Очень скоро вы познаете блаженство автоматизации.
Еще один важный способ контроля качества является код-ревью. Если в вашей команде есть тимлид, обычно он и должен его проводить (встречаются, однако, и другие варианты). Мне приходят на ум две основные проблемы, с этим связанные.
Первая - код-ревью проводятся настолько редко, что накопившиеся изменения становятся необозримыми. В этом случаe код-ревью, либо занимает несколько дней, либо, что вероятнее, пропускается.
Понятно, что первое обучение модели несет много проб и ошибок, порождает мертвый код. Отдавать его на ревью не имеет смысла. В этом случае его лучше запланировать после получения первого результата, удовлетворяющего MVP. А далее, каждое изменение ревьють отдельным пул-реквестом
Вторая проблема - это подмена code-ревью на plot-ревью. Plot-ревью возникает, когда старший рисёрчер в вашем отделе удовлетворяется лишь красивыми графиками и хорошими цифрами в f1-метрике.
Дальше, на стадии A/B тестирования (или хуже - после потраченного полугода разработки) обнаруживается, что фичи не надо было брать из месяца, на который делались предсказания.
Успешно пройдя всю подготовку к деплою, DS может внезапно обнаружить, что его сервис отвечает на запросы какое-то неприлично долгое время, хотя из моделей используется только лог-регрессия. Причем в жупайтер-ноутбуке все работало адекватно.
Обычно первое, что я делаю, если ко мне обращаются с такой проблемой - проверяю не используется ли где-то в подготовке фичей pandas. Обычно именно он является причиной самых серьезных тормозов
Нет, я не буду призывать отказываться еще и от него - это отличный инструмент, если знать границы его применимости. И границы эти заканчиваются там, где заканчивается обработка данных батчами.
Происходит это потому, что операции, незаметные на фоне больших данных, привносят гигантский оверхед при единичных запросах. Бывали случаи, когда замена pandas на обычные словари увеличивала скорость ответа сервера в сотню раз!
Суббота
@dsunderhood @Mrchair2170 А что на счёт kubeflow?
Самому использовать не доводилось, но судя по докам - такую штуку имеет смысл брать, если работаете в большой команде и нужно шарить ресурсы. Не могу сходу придумать ни одной задачи, в которой индивидуальный ds мог использовать такой комбайн эффективно. twitter.com/algorodnitskiy…
Привет! Последней темой моей недели будут пет-прожекты. Расскажу о том, что пробовал делать я и какие уроки для себя извлек.
Весь материал материал есть также в моем канале, но тут я попытаюсь описать более доступно.
Меня давно заинтересовала тема one-shot learning в NLP, начиная еще со знаменитого поста Рудера ruder.io/requests-for-r…
В двух словах идею One-shot learning можно описать так: знание нескольких принципов компенсирует незнание многих фактов.
Формально же задача One-shot learning заключается в том, чтобы решить задачу классификации,
когда на каждый класс дано всего несколько обучающих примеров. Причем новые классы могут даже не встречаться в обучающей выборке.
В Computer Vision типичной задачей one-shot learning является задача идентификации лиц, а также имеется своего рода "MNIST" для этой задачи - датасет Omniglot.
Заинтересовавшись этой проблемой я старался найти ей практическое воплощение.
Для этого требовался датасет, который бы представлял собой не узкоспециализированные данные, а универсальные знания о мире.
Такие знания, которые содержатся в языковых моделях и word2vec векторах
Вообще, наличие подходящего датасета - это 80% успешного дела.
И самое удачное - это найти self-supervised датасет, т.е. датасет, который сам себе является разметкой.
В NLP - это языковые модели, в CV - целая куча всего: colorization, slow-mo, super resolution, depth maps и т.п.
Воскресенье
При этом со времен универа я работал с над задачей Named Entity Linking, возникла идея объединить эти две темы. Так я начал экспериментировать с матчингом сущностей, используя датасет ссылок на википедию.
Датасет создавался следующим образом: давайте найдем все преложения в интернете, которые которые содержали бы гиперссылки на какую-нибудь статью вики.
Тогда можно сказать, что текст ссылки - это Named Entity, которая linked на соответствующую статью.
Нашел github.com/NTMC-Community… и начал экспериментировать.
К слову, в то время переиспользовать MatchingZoo было совершенно неудобно, поэтому я переписывал интересные модели на AllenNLP.
Идея проекта заключалась в том, чтобы хранить информацию о интересующих нас сущностях в виде их упоминаний,
быстро добавлять или удалять, а алгоритм при классификации просто находил бы самое похожее упоминание.
Алгоритм работал и даже выдавал неплохой скор, но огромное количество редких сущностей, создавали много шума и портили результат.
Так, например, для <Парижа> система выдавала около 50 разных кандидатов и, соответственно, 500 упоминаний для проверки.
Это обстоятельство делало резолв сущностей неприлично долгим, и я начал искать другие пути.
Тогда мне попалась статья, описываются интересный подход "запоминанию" редких слов в NMT. aclweb.org/anthology/D17-…
Подход заключался в том, что нейросеть "выбирает" какой источник использовать для перевода очередного слова - обычное состояние seq2seq или вектор, сохраненный во внешней памяти.
Память здесь отвечала за перевод редких слов и могла быть модифицирована без дообучения.
Эта статья натолкнула меня на идею сделать своего рода агрегированное представление для сущностей,
которое можно было бы использовать для резолва, и которые могли бы независимо обновляться при поступлении новой информации.
Представление я собирался строить на основе упоминаний, потому модель должна была уметь принимать на вход сразу несколько текстов с упоминаниями одной сущности.
К этому моменту мне уже хотелось сделать что-то, что можно использовать и демонстрировать, а не только наблюдать в виде графиков на тензорборде.
Поэтому я решил сконцентрировать только на одном типе сущностей - на упоминаниях людей.
Чтобы выучивать агрегированное представление нейросети нужно было придумать максимально общую self-supervised задачу,
в качестве такой задачи я выбрал предсказание вики-категорий (типа таких ru.wikipedia.org/wiki/%D0%9A%D0…). За одно представление получилось бы еще и человеко-читаемым
В итоге этих категорий оказалось даже слишком много, поэтому я оставил только ~200 наиболее значимых.
Плюс, конечно, всегда оставалась бы возможность использовать внутренние эмбеддинги сетки для дообучения и добавлять новые категории.
Следующий мой большой pet-прожект, которым я занимаюсь до сих пор - это векторный поиск.
Существует много библиотек типа Annoy или FAISS, которые делают очень быстрый приблизительный поиск по миллиардам векторов.
Исследователи и инженеры борются за наносекунды
Однако в практические задачи иногда требуют не только нахождения ближайшего вектора, но и указание дополнительных критериев отбора.
Это могут быть бизнес-правила или логика работы приложения, не зависящая от близости векторов.
Тут у существующих библиотек возникают проблемы
Попытаться реализовать подобную логику можно с помощью пост-фильтрации, но это подход не масштабируется - рано или поздно из-за фильтра придется перебирать огромное количество лишних векторов.
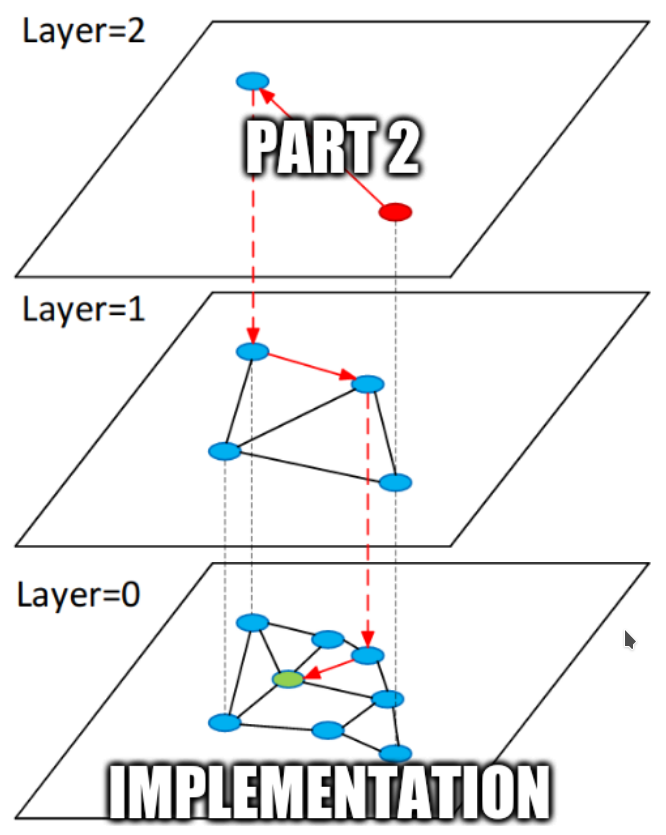
Оказалось, что при некоторых модификациях в алгоритм HNSW такие фильтры вставить можно, и это даже не повредит его производительности!
Описывать эти модификации в твиттере довольно сложно, но можете прочитать про них в моем блоге
В результате получился форк HNSW, в котором можно даже реализовать фильтр по гео-зонам, диапазонам и тэгам.
github.com/generall/cat_h…
Дальнейший план в этом проекте - сделать векторный поиск как сервис, с API, шардированием и репликациями, умным планировщиком запросов и, конечно, фильтрами.
Чтобы сделать этот сервис достаточно быстрым, я даже начал изучать Rust, но это уже история для другого твиттера.
В результате у меня получился mention.vasnetsov.com/#/ у которого есть даже online демка - mention.vasnetsov.com/#/demo,
один показательных примеров работы которого - на картинке

Какое-то время я даже пытался заниматься промоушеном этого проекта, но не получив никакого респонса - забросил.
Все-таки плохой из меня маркетолог. Кстати, если у кого-то есть мысли про использование такой штуки - пишите, всегда рад коллаборациям.
Моя неделя подходит к концу, в этот раз на табуретке стоял Андрей Васнецов @generall931. Если было интересно, подпишитесь на мой телеграм-канал ttttt.me/neural_network… или читайте блог blog.vasnetsov.com Спасибо за внимание! Недельный мета-тред:
В отличие от предыдущих ведущих, я буду адвокатом от индустрии. В ML я пришел из низкоуровневой разработки на C++ через бэкенд-разработку на java. Успел поработать в крупных корпорациях, немного пофрилансить, и вот теперь работаю в стартапе.
Про карьеру twitter.com/dsunderhood/st…
Привет, на сегодня у меня запланированы две частично связанные темы - про релокейт и про карьеру. Точкой пересечения тут будут собеседования, на которых мне приходилось быть по обе стороны баррикад. Иногда в один и тот же день.
Про релокейт и собесы twitter.com/dsunderhood/st…
Привет, сегодня еще неменого продолжу вчерашнюю тему с карьерой, а потом перейду к набросам. Расскажу как стал техлидом и какие перки это дает.
Набросы на каггл и академию twitter.com/dsunderhood/st…
Привет, сегодня и завтра буду рассказывать какие частые ошибки встречаются у дата саентистов, когда дело доходит до прода. Также поговорим о тулзах, которые существенно облегчают жизнь, и которые полезно иметь ввиду. Основано на вымышленных событиях, все совпадения случайны
Про типичные ошибки и лайфхаки в индустриальном ML twitter.com/dsunderhood/st…
В результате у меня получился mention.vasnetsov.com/#/ у которого есть даже online демка - mention.vasnetsov.com/#/demo, один показательных примеров работы которого - на картинке https://t.co/oG4ygmIpaI
Про pet-project с классификатором людей twitter.com/dsunderhood/st…
Следующий мой большой pet-прожект, которым я занимаюсь до сих пор - это векторный поиск. Существует много библиотек типа Annoy или FAISS, которые делают очень быстрый приблизительный поиск по миллиардам векторов. Исследователи и инженеры борются за наносекунды
Про pet-project с векторным поиском twitter.com/dsunderhood/st…