

Архив недели @XOR0SHA2wine
Неделя началась с пранка: Алиса представилась Янисом и никто не заметил.
Понедельник
Привет! Меня зовут Янис Молодцов, я инженер, который обучает и доводит до продакшена модели. Уехал из России в детстве. Анализом данных занимаюсь 3 года. Сейчас работаю в компании, которая занимается кибербезопасностью.
На данный момент работаю над проектом, в котором методами ML анализируется свыше миллиона новостей в день.
На этой неделе мы обсудим:
ML в ИБ
NLP
Постановка и оценка задач
Как вкатиться в DS
Своё писать или либку тащить?
ФП в ML
Как следить за трендами в ML
Задачи на стыке ИБ&ML можно разделить на инженерные и требующие научного поиска (как и в DS в целом). Сюда я не отношу задачи, вроде имитации опьянения у нейросети, чем занимались мои знакомые безопасники. Хотя иногда это помогает получить полезные идеи / решения для продакшена.
В некоторых компаниях используют фриковые проекты или игры вроде спортивного хакинга (CTF) для тимбилдинга. В качестве friday project раз в месяц. Про фриковые проекты мы еще поговорим подробнее, но раз уж речь зашла про AI drugs, то вот ссылочка:
github.com/wallarm/neural…
Эмуляция закупоривания сгустками крови доступа кислорода к нейрону реализована через указание минимально возможного веса нейрона. Воздействие DMA на нейроны представлено произвольным весом на нейрон. На выходе – искаженные картинки, будто глазами Torch/pytorch, который торч.
Но этот проект оказался полезен для оценки робастности моделей!
Так, ну а теперь задачи на стыке ML и ИБ. Можете задавать вопросы по конкретным, я расскажу детальнее.
Задачи на рисеч (т.е. пока не имеющие SOTA):
1.1. Сбор пользовательских данных (пол, возраст, уровень дохода и пр.) в маркетинговых целях (для Data Management Platform).
1.2. Антикликфрод (детектирование ботов, которые скликивают рекламу).
1.3. Идентификация взломщика на основе поведенческого анализа.
1.4. Поиск бекдоров, которые оставляют разработчики с незамутненным сознанием (статический анализ кода, совмещенный с динамическим анализом)
1.5. Анализ репутационных рисков для ФЛ и ЮЛ в больших объемах данных (текст, видео, картинки в новостях и соцсетях)
1.6. Частичная автоматизация OSINT (профилирование людей и групп через анализ социальных графов, поиск аккаунтов в соцсетях с помощью распознавания лиц)
1.7. Детектор синтезированного голоса и фейковых видео. Есть технологии, вроде lyrebird и face2face, с помощью которых можно подделывать интервью публичных личностей или использовать синтезированный голос руководителя компании для соц инженеринга при комбинированной атаке😈
1.8. Self-adaptive honeypots, основанные на теории игр, reinforcement learning и психологии киберплохишей. Ханипоты - это имитация реальных сервисов, они намеренно делаются уязвимыми, чтобы собирать данные о векторах атак и предсказывать возможные стратегии злоумышленников.
1.9. Adversarial Generative Networks -- каким образом злоумышленник может повлиять на результаты работы модели, которая дообучается в риал-тайме. Если на вход модели... будет поступать... Ммм как сексуально это звучит...

Простите, отвлекся. Если на вход модели будет поступать небольшое количество данных, характерных для поведения злоумышленника, они не будут детектироваться как аномалия, а со временем точность модели понизится и атака может пройти незамеченной.
1.10. Мультиклассовая классификация атак в WAF (особенно детектирование 0day уязвимостей и bypass). Раньше для этого использовали regexp, сейчас используют машинное обучение. Лучшие решения у Wallarm. Есть еще у Imperva проприетарное для тестирования самих WAF.
1.11. Идентификация пользователей по стилистическим и лингвистическим особенностям речи. Метод идентификации авторства на основе анализа текста является частным случаем биометрической идентификации и применяется в DLP.
При этом остальные задачи, связанные с DLP-системами, уже перешли в стадию зрелых промышленных решений, и дальше там остается только методично копать в глубину, устраняя недостатки существующих методов. Основная борьба чисто за то, как побольше данных с сотрудников собрать.

Теперь чисто инженерные задачи. Поскольку задачи для прода, буду указывать их с компаниями, которые активно этим занимаются.
2.1. Аномалии в сетевом траффике
(Лучший антидидос у Cloudfare сейчас)
2.2. карточный антифрод как детектирование аномалий
(Cybertonica, Group IB)
2.3. Выход из строя банкоматов / мониторинг состояния критически важной инфраструктуры (Лаборатория Касперского)
2.4. Антифишинг, антиспам методами NLP и fuzzy hashing (Group IB и компании, не связанные напрямую с ИБ - например, почтовые сервисы поисковиков)
2.5. Детектирование вредоносного кода (задача
бинарной классификации) на основе сигнатур эксплойтов или уязвимостей. Сейчас чаще применяется сигнатурный анализ на основе уязвимостей, поскольку он требует меньшего количества сигнатур в базе. Но это анализ постфактум.
Для детектирования новых вирусов, которых еще нет в базе, применяется поведенческий анализ. Но это задача не для одного исследователя. Анализом малвари должен заниматься целый
отдел, должны быть сбор образцов, песочницы, вирусные аналитики,
инфраструктура, threat intelligence.
Также проблематично достать актуальные данные. Датасеты, которые есть в открытом доступе, устаревшие. Реверсить антивирус, чтобы вытащить базу сигнатур, не очень оправданно, поскольку каждые 3-5 лет она обновляется.
Для экономии места на жестком диске пользователя из базы удаляются старые вирусы (поэтому их модификации могут не детектироваться новой версией антивируса). Сейчас этим направлением очень активно занимается Лаборатория Касперского.
Сложности задач на стыке ИБ и МЛ:
Нужно постоянно дообучать модели, между киберплохишами и вендорами ведется гонка вооружений
Про SOTA узнаешь чаще всего в кулуарах. Академические статьи на шаг назад от индустрии в этой области. Доклады устаревают уже за время их подготовки
Не всегда можно использовать нейросетевые подходы. Модели используются как СППР - решения все же принимает человек, который несет ответственность. Есть задачи, где ЛПР хотят интерпретируемости до коэффициента, а не просто вердикта от модели. Например, карточный антифрод.
- Почему я бы рекомендовал идти в профессию ML engineer?
- Допустим мы все заканчиваем школу со уровнем знания по математике из нормального распределения (E, sigma).
За универские N курсов по математике мы сокращаем дисперсию на sigma/N и увеличиваем мат ожидание на 1.1 ^ i для i=1..N, и строим функцию условного мат ожидания уровня математики от мечты о будущем P(Maths|Dreams).
После окончания универа с каждым годом уровень математики сокращается с 0.8 ^ year.
Вопрос: чему будет равно P(Dreams|Maths) через 3 года, если ты упоролся?
Когда-то я думал, что вкладываться в работу лучше, чем вкладываться в какие-либо отношения с людьми. Отдача от работы пропорциональна инвестициям времени в неё с вероятностью 0.5 (взлетит - не взлетит). А люди... Да что эти кожаные мешки знают о вероятности?

Но потом я осознал, что технологии создают пока что тоже люди (если можно считать говнокодеров людьми). И работать приходится с людьми, выстраивая с ними минимум деловые отношения. И чтобы хотя бы не выгореть от всего этого, надо инвестировать время в гармонию во всем
Единственное, что меня отталкивает в людях – непоследовательное поведение. Для меня существенно задавать аксиоматику по человеку у себя в голове. Когда сам человек её разрушает, у меня математическое отторжение. Появляется мысль, что это неустойчивая динамическая система.
Раз уж зашел разговор белковая нейросеть vs. искусственная, предлагаю обсудить вопрос:
- Может ли машина кодить?
В качестве иллюстрации вместо мемов:
youtu.be/Pelrr__9qx8
youtu.be/8a-EObAhYrg
youtube.com/watch?v=2BWFlO…
Если подходить к этому вопросу с позиции аналитических вопросов про тьюринг полные языки, то в общем случае нельзя писать программный код. Однако можно взглянуть на проблему через призму машинного перевода.
Существует гипотеза, согласно которой сходство языков программирования и естественных языков позволяет применять к анализу кода методы Natural Language Processing. Задача построения эмбеддингов кода до сих пор остается открытой, но уже есть рабочий плагин JB Deep Bugs для PyCharm
Для генерации кода могут использоваться, например, реккурентные сети, использующие структуру кода для его генерации в AST. Или вариационный автокодировщик, позволяющий обучаться на примерах описания кода на естественном языке.
Идеальное ТЗ – это набор тестов. Все тесты прошли – значит, код делает, что должен делать, излишнего не делает. Если мы так формализуем, то почему нельзя такой код сгенерить? Возможно, будущие программисты – это тестировщики, пишущие скрипты, под которые генерится код моделью.
Больше всего исследований на эту тему у Microsoft Research. Возможно, с интересом к генерации кода связана активность Microsoft относительно покупки и дампа гитхаба.
Разбор актуальных статей по теме можно посмотреть здесь:
m.youtube.com/playlist?list=…

Также я бы рекомендовал в нагрузку к расширению общего кругозора по вопросу посмотреть следующие неплохие расширения / тулзы:
github.com/marketplace/co…
github.com/marketplace/co…
github.com/marketplace/co…
github.com/marketplace/co…
github.com/marketplace/de…
Пара вводных ссылок по теме ML&cybersecurity:
github.com/oreilly-mlsec/…
media.kaspersky.com/en/enterprise-…
Среда
Тест на возраст. Что вы представляете, когда слышите слово "трансформер"?

Вчера мы должны были обсуждать NLP. Был так занят NLP, что не было времени на соцсети,к сожалению. Поэтому эту интересную область мы обсудим сегодня, вместе с темой по плану "Постановка и оценка задач". Но сначала пару слов про work&balance, с которым у меня проблемы.
Работа - это целая компания, которая не развалится, если ты уделишь пару часов близким. Если развалится, то что-то не так с компанией и образом жизни. А вот близкого, который может исчезнуть в один миг, ты уже не вернешь. Но мы не ценим этого, не видим за амбициями и честолюбием.
Век карьеры и потребления: больше поглоти, больше заработай, будь лучше других. Почему бы не быть просто счастливым?
Нравится 10-минутная лекция на эту тему:
ted.com/talks/nigel_ma…
Цитата оттуда:

Четверг
Natural Language Processing (компьютерная лингвистика) – область на стыке ИИ и лингвистики.
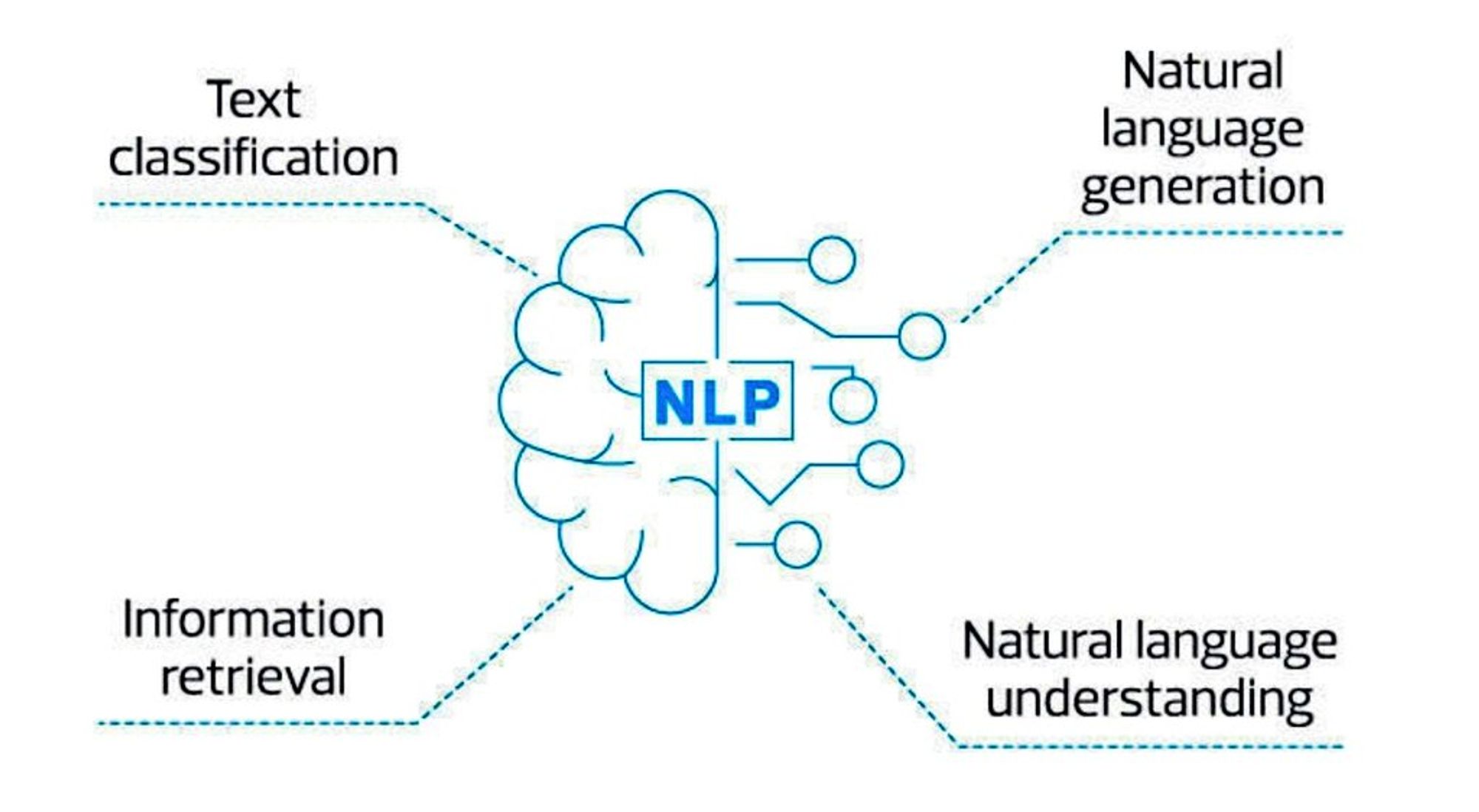
Бизнес-задачи, где применяется NLP:
• Антиспам
• Поисковые системы
• Чат-боты
• Вопросно-ответные системы
• СППР
• Машинный перевод
• Автодополнение
• Голосовое управление
Всё это разнообразие сводится к математике. Главное правильно понять что является целевой переменной
В терминах ML эти задачи декомпозируются на:
Тривиальные
• Классификация
• Кластеризация
• Оценка семантической близости
• Предсказание следующего слова
• Построение языковой модели

Специфические
Построение устойчивых к шуму векторных представлений слов
анализ тональности
Named Entity Recognition
Извлечение фактов
Разрешение неоднозначности
Информационный поиск
Перевод речи в текст
Диалоговые системы
Вопросно-ответные системы
Машинный перевод
Суммаризация

Специфические задачи декомпозируются на тривиальные, чаще всего – на классификацию. Но в последнее время наблюдается тренд решать задачи нейросетями с end-to-end архитектурой

Ограничения NLP:
• Сарказм, ирония
• Фейковые новости -- нельзя детектировать несоответствие фактам реального мира (эта задача эффективнее всего решается с привязкой модели к сайтам перепроверки фактов людьми)
• Аналитические выводы без экспертных оценок – модели нужна интерпретация
• Зависимость от субъективности, заложенной при разметке
• Зависимость вообще от данных (например, модели машинного перевода, обученные на религиозных текстах, иногда выдают перевод с сакральным оттенком
Пятница
@dsunderhood @XOR0sha2wine Так возможно достичь баланса или это только высокопарные слова? Ведь от чего-то придется отказаться
Думаю, что можно достичь баланса не каждый день, а в целом за неделю. Это вопрос умения договариваться. Например, у меня на неделе плотная работа, выходные – время для близких и для самой себя. Но в будни я нахожу хотя бы несколько минут для тех, кто мне важен twitter.com/kellyclip_/sta…
- Если все с крыши прыгнут ты тоже прыгнешь?
- Да
(с) Машинное обучение
Суббота
О постановке и оценке задач в DS.
• Наиболее эффективно формулировать задачи для дата саентистов в форме "Дано - Найти - Критерий".
• Лучше, когда это делает сам дата саентист, обсуждая бизнес-задачу с продуктовым менеджером / заказчиком.
Дано - у большинства компаний на вопрос о данных ответ: "У нас много данных😎🤟" Приходится уточнять, какие данные есть, каких не хватает. Нужно ли размечать. Какого они качества. Лучше просто пример запросить. Иногда в итоге приходится делать прототип на открытых датасетах.
Найти - что должно быть на выходе модели, насколько важна интерпретируемость. По сути это перевод с языка поставки бизнес-задач на язык математики. Определив, какую целевую переменную мы оптимизируем, не обязательно грузить этим менеджера :)
Критерий - это про метрики, внешние и внутренние. Внутренними (accuracy, precision, recall, F1) тоже лучше не грузить менеджера, у каждого своя работа. Имеет смысл сводить эти метрики к бинарным (AUC ROC), потому что их легче изобразить на графике, а менеджеры любят графики
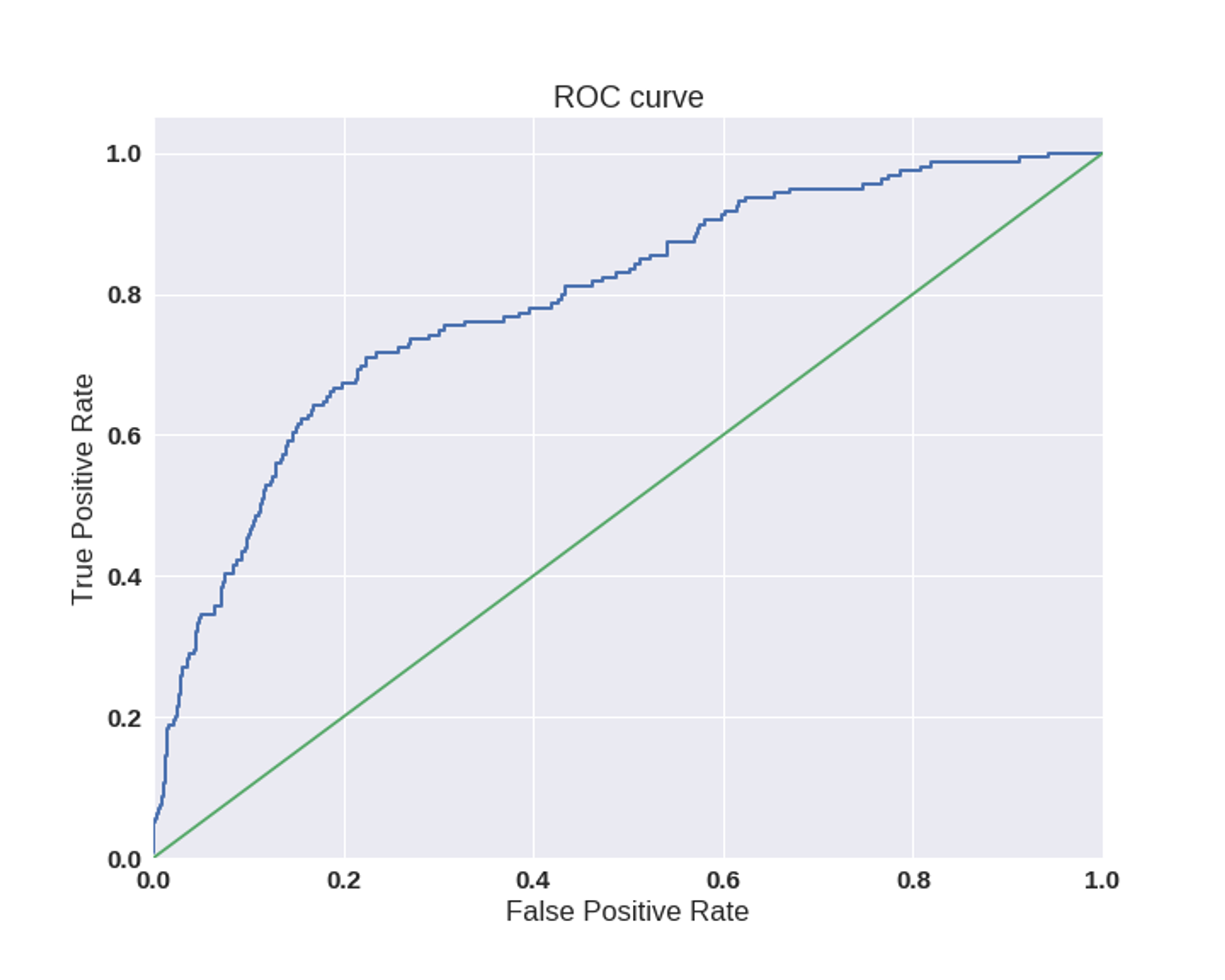
Внешние метрики зависят от доменной области - именно их и озвучивает менеджер. Иногда бывает, что нет бейзлайна - качества текущего решения, которое нужно превысить. Тогда нужно обмазать сервис логами и померить текущую эффективность, чтобы смотреть, улучшит ее или ухудшит ее ML.
Иногда приходится ориентироваться на критерий человеческого восприятия, отдавая вывод модели на суд гастарбайтерам с Толоки. И улучшать качество итеративно (с каждым релизом модели приближать ее вывод всё больше к
человеческому решению).
Также надо выяснить, что является шумом в данных. И важнее точность или полнота. Например, в карточном антифроде и мониторинге угроз ИБ важнее полнота, а в антиспаме важнее точность.
В кровавом энтерпрайзе чаще используют классический ML, типа лог регрессии и xgboost. Требования к небольшим затратам вычислительных мощностей важнее качества, которым можно было бы низвергнуть остальные SOTA.
Могут в качестве А/В-теста выпустить в прод модель, где F1 выше 0.5, и смотрят на изменение внешних метрик. Если улучшение качества модели по времени будет затратнее, чем увеличение прибыли от дальнейших улучшений качества модели, ее принимают такой какая она есть
В зависимости от требований к соотношению качества и вычислительных мощностей, выбирают вариант fine-tuning'а языковых моделей (word2vec, fasttext, BERT - имя им легион):
Дообучают всю модель под конкретную задачу
Вывод модели используется как фичи, она сама не изменяется
В первом случае мы получаем:
превосходные результаты на больших датасетах
- Затратно по вычислительным ресурсам: для k задач нужно держать k моделей на сервере
- Долгое время обучения (например, BERT дообучается месяцы на GPU, дни на TPU)
Во втором случае:
Для хороших результатов не нужны огромные датасеты
Для решения k задач нужны всего она тяжеловесная модель и k легковесных моделей (например, BERT / fasttext + 2(3)-слойный перцептрон или logreg / XGBoost / KNN / k-means / etc.)
- качество немного ниже
Ссылочки по NLP:
nlp.rusvectores.org/ru/ - поиск статей
coursera.org/learn/language… - неплохой курс
nlpub.ru - инструменты (там не про все конечно, область меняется очень быстро)
@dlinnlp_discuss , @dlinnlp - тг-каналы
Один из наиболее интересных вопросов для меня в последнее время. Что у вас используется для доставки данных к моделям и их предобработки? Свои инструменты для пайплайна пишите или тащите либку?
Пример своего:
• Динамическая многопоточная модель
• Брокер сообщений - RabbitMQ
• Балансер смотрит на длину очередей, и при необходимости, поднимает новые потоки обработки, разгребающие очередь параллельно. Как только очередь пустеет, потоки убиваются – все, кроме "дежурного"
Один из примеров использования готовых инструментов: для фичей DVC, для метрик ML Flow. Для прода уже можно через Airflow раскатать.
Понедельник
Поговорим немного про ФП и ML. Есть такая неизбитая исследовательская тема – применение теории категорий для описания архитектуры программ / нейросетей.

Пример статьи, объясняющей в терминах теорката, как запрогать нейросеть на функциональном языке:
arxiv.org/pdf/1711.10455…
Backpropagation рассматривается как метод, зависящий от выбора размера шага и функции ошибки, а сами нейросети как метод определения параметризованных функций.
Как вкатиться в Data Science? У каждого свой путь. Я в свое время читала статьи проф. Константина Воронцова и написала ему с вопросами. Он разрешил мне приходить на его семинары в ШАД. Каждые выходные я моталась из Питера в Москву. Очень нравились атмосфера и контингент семинаров
Потом мне предложили там проект по анализу новостей для крупного СМИ. Свыше миллиона новостей. Нерешенная математическая задача тематического моделирования. Было интересно посмотреть, как работает библиотека BigARTM в проде, поэтому я согласилась перейти в команду заказчика.
Далее были проекты для зеленого банка в магистратуре и проекты от знакомых разработчиков с митапов, которым не хватало экспертизы в ML. Наиболее интересный - чатбот для американской компании. Потом я ушла на фуллтайм в крупную соцсеть. Сейчас в компании, которая занимается ИБ.
Помимо этого, веду консультации по чатботам и использованию BERT. Если интересно пообщаться на профессиональные темы – стучитесь в твиттере @XOR0sha2wine , в тг @chameleon256 .
Кстати, зовут меня Алиса Хорошавина.
На мой взгляд, вкатываться в DS нужно прежде всего через проекты. Математику знать на уровне профессора не нужно, если вам интересует промышленный ML. Достаточно понимать работу алгоритмов под капотом настолько, чтобы можно было изменить что-то в исходниках библиотеки под себя.
Также важно общаться с коммьюнити. Это источник новых идей, обмен знаниями о трендах, возможность найти интересные проекты. И можно иногда напрямую спросить у создателей какого-то фреймворка смысл их метрики или место в коде где её можно заменить на другую.
Например, недавно мне пришлось искать во фреймворкаюе на тысячи строк нужныц кусок кода, чтобы добавить возможность регулировать точность и полноту. Я могла бы потратить на это несколько дней, но спросила у создателя фреймворка. В документации этого не было.











