

Архив недели
Понедельник
всем привет, меня зовут Жека Никитин, я руковожу ML-разработкой в компаниях Цельс и Калуга Астрал, мы занимаемся CV в медицине (и не только)
вообще я должен был твитить в мае, но ничего, будем импровизировать по-королевски
о чём я планирую побазарить (но всё в ваших руках):
- как и зачем я пилил ML-стартап и одновременно делал PhD по Political Science в NYU
- почему я его бросил на четвёртом году и вернулся в Питер
- как пережить рост своей команды с 1 до 20 человек за полтора года и не сломаться
- ML в медицине - верю ли я в него, ужасы медицинских данных, что про нас думают врачи
- ML-разработка - действительно ли она сильно отличается от софтверной или ну такое, как стартовать и скейлить команды
- всякие кул-сторис из жизни нашей команды
- почему я ненавижу удалёнку
но вообще по результатам первого дня жду ваших реплаев и будем красиво эджайлить. может быть, вам история про то как я чуть не спился к хренам в Нью-Йорке, но потом всё-таки выкарабкался, будет интереснее
по традиции расскажу про себя и свой тернистый путь, так сказать, для контекста
первая важная веха моей жизни - это ФТШ, такая физическая школа в Питере. я там учился в 8-11 классах, это один из самых топовых периодов в жизни. 4 года вариться в кругу людей, которые сейчас преподают во всяких принстонах, работают в джетбрейнсах и гуглах - это очень круто
правда, в этом году уже было два педо-скандала о преподах из ФТШ, но это уже совсем другая история... в общем, из параллели нас было двое, кто не пошёл на физику, математику или прогу. вместо этого я оказался на метметодах в экономике в финэке
на самом деле там было норм(кроме коррупции), матбаза была неплохая, в 2011 году я впервые узнал про гребневую регрессию (она же ridge). в этом же году я впервые пошёл наблюдателем на выборы и с этого момента во мне стало крепнуть желание свалить (про это мб отдельный тред потом)
на своей первой работе мне нужно было писать всякие формулы в табличках в экселе, на второй неделе я всё это автоматизировал через VBA-макросы, а потом 3 месяца играл в харстоун. потом меня спалили, но почему-то не уволили, а повысили зп до космических на тот момент 80к
в общем, кое-какие деньги с этой работы накопил, ну и, конечно, мой дед-красава (он физик и на своих идеях намутил бизнес, сейчас, правда, всё умерло) сильно помог мне и я отправился в University of Warwick на годовую магистерскую программу
программа называлась Behavioral & Economic Science. вообще меня лет с 9 интересовало практическое применение математики в разных областях, связанных с человеческим поведением. в итоге я позанимался математикой в экономике, когнитивной психологии и политологии
там было невероятно круто, у меня были потрясающие профессоры, я влюбился в Англию (особенно в их пивас) и в итоге поступил на PhD по экономике в Оксфорд. к сожалению, цикл подачи доков устроен так, что подаёшься ты за год до начала обучения
короче, к лету 2015 я понял, что экономика - это парашная консерваторская и консвервная область, в которой мой интерес к матстат моделированию и крепнущий интерес к соседнему ML никак не применить. в итоге я вернулся на gap year в Россию, но всё ещё твёрдо хотел свалить
вообще ML оказался просто моей мечтой, объединение математики, айтишки и кучи разных реальных доменных областей. в общем, я пошёл в Playrix дата-аналитиком, а параллельно готовил доки к поступлению в разные американские и британские универы
в плейриксе было весело, я пожил в Вологде, подрался с алкашами местными, сам каждый день пил, впервые покрутил ML-модельки на реальных геймерских данных. в общем, есть что вспомнить
тем временем, я поступил в несколько уников, среди них был NYU.устоять парню с Дыбенко перед Нью-Йорком было тяжело. ну и программа обещала быть интересной - Political Science, но я лично пообщался с научруком и он начинал мутить Social Media Lab для изучения политики по соцсетям
в общем, про PhD и жизнь в Нью-Йорке я расскажу в отдельном треде, а то это и так жестокий. прямо перед отъездом ко мне обратился мой товарищ, у него на руках оказался интересный датасет - базовая инфа о людях, таргет (вернули ли микрозайм) и их фотография
long story short, он предложил мне построить модель, которая по лицу человек определяла бы его кредитоспособность. "ты е**нутый?" - подумал я, "давай, давно хотел повозиться с картинками" - сказал я. хайпанули мы в итоге на этой теме красиво, по РБК даже рассказывали
по итогу мы просто стали делать ML-модельки для микрокредитных организаций, никаких лиц там, ясен пень, не было. занимались мы этим 4 года, параллельно с моим PhD (тоже отдельный тред потом, наверное, про стартаперскую жизнь, если интересно)
осенью 2018 года мне позвонил мой товарищ/партнёр по бизнесу и спросил, смогу ли я построить модель по детекции рака на снимках молочной железы. "хз, можно попробовать" - "да неважно, я уже согласился".
в общем, так началась последняя на текущий момент эра в моей жизни - возвращение в Россию, ML в медицине, построение своей ML-команды с нуля, бурный скейл ML-отдела до 20 человек
предыдущий тред получился безумно длинным, но зато по нему теперь можно ориентироваться, о чём я могу порассказывать (например, пьянство и выгорание), так что жду ваших комментов
хватит пока про меня, в этом треде расскажу про Цельс, про сложности с внедрением и разработкой ML-продуктов в медицине и про текущее состояние индустрии в России
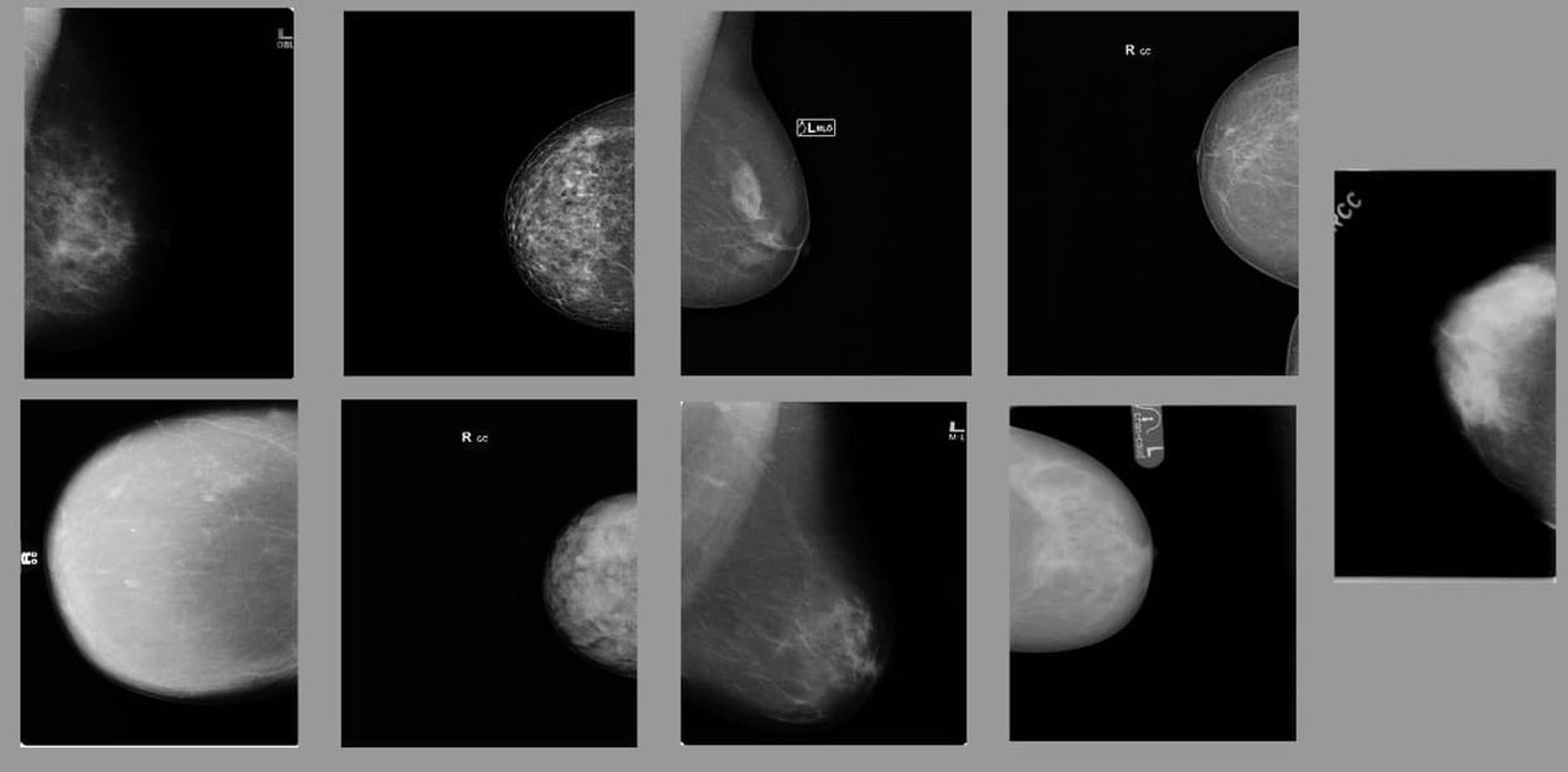
Цельс - это такой комплекс продуктов, который позволяет анализировать разные медицинские изображения - маммограммы молочных желез, флюорограммы, КТ лёгких и мозга, гистологические сканы клеток. с точки зрения ML - это задачи классификации, сортировки, детекции, сегментации и др
на данный момент нельзя сказать, что ML уже прям полноценно помогает врачам, но, кажется, мы уже не очень далеко. самый яркий пример - московский эксперимент mosmed.ai, где ML-системы полгода обрабатывали снимки реальных пациентов из московских больниц
наши флагманские сервисы - это ММГ (маммограммы) и ФЛГ (флюорограммы). если кликнуть на сайте Мосмеда кнопку "Результаты эксперимента 2020", можно увидеть нас в списке лидеров по направлению ФЛГ, так что определённая экспертиза у нас в этом деле есть)
вообще, медицина - это 100% самая интересная область с точки зрения ML, в которой я когда либо работал (а там ещё были финансы, геймдев, политика, психология, видеоаналитика и другое). но одновременно самая сложная и головоломная
ключевая особенность медицинских данных, из которой выливается всё остальное - это безумная сложность в определении Ground Truth. здесь пример разметки одного снимка разными врачами. это при условии того, что мы жёстко запариваемся по написанию гайдбуков для врачей-разметчиков
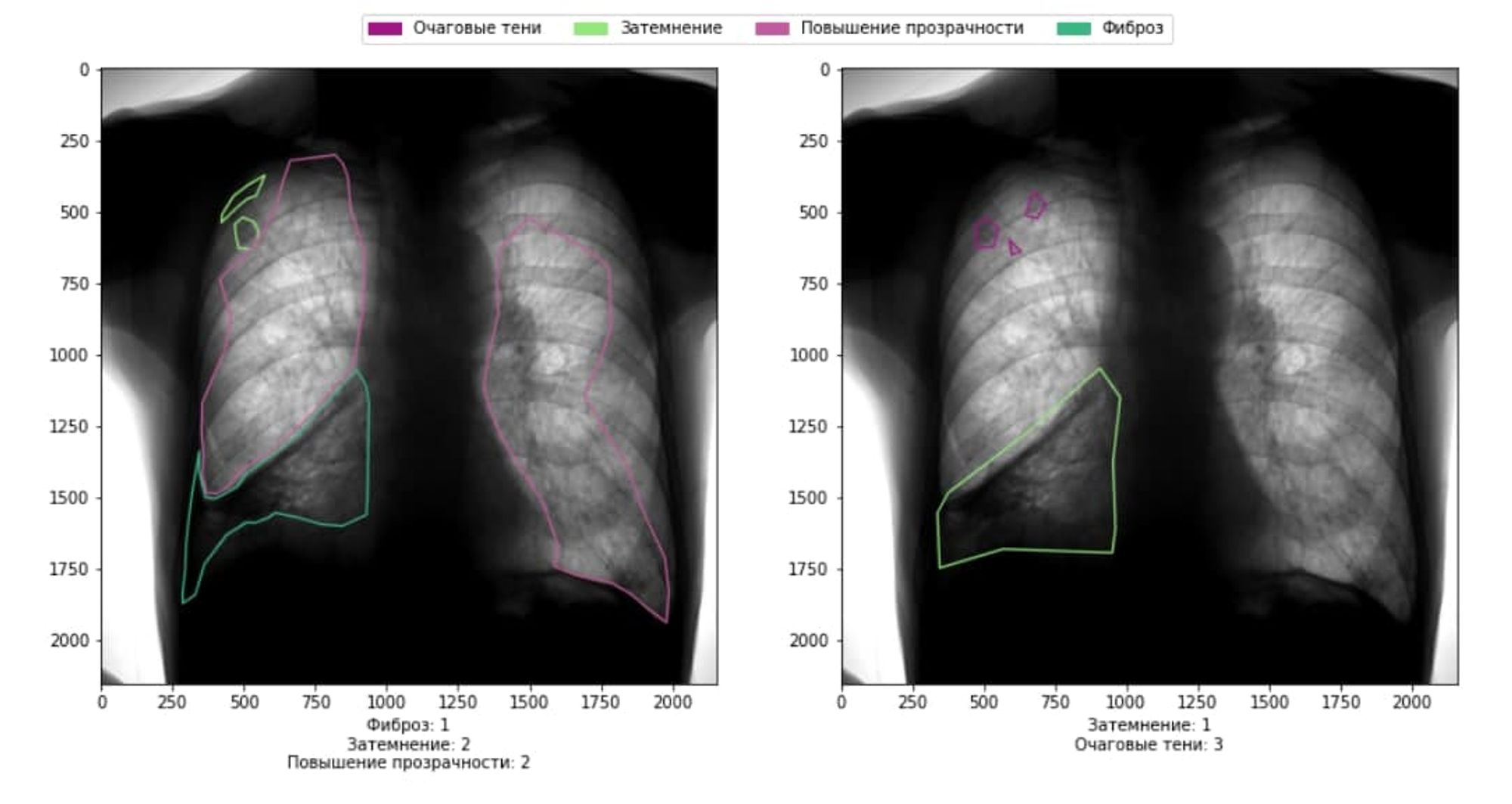
кейсы, где врачи не соглашаются друг с другом, одновременно являются и самыми ценными для обучения сеточек. поэтому приходится идти на разные архитектурные, разметочные и прочие извраты. вообще про работу с мед.даткой я недавно делал доклад на OpenTalks, могу пошарить слайды
помимо проблем с GT могу отметить безумное разнообразие входных картинок (разное оборудование, настройки, лаборанты), дороговизну разметки, высокую репутационную цену ошибок (особенно глупых, типа когда сетка находит что-то вне органа). в общем, область сложная =)
тем интереснее, конечно, решать челленджи, мы постоянно брейнстормим, вообще очень много разговариваем и меняемся идеями, это, кстати, одна из причин, почему я терпеть не могу удалёнку, процесс обмена идеями замедляется в разы
отдельная боль - работа с врачами. user research проводить сложно, фидбек-луп медленный. причины у этого и административные, и личные. многие врачи настроены скептично, не доверяют или боятся ML-систем и не хотят фидбечить. но,к счастью,есть энтузиасты, которые нам очень помогают
при решении любой ML-задачи важно погружаться в доменную область, но в медицине без этого невозможно как разрабатывать, так и продвигать ML-продукты. так что мы много внимания уделяем поглощению мед.знаний. ковид по КТ у нас ребята в команде на глаз определяют не хуже врачей)
вообще я безумно благодарен судьбе, что мне удалось поработать в медицине. помимо того, что это новая, клёвая область, она ещё и идеально сочетается с моим другим большим интересом - процессы разработки ML-продуктов и MLOps
на каждом этапе разработки (оценка новых проектов, разметка и препроцессинг данных, ML-эксперименты, оценка качества модели, деплой, мониторинг) была какая-то интересная доменная специфика, которая заставляла вертеться и искать нестандартные решения
я довольно подробно рассказывал про это на одном из митапов моего любимого сообщества LeanDS - youtube.com/watch?v=uQ--wx… могу в какую-то область конкретную углубиться тут, если будут вопросы)
приходите к нам работать, особенно, если вы в Питере, но можно и без этого) кстати, нанимать со временем становится, как будто, бы сложнее, но я пока до конца не понял, возможно, это иллюзия. про поиск, собесы и найм ML-инженеров можно отдельный тред накатать
за почти два года мы наняли уже больше 20 ML-инженеров и провели сильно больше сотни собеседований. не потянули и ушли за это время двое, так что precision хороший =)
тред про ML в медицине
@dsunderhood Подскажите, какими усилиями это получилось? Кажется, нынче не так просто найти людей, шарящих и при этом заинтересованных менять работу.
хороший вопрос
1 - мы не стеснялись брать крутых джунов и ранних миддлов и давать им докачиваться у нас
2 - юзали не только ODS, но и HH
3 - область медицины многим кажется привлекательной
4 - имхо у нас прикольные собесы, тестовое и фидбек
5 - деньгами не заливали, вилки средние twitter.com/sudodoki/statu…
ещё мне кажется, что многих ребят привлекла возможность получить опыт не только в ML-моделировании, а и в сопутствующих прод-областях - например, сервинг моделей, написание тестовых пайплайнов. мы только недавно начали двигаться в сторону специализации (Data Team, Infra Team)
@dsunderhood вам недоджуны с 0 продакшн опытом нужны?
зависит от джуна. к нам как-то пришёл парень без прод-опыта, но у него пет-репа была так оформлена, что я его без колебаний взял. сейчас один из самых топовых чуваков по архитектуре ML-систем и сервингу у нас) twitter.com/fxfxdxdx/statu…
одно из моих хобби - это миксология или искусство создания коктейлей. каждый вечер буду выкладывать рецепт какого-нибудь из своих любимых, но не супер-известных коктейлей
первый коктейль - это New York Sour. это твист на классический виски сауэр, который, конечно, придумали не в Нью-Йорке
ингредиенты - бурбон или ржаной виски (2 порции), сахарный сироп и лимонный сок (по 2/3-3/4 порции), белок 1 яйца, красное вино
взболтать всё, кроме вина, в шейкере безо льда. добавить лёд, ещё раз хорошенько протрясти, прострейнить в бокал со льдом, на белковую пенку сверху по обратной стороне ложечке долбануть сухого красного винца (я люблю риоху). получится кисло, терпко и офигенно красиво
Вторник
вчера началась конференция MLRepa Week про автоматизацию, MLOps и вот это всё. первые впечатления смешанные, но всё равно круто, что такие эвенты есть, буду следить
а высказаться хочу на тему всяческих высокоуровневых фреймворков, которые обещают самые разные вещи - оркестрацию экспериментов, сёрвинг моделей, деплой, автоскейлинг, а чаще всего - всё вместе. вчера, например, рассказывали про ZenML
безусловно, для разных частей процесса ML-разработки полезно использовать разные инструменты. к примеру, я очень люблю ClearML, который позволяет удобно оркестрировать обучение на разные машины, трекать зависимости, конфиги и метрики
кому-то нравится использовать различные фреймворки для обучения моделей (Lightning, Catalyst, etc), во многих проектах у нас используется DVC для версионирования данных и так далее
но инструменты, которые обещают всё - от автоматического подбора гиперпараметров до автоменеджмента полноценного кубер-кластера, у меня вызывают лёгкое недоумение. на более-менее сложных проектах ты очень быстро упираешься в жуткую негибкость всех этих фреймворков
возможно, я просто не умею их готовить, возможно, у этих фреймворков просто другая ЦА - маленькие команды с ML-системами с несложной логикой, но я в любом случае не вижу смысла полностью коммититься на использование каких-то сырых недорешений, которые падают даже во время демо)
мне вместо этого логичным кажется эволюционное развитие инфры по мере развития проекта. мы начинали с простых Flask-апишек, упакованных в докер, и постепенно по мере необходимости изменяли архитектуру, добавляли инструменты под наши нужды
то же самое, кстати, могу сказать и про остальные процессы ML-разработки в целом - клёво, конечно, с самого начала всё офигенно построить, только вот грустно будет, если проект закроется через 3 месяца
это не значит, что каждый раз надо всё рушить и начинать с нуля, безусловно, все наработки, инфру, опыт нужно использовать, стартуя новые проекты и команды, но мой главный посыл - всё нужно делать постепенно и по мере необходимости, потому что это стоит денег
ну ладно, история про то, как я чуть не угробил жизнь в Нью-Йорке
оказывается, что одновременно работать над ML-стартапом и делать полноценный американский PhD - это не очень просто. оглядываясь назад, я даже не могу сказать, как я не бросил всё и не ушёл в монастырь. мне очень помогла стратегия селективного перфекционизма
ну или её можно проще описать "good enough", я делал круто только те вещи, которые надо было делать круто, а остальное - спустя рукава, в последний момент, но тоже делал. в итоге у меня даже получилось завоевать репутацию крутого русского ML-щика в департаменте
но на моём психическом здоровье работа семь дней в неделю сказывалась средне. я спасался тем, что пил пиво с русским товарищем посреди недели и летал в Питер два раза в год и уходил в жесточайший алко-загул
к этому всему примешивалась достаточно сильное чувство отчуждённости, Нью-Йорк довольно неуютный город, ну разве что ты богатый, наверное. + прозвучит как заголовок с RT, но пресловутая американская свобода слова на поверку тоже оказалась той ещё фикцией
короче, в какой-то момент я приуныл очень сильно и, конечно, же начал пить. я мог по пути домой просто зайти в бар и начать там бухать, знакомиться с какими-то рандомными чуваками, идти дальше пить с ними. в принципе это даже было весело, пока я не перешёл определённый порог
у меня стали пропадать куски ночей, а с утра я не понимал, зачем вставать с кровати. копилась куча дел, бизнес стал пробуксовывать, и от этого я себя чувствовал ещё хуже, короче, замкнутый круг
закончилось всё тем, что сначала у меня украли телефон в баре, потом ограбили на улице, а в конце концов я сам привёл двух типов с улицы в гости, типа выпить, и они обнесли всю хату, пока я был в туалете, и я должен был выплатить 7к баксов соседям. в тот момент я достиг дна
таких денег у меня не было, естественно, не было. как-то по пути на футбол мой американский кореш спросил меня, как я, а я просто сел на землю, заплакал и сказал, что хочу домой
в тот момент мне казалось, что всё, потрачено, дальше уже делать что-то особо смысла нет
что мы имеем спустя несколько лет? я кайфую от своей работы, за неё платят много денег, у меня прекрасная команда, а ещё скоро у меня свадьба. правда, я так и не закончил PhD (по другим причинам), но опубликовал пару статей и получил ещё один магистерский диплом
как так получилось? расскажу, если это пост наберёт 10 лайков хаха
я не ожидал такой скорости)
так, ну сегодня успею только вечерний коктейль
Buffalo Soldier, фирменный коктейль одного из топовейших коктейльных баров Нью-Йорка Death & Co
вам потребуется - орех пекан, соль, перец, кайенский перец, бурбон, сахарный сироп (лучше из коричневого тростникового сахара)
пекан вымачиваете в воде, долго не надо, ну минут 5-10, просушиваете полотенчиком, посыпаете приправами (не супер-густо), подпекаете в духовке (градусов 150-200, минут 15-20, следите, чтоб не начал подгорать). охлаждаете и засыпаете вместе с бурбоном в одну ёмкость
ждём неделю, иногда взбалтывая, процеживаем, получаем божественную орехово-островато-бурбонную жидкость (бурбон, естественно, лучше брать хороший)
для коктейля смешиваем 2 порции настойки и полпорции сахарного сиропа, мешаем со льдом - вуаля. получается крепко и с характером
Среда
сорян, сегодня занятой рабочий день!
было очччень много лайков на твите про моё всплытие со дна, так что продолжаю
фаза 1 - отдых
достаточно удачно совпало, что буквально через месяц после всего этого кошмара наступал новый год, а это означало поездку домой
кое-как я протянул, занял кучу денег (отдавал потом все долги почти два года, у меня это съело просто безумное количество нервов, чуть ли не худшее во всей ситуации)
дома было хорошо, я много ныл друзьям (и даже чутка маме), оказалось, что не я один годам к 25 оказался в кризисе
кто-то советовал психолога, но это точно был не мой путь (но другим вполне может помочь). короче, после пьянок, общения и домашнего тепла стало полегче, и я решил пока не сдаваться
я решил на март поехать к друзьям в Калифорнию на spring break, а пока просто жить (и не пить)
фаза 2 - челлендж
в целом было терпимо, но огромный бэклог задач по стартапу и пхд меня просто удручал, и я решил обратиться к своему товарищу по бизнесу, он всегда упарывался по всяким саморазвитиям и тайм-менеджменту, а я наоборот относился к этому всему крайне скептически
он мне посоветовал книжку "Неделя на пределе" какого-то норвежского типа. терять было нечего, я купил аудокнигу, гулял по Голливуду и Сан-Франциско и слушал о суровой норвежской армии. ощущение было любопытное
идея книги была достаточно простая - нужно прожить 7 дней на 110% своей эффективности, перед этим ещё обязательно подготовиться, собрать фидбек с друзей, коллег и родных и уделить особое внимание своим слабым местам
были всякие простые правила - встаёшь в 5, ложишься в 22, никаких соцсетей на работе, с утра час спорта, правильное питание, тайм-менеджмент и тд, а ещё специальные челленджи - например, с четверга на пятницу ты не спишь, то есть, работаешь с утра четверга до вечера пятницы
в общем, я запланировал такую неделю после возвращения в Нью-Йорк. подробно рассказывать не буду, займёт много твитов, но я реально до сих пор думаю, что без этой штуки я бы оставался на дне сильно дольше
я разгрёб задачи, почувствовал внутреннюю силу и, главное, у меня снова появилась страсть к моим занятиям. я с тех пор довольно позитивно отношусь ко всяким таким техникам. среди них куча мусора, но есть реально крутые простые вещи, советую, например "джедайские техники" ещё
фаза 3 - сложный выбор
ещё одним важным инсайтом стало, что нормально продолжать делать и PhD, и стартап я не смогу и нужно чем-то пожертвовать. смертью храбрах пал PhD
ну как - я продолжал брать бесплатные курсы в NYU (ходил на лекции к ЛеКуну и Чо, даже немного познакомился, преподы из них так себе, но в целом было очень круто), получать стипендию и делать минимум, чтоб оставаться на плаву. в итоге даже опубликовали пару папир с моими методами
в целом всё катилось к тому, что я всё равно PhD брошу (моя семья была просто в шоке, чувак решил вернуться из ОМЕРИКИ в Рашу), а весной 2019 года мне поступило предложение построить в Питере с нуля DS-команду. от такого предложения я отказаться не мог, но об этом в другой раз
если у кого-то есть похожие истории о всплыве со дна, делитесь тут, я репостну какие-нибудь классные
ну и заодно рубрика "вечерний коктейль"
я большой фанат разных версий негрони, мне очень нравится их горькость и травянистость, но для многих это перебор
попробуйте им (и себе) сделать коктейль Enzoni
вам понадобится - 1 порция джина (любого, хоть бифитер, но чем вкуснее, тем лучше), 1 порция кампари, 5-6 зелёных виноградинок, 3/4 порции свежего лимонного сока и полпорции сахарного сиропа
раздавливаете в шейкере маддлером или любой тяжёлой хернёй виноград, закидываете остальное, засыпаете лёд, хорошо встряхиваете и стрейните в бокал с 2-3 кубиками льда
получается значительно более летняя и лёгкая версия негрони
я тут подумал, прикольно, наверное, смотрится эта рубрика на фоне историй, как я спивался в Нью-Йорке. я до сих пор люблю прибухнуть красиво, но в качестве лекарства от грусти или нервов больше его никогда в жизни не буду использовать
немножко про мир DS ещё. мы у себя в отделе практикуем свои дата-фесты, где рассказываем друг другу всякие клёвые штуки. очень рекомендую, это бомбическая форма тимбилдинга (не всё же бухать). чтоб вы представляли что и как примерно у нас, вот афиши с прошлого и этого разов

только не хантите моих пацанов и девок со своими безумными вилками, а то я вас по айпи вычислю
Пятница
вчера у нас был первый день феста, было много клёвых докладов. мне по контенту ближе всего был доклад про парный DS. почти все рассказы на эту тему обычно ограничиваются вольным пересказом Кента Бека
здесь же мне очень понравился упор именно на специфику ML-работы, в которой (по крайней мере у нас) именно кодинг является далеко не ключевой составляющей. ну и было много клёвых практических советов по внедрению, так что после феста оформим и выложим к себе на ютуб-канальчик
я, конечно, понимал, что на одной неделе вести твиттер тут и проводить фест будет непросто задачей, но всё равно согласился)
на выходных постараюсь долбануть побольше контента, даже что-то про ML напишу, это же, вроде, ML-твиттор?
пока хочу сказать что. цените свою работу, ребята. мы делаем офигенно интересные штуки, получаем за это много денег, общаемся с потрясающими людьми с супер-разнообразным бэкграундом и реально каждый день меняемся и развиваемся как люди и специалисты
если вы чувствуете, что ни одного из этих утверждений про вас - меняйте работу, и срочно
да, бывают временные трудности, творческие кризисы, но это ощущение нереальности и офигенности происходящего меня не покидает давно
вечерний коктейль
обожаю канал How To Drink, это напиток, о котором я узнал оттуда, Earl Grey MarTEAni
понадобится - порция сахарного сиропа, 3/4 порции лимонного сока, 1.5 порции бергамотового джина, 1 белок
бергамотовый джин - берёте бутылку любого норм джина, засыпаете туда несколько ложек хорошего чая Earl Grey. потряхиваете бутылку в течение часа, готово
делаете римминг (лол) бокала - на тарелку высыпаете сахар, край бокала натираете лимоном, катаете край стакана по тарелке
всё смешиваете безо льда в шейкере, встряхиваете, добавляем лёд, снова встраиваем, стрейним в подготовленный бокал - получаем божественную чайно-алкогольную субстанцию. сахарный край обязателен!
Воскресенье
с утреца в вокресенье хочется поговорить про разметку данных. любой DS-менеджер при организации процесса разметки сталкивается с quality-cost trade-off
качество данных обычно растёт с увеличением расходов на разметку
для улучшения качества можно тратить больше денег на отбор и обучение разметчиков, кросс-разметку и экспертную перепроверку разметки. естественно, нашей задачей является получение необходимых метрик при минимизации расходов
первой проблемой является выбор сэмплов для разметки. с определённого момента разметка случайных выборок данных практически перестаёт приносить значимые улучшения в качестве моделей. эта проблема усложняется для несбалансированных популяций
например, у большинства пациентов рака, слава богу, нет, но нас интересуют именно такие кейсы. кроме того, раковые образования ещё и имеют разные виды, которые тоже отличаются по частоте встречаемости
существует отдельная область, которая пытается решить эту задачу - активное обучение. при этом у меня сложилось впечатление, что качественных практических материалов на эту тему не так уж и много
статьи, которые пытаются сранивать умные методы сэмплинга с рандомными, обычно рисуют графички для мниста. понятное дело, что на практике это всё потом чаще всего не заводится
обычно мы хотим размечать больше примеров, в которых модель не уверена, и которых не было в обучающей выборке до этого. оценить конфиденс сетки в своём предсказании не так уж просто, просто по вероятности это получается плохо
можно обучать специальные конфиденс-бранчи, можно использовать дропаут, можно обучать вспомогательные сети для предсказания ошибок, можно кластеризовать репрезентации, чтобы искать OoD-кейсы
короче, серебряной пули нет, и в разных случаях лучше работают разные способы. в любом случае стоит начать хотя бы с простых методов балансировки обучающих данных, а по мере необходимости вкладывать вычислительные ресурсы в рисёч эффективности других методов
проблема 2 - несогласованность разметки. в некоторых задачах проблем с этим немного, но в медицине это чуть ли не ключевая проблема
три врача могут абсолютно по-разному разметить один и тот же снимок, начиная от разных форм масок/коробок, заканчивая полным расхождением классов
да что уж там - один и тот же врач в разные дни может его разметить по-разному в зависимости от того, сколько вчера спал или выпил. мы случайно отдали в разметку тот же пак тому же врачу - потом нормально так офигели
какую-то мета-информацию (другие анализы, история болезни пациента) к картинкам найти получается очень редко. в итоге, мы встаём перед вопросом - а что нам делать с тремя этими разметками?
привлекать эксперта для разрешения конфликтов, собирать консилиум, пихать все варианты в обучение, делать софт-лейблы, вообще забить на кросс-разметку, выбрать одного прикольного врача и сэкономить денег?
как и очень многое в мире ML, это решение - очередной гиперпараметр. на разных задачах разные стратегии работы с кросс-разметкой будут приносить разные результаты
единственное, к чему мы пришли однозначно - необходимо приложить максимум усилий для создания качественных валидационных и тестовых сетов, без этого можно просто в какой-то момент съехать с катушек и начать вслепую бродить в темноте
вообще меня крайне интересует тема оптимизации процесса разметки, но что-то классное на эту тему попадается не так часто. недавно на OpenTalks была секция про краудсорсинг от Толоки. было прикольно, но крауд-разметка всё-таки довольно сильно отличается от экспертной по специфике
если кому-то интересна эта тематика или вы знаете какие-то интересные материалы/сообщества, пинганите меня =)
напоследок хочу обсудить скейлинг ML-команд и отделов. за полтора года существования наша ML-тусовка выросла с 5 до 20 человек, и я могу выделить три важных момента, с которыми я столкнулся
в какой момент выделять отдельные функциональные команды
необходимость понимания основ ML у PO и других важных членов команды
необходимость переосмысления своей роли и личной трансформации
с самого начала я решил строить в некотором смысле фулл-стак команду. наши ML-инженеры владели всеми участками DS-процесса - от сбора данных до деплоя и мониторинга. была отдельная команда бэка и фронта, которая занималась интеграцией с медицинскими организациями
но само ML-ядро являлось полноценным отдельным сервисом, который делали мы. на том этапе мне это казалось (и кажется) оправданным решением, из плюсов - гибкость распределения ресурсов между задачами и полный взгляд на весь продукт и его нужды
когда к нам приходили потом ребята на собес и говорили, что в своих компаниях никогда не писали тесты для моделек, никогда их не оборачивали в апишки и не мониторили их предикты, а только в джупитере пилили модельки и потом их куда-то отдавали - для меня это было диковато
по мере развития продуктов наращивание объёмов разметки и количества датасетов, необходимость скейлиться и выдерживать определённый перфоманс постепенно привели к тому, что задачки с лейблами Chore, Data Analytics, Deploy стали доминировать в бэклоге
в то же время повышение ML-метрик становилось всё сложнее, всё больше экспериментов заканчивалось неудачно и всё больше времени нужно было для брейнстормов и генерации новых идей
в определённый момент сложность продукта и объём соответствующих задач увеличивается до такой планки, что стоит задуматься о выделении отдельных функциональных команд. первые логичные кандидаты - Data Acquisition Team и ML Infra Team
в зависимости от ваших потребностей могут появиться и другие команды, например, User Feedback Team или Data Engineering Team. но я всё-таки продолжаю быть уверенным в том, что это разделение должно происходить постепенно и по мере необходимости (но важно и не проспать момент)
понятно, что всё вышесказанное основано на моём опыте, и больше релевантно для стартапов и компаний, где ML только зарождается
жизнь показывает, что сложно оунить продукт, лидить команды и вообще играть какую-то значимую роль в ML-продуктах без понимания основ того, как работает машинное обучение, как считаются метрики и тд. поэтому пушьте своих менеджеров, пусть образовываются)
я недавно даже составлял список литературы, видео и курсов для начинающих ML-оунеров и менеджеров, если интересно, пишите
этот пункт не особо специфичен для ML. довольно часто на всяких тимлидских сходках обсуждается проблема - вот был я обычным разрабом или ML-инженером, а потом меня поставили тимлидом, теперь мне грустно/плохо/некомфортно. мне вот тимлидом небольшой команды быть очень нравилось
ставишь процессы, генеришь идеи, сам что-то пилишь время от времени - мечта, короче. в какой-то момент количество MLщиков у нас в компании превысило 15, и вот тут-то меня и поджидали настоящие психологические сложности

в какой-то момент мне начало казаться, что если я уеду на Фареры на полгода, или я сопьюсь, или решу дописать диссертацию - ничего не изменится, потому что все команды уже способны работать автономно. это можно, наверное, даже считать достижением, но внутренне мне легче не было
у меня начался некий творческий кризис, производительность сильно упала, я стал больше вафлить и чилить. очевидно, назрели какие-то перемены. первым делом мне полезли в голову дурацкие мысли про смену места работы
в итоге я поговорил с руководством, с коллегами, с друзьями, сам порефлексировал, и пришёл к выводу, что тут требуется некоторая внутренняя перестройка. какие-то вещи нужно просто отпустить и вместо этого вложить свою энергию и страсть в другие вещи, которые стали боттлнеками
в целом сейчас чувствую, что я на правильном пути. один совет могу дать - не держите в себе свои переживания. да,не стоит, наверное, вываливать на своего руководителя любые мелкие психологические неурядицы, но иногда просто требуется с кем-то поговорить. для того 1:1 и существуют
закончился мой последний рандомный поток мыслей в этом твиттере, надеюсь, кому-то было любопытно) вечерком закрепим последним вечерним коктейлем
итак, завершающий вечерний коктейль
Шерри Кобблер - очень старый, всемирно известный коктейль, про который почему-то никто не знает в России
понадобится - херес амонтильядо или олоросо (3 порции), сахарный сироп (1/2 порции), апельсины (2-3 колечка), ягоды/мята для украшения
в шейкер засыпаем апельсин и сахарный сироп (количество регулируем в зависимости от сладости хереса), чутка разминаем, добавляем херес и лёд, встряхиваем хорошенько. в бокал добавляем крошёный лёд или кубиками, стейним напиток в бокал, украшаем ягодами, мятой или апельсином
мне шерри кобблер и его вариации очень по душе, но я его нечасто делаю, только потому что не очень просто стало найти херес дешевле 3 тысяч... кстати, к предыдущим сериям забывал фотки прикладывать почему-то =)

всем спасибо огромное за то что читали, комментировали и лайкали, я оч кайфанул! и всем классной рабочей недели!


