Архив недели @IAshrapov
Понедельник
Всем привет! Меня зовут Инсаф Ашрапов. Эту неделю коллективный ds твиттер будет за мной.
Немного обо мне: сейчас senior ds в Сбере, основные задачи по мониторингу юр. лиц после выдачи кредита, но не только. До этого работал в мейле и tele2.
Надеюсь успеть рассказать про ml, kaggle, computer vision и ганы, и конечно же по карьеру. После может дойдет и до моих увлечения.
Этот тред будет по карьеру, но пока про мою.
Начинал работать как наверное почти все, еще учась в универе. Заканчивал кстати МФТИ. Кафедра была от Сбертеха, так и я начал там работать.
Если говорить про МФТИ - первые 2-3 курса самая жесть, потом значительно легче.
Наверное потому, что как раз к 4му курсу заканчиваются основные фундаментальные курсы по матану и физике. Матан в ds пригодился, физика скорее нет, но было интересно 😅
Кафедра от Сбертеха (mipt.ru/education/chai…), были хорошие курсы, особенно по алгоритмам и джаве. Курсы по ml`у вел Кантор, тот который еще попал на обложку Forbes. Курсы Кантора, самое положительное - это то что они сподвигали тебя учить ds самостоятельно.
А так курсы Кантора были много про теорию с доказательствами теорем. Зато очень зашла его рекомендация специализации ml на яндексе, если ничего не знаете в ds советую начинать именно с нее ru.coursera.org/specialization…
В целом все образование у меня, но я думаю это справедливо для большей части образования, очень фундаментальное. И есть значимый недостаток практики, бизнесовых курсов, курсов по тем же софт-скиллам. Остается надеяться, что в будущем станет лучше.
Про работу в Сбертехе - у меня это было про инженерную работу с данными, в основном на SQL. В итоге свелось к написанию различных метрик и проверок качества новых загружаемых данных. Как окажется в будущем - SQL знать полезно, вопрос качества данных стоит остро почти везде.
В будущем SQL пригодился на каждой работе. Так что изучайте SQL. Даже с хадупом/спарком можно отлично работать с обычном SQL
После я попал дата аналитиком в mail, а именно в delivery club. Пришлось научиться пользоваться excel
м и powerpointм, и в целом научиться делать качественные и достоверные выводы по данным. Презентации до этого делал только в универе, и было больно тк руководство хотело красивоВ DS сообществе принято ругать как excel, так и презентации. Но зачастую бизнес хочет сам покрутить данные, excel же инструмент зачастую единственный инструмент которым они умеют пользоваться.
Презентации лучший способ донести свою работу, и в целом помогают помочь структурировать твои выводы, найти слабые места в повествовании.
Про презентации очень советую книгу "Говори на языке диаграмм. Пособие по визуальным коммуникациям" от
Джин Желязны (Say it with Charts The Executive's Guide to Visual Communication) mann-ivanov-ferber.ru/books/mif/026/
Написал сотрудник McKinsey, а они умеют делать презентации
Из забавного что там было. Выходил в поле работать курьером - доставщиком еды. Все было по-настоящему: рестораны не знали кто мы, клиенты были настоящие. За эти два+ часа доставил 5 заказов, прошел 11 км. От двух клиентов получил чаевые в сумме на 100 рублей.
Все это было в выходной день, так что за трудовые успехи выдали купон на delivery club на 1000 руб. Опыт полезный - дата аналитику и ds`у полезно увидеть бизнес процесс воочию.
Продолжаем про опыт.
После мейла пошел в Tele2. Занимался a/b тестами и аналитикой: почему те или иные клиенты уходят в отток или переходят на новый тариф.
Самый вин был с моделью прогноза оттока общего количества абонентов, даже простые эвристики существенно улучшили точность существующей модели. Я к тому что не всегда нужно строить модели в xgboost`e, нужно в первую очередь решать бизнес задачи
В Tele2 работали совместно с @AndLukyane (Андрей Лукьяненко), он в представлении не нуждается. Андрей был в ml отделе, я в аналитике. Именно он сподвиг меня взять комп помощнее, что позволило вкатиться в #kaggle.
Процессы в мейле были налажены круче: ноут заменяли и чинили в тот же день, как и доступы и заявки. Зато сам бизнес tele2 был крупнее, в анализе была вся Россия. К сожалению, чем крупнее компания, тем все сложнее. Однако в крупн. компании стоит ожидать лучше налаженных процессов
В крупн. компании стоит ожидать лучше налаженных процессов в плане разработки, постановки задач, постановки целей и тд. Банально процесс повышения будет формализован и открыт
Насчет целей: важно чтобы отдельные отделы имели общие цели, от которых зависит годовая премия. Это все сильно улучшает кооперацию и мотивацию потратить время на чужие задачи. Забавно когда цели противоположные 😈
После всего этого я попал на свою текущую работу в Сбер и уже работаю здесь второй год. Что удивительно задачи не только про таблички, но есть и про NLP и CV. Хотя и направление про мониторинг кредитов
Благо про текущие проекты удалось рассказать даже на конфах.
Про табличные задачи и наш подход к интерпретации моделей - рассказывал на прошлом AI Journey youtu.be/NVD6FZZDdS4?t=…
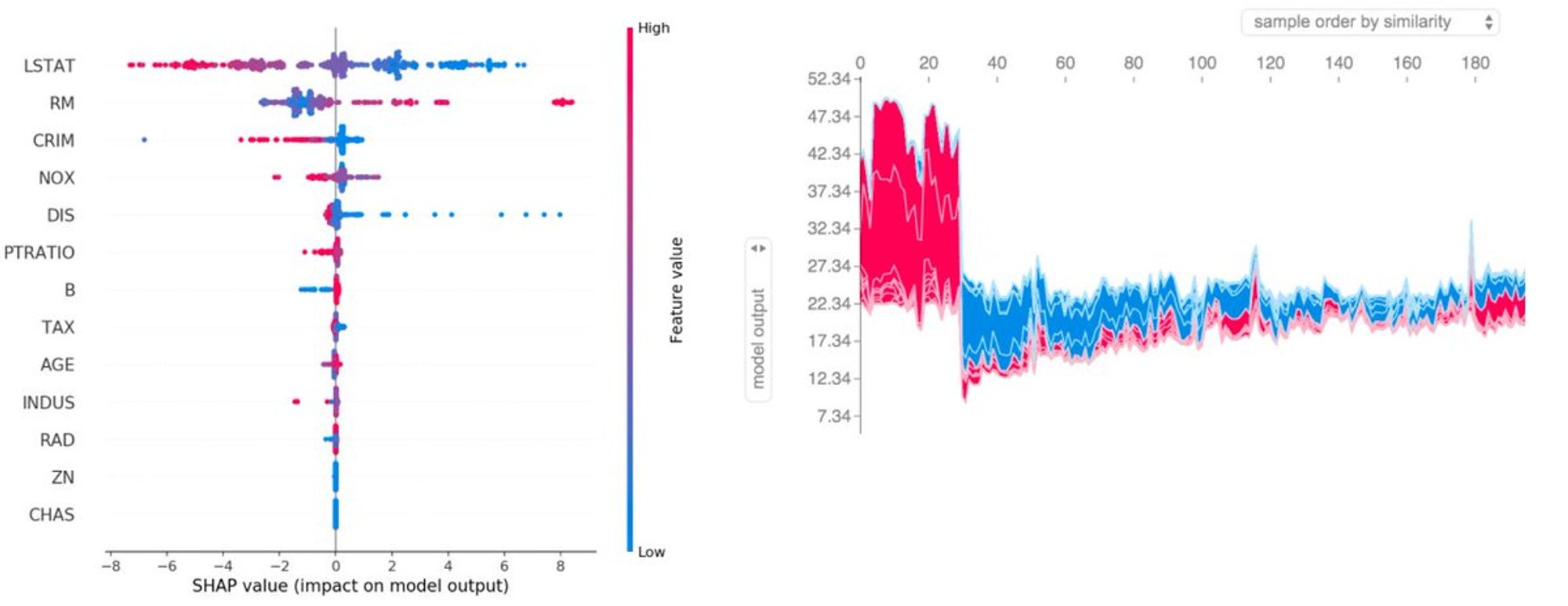
Если кратко строить небольшие модели для разных бизнес блоков с хорошими интерпретируемыми признаками, и далее пользователю выводить признаки, которые больше всего по SHAP увеличивают вероятность искомого негативного события.
Для интерпретируемости SHAP пожалуй лучшее из того, что придумали - github.com/slundberg/shap. Вы только посмотрите какие красивые графики там можно строить:
По CV рассказывал на последнем Датафесте youtube.com/watch?v=MOWbWH…
Про что доклад - есть строительство жилых зданий, за ходом строительство нужно следить. Есть прогресс есть, то банк может выдать новый транш по кредиту.
Кажется что натравить пачку моделей и дело в шляпе. На деле снимки дорогие, дома очень разные, банально от этажности дома будет сильно зависеть какую часть здания на снимке уже построили. Так или иначе было интересно заняться такой задачей.
Вторник
Про #kaggle уверен прошлые авторы рассказали много. Я на стороне что это очень полезный опыт. И почему это так - добавлю и свои 5 копеек. Про это и будет новый тред
Сам я набил 11 медалек, но золото не получил.
Так вот зачем нужен #kaggle:
Опыт решения новых задач: кернелы, обсуждения и тд. Пару курсов и пару конкурсов на кагле и я более менее смог разобраться в CV
В своих рабочих задачах - иногда можешь предложить нетривиальные решения
опыт взаимодействия с командой и тд. Если вдруг не пользовались гитом, то отличный момент чтобы начать им пользоваться
так как нужно уметь итеративно улучшать результаты, можно научиться лучше трекать результаты
По лучшие решения выкладывают здесь youtube.com/channel/UCeq6Z…
Там есть видео и с конференций, всячески рекомендую
Удачный опыт участия, не обязательно с призовым местом нужно максимально использовать:
набить блогпост на самом кагле. За это дают медальки, правда только за дискашен
причесав код, выложить его на github
набить статью на medium
написать о результате в твиттере, linkedIN
Изюминкой станет написание статьи. Успешно опубликовать на конференции может бы сложно, но на архив - почему бы и нет. Например мы как то раз так и поступили - arxiv.org/abs/1812.01429 , уже даже 9 цитирований.
Если кто знает где можно опубликовать paper без регистрации и смс, дайте знать. Многие конфы хотят 300+$, что кажется перебор
Какой у вас rank на кагле по соревнованиям?
Так, кажется, что большая часть не участвовала на кагле.
Вижу несколько причин, почему такое может быть:
сложно начать
нужны вычислительные ресурсы
время
Сложно начать. Как превозмочь:
смотрим решения прошлых аналогичных соревнований на самом кагле, гитхабе и ml trainings
текущий открытые решения, избегая бленды открытых решений, их время придет ближе к концу соревнований
изучить papers на архиве
почитать discussions
Вычислительные ресурсы:
иметь свою тачку приятнее всего
Colab (бесплатно) или Colab Pro $9.99/месяц. Работает очень шустро, советую сделать периодическое сохранение state модели на гугл диск
Сами kaggle kernels. С прошлого года появились квоты на GPU, надежнее чем Colab
Не забываем что можно объединиться с другими ребятами, которые рады сразу залететь в медальки и предоставить ресурсы. Искать на форуме или на ODS
Время:
Всегда верил, что это вопрос приоритетов. Могу рекомендовать сесть за выходные подбить пайплайн, который в будни будет перебирать решения
Соревнования идут 2-3 месяца, в целом можно спокойно заходить за месяц до конца. Как раз найдут все лики
можно участвовать в хакатонах, обычно они длятся в течение выходных, так что на них нужно меньше времени. Участников меньше, опыта можно ожидать тоже - как бонус больше шансов попасть в призовые
Тут @DanevskiyD накинул еще причину: Думаю, самое сложное - ответить себе на вопрос "зачем"?
Верю что человеку в первую очередь должно быть интересно, многие в участии видят даже азарт. Ведь каждая сорева - длинный забег. Когда отсутствие коммитов очень быстро сдвигает тебя вниз
А ну еще и покекать
Знания, деньги, и тд и тд - только как бонус😅
Среда
Начнем тред про сomputer vision (cv). Кажется что задачи классификации и сегментации в целом решена, и очень хорошо. То есть при достаточном количестве данных можно получить качество даже лучше чем человек.
Но данные размечать дорого, и вроде здесь начинают работать разные few shot алгоритмы, semi supervised подходы. Последнее отлично работает и когда текущая модель очень хорошая, но есть неразмеченные данные.
Можно соответственно дообучить модель на псевдолейблах. Ну или сделать качественный претрейн на другом большом датасете, не только imagenet. Semi supervised подходы - для кагла, уже обязательный пункт, даже если в хочется попасть только в бронзу.
Few shot алгоритмы. Давайте обзорно посмотрим текущую соту. Few shot обучение, это когда у тебя, обычно, всего 1 или 5 картинок на каждый класс.
PS Sota`у с кодом смотреть здесь paperswithcode.com/sota
Так вот в few shot алгоритмах - лучшее вот это "Leveraging the Feature Distribution in Transfer-based Few-Shot Learning" arxiv: [arxiv.org/abs/2006.03806]
code: github.com/yhu01/PT-MAP
Статья отличная и дает обзор других алгоритмов.
Что делали раньше, накидывали аугов, semi и self supervised методы как выше. Так же много meta learning, то есть подход при котором вытаскиваем мета-фичи и в самом простом случае по l2 норме собираем вместе одинаковые классы, такое очень часто практикуется в face recognition.
Ребята же в этой статье делают ставку на гипотезу, что признаки одного класса имеют свое определенное распределение. Кратко суть их подхода: фичи с бэкбона с претрейна на другом датасете (проверяли на ResNet18, wide resnet, DenseNet121).
Преобразовывают так, чтобы распределение внутри каждого класса стало больше приближено к гауссовскому. По сути это некое степенное преобразование аналогичное Tukey’s Transformation Ladder (не смог найти русское наименование). Оно же отлично помогает избежать перекоса в данных.
Далее у нас в пространстве фичей несколько сэмплов каждого класса и нужно найти наиболее робастные центры каждого класса. Соответственно они показывают, что максимизация апостериорной вероятность есть задача минимизации расстояния Wasserstein`a.
Ну и далее итеративно приходят к искомому решению используя так называемый Sinkhorn mapping, что по сути есть решение системы уравнений через матричное разложение.
Как итог 82% точности на 1-shot задаче, тогда так бейзлайн с обычным resnet18 дает менее 52% точности. При 5-shot подходе же получаем уже 88,8% точности. Датасеты специфичные и инфы сколько можно получить использую нормальный датасет-нет, но можно предполагать 90-95% точности
Очевидно, полученный скор можно значительно улучшить при наличии хорошего размеченного датасета, однако я вижу большую перспективу в таких решениях. Очень хотелось бы бесплатных тулзов, которые под капотом имели такие модели, и помогали размечать данные
В NLP - такие исследования тоже ведутся - paperswithcode.com/paper/few-shot… Верю что там тоже свой продвинутый meta-learning
Читая сота решения, не забывайте про прошлые статьи. В разных доменах могут работать разные решения

Зачем открытые датасеты, когда есть лидерборд на #kaggle

"Все счастливые семьи похожи друг на друга, каждая несчастливая семья несчастлива по-своему" - как говорил классик.
Начнем же тред про необходимые факторы, чтобы ds проект взлетел и дошел до прода, ведь причины почему провалился проект всегда много
Все совпадения случайны, истории вымышлены и выдуманы
Для начала всегда поймите, что хочет от вас бизнес. Если требования не ясны, не реализуемы - приземляйте их на ваши реалии.
То есть если кто-то хочет точности 100% - бегите, или меняйте метрику, чтобы результат был достижимым. Иначе окажитесь на пути полных разочарований и непреодолимых препятствий

С другой стороны если что-то бизнес очень хочет, но у вас свой вижен. Приоритизируйте в начале хотелки бизнеса, быть может вы не знаете всех деталей и тд, а вашу идею реализуйте как дополнение. Так вы покажите, что понимаете что от вас хотят, и мыслите шире с другой
В какой-то момент время на research уже не будет, и нужно показывать результат. И здесь важно понимать, что важнее еще +0.1% точности или работающий прод код (подсказка это второе)
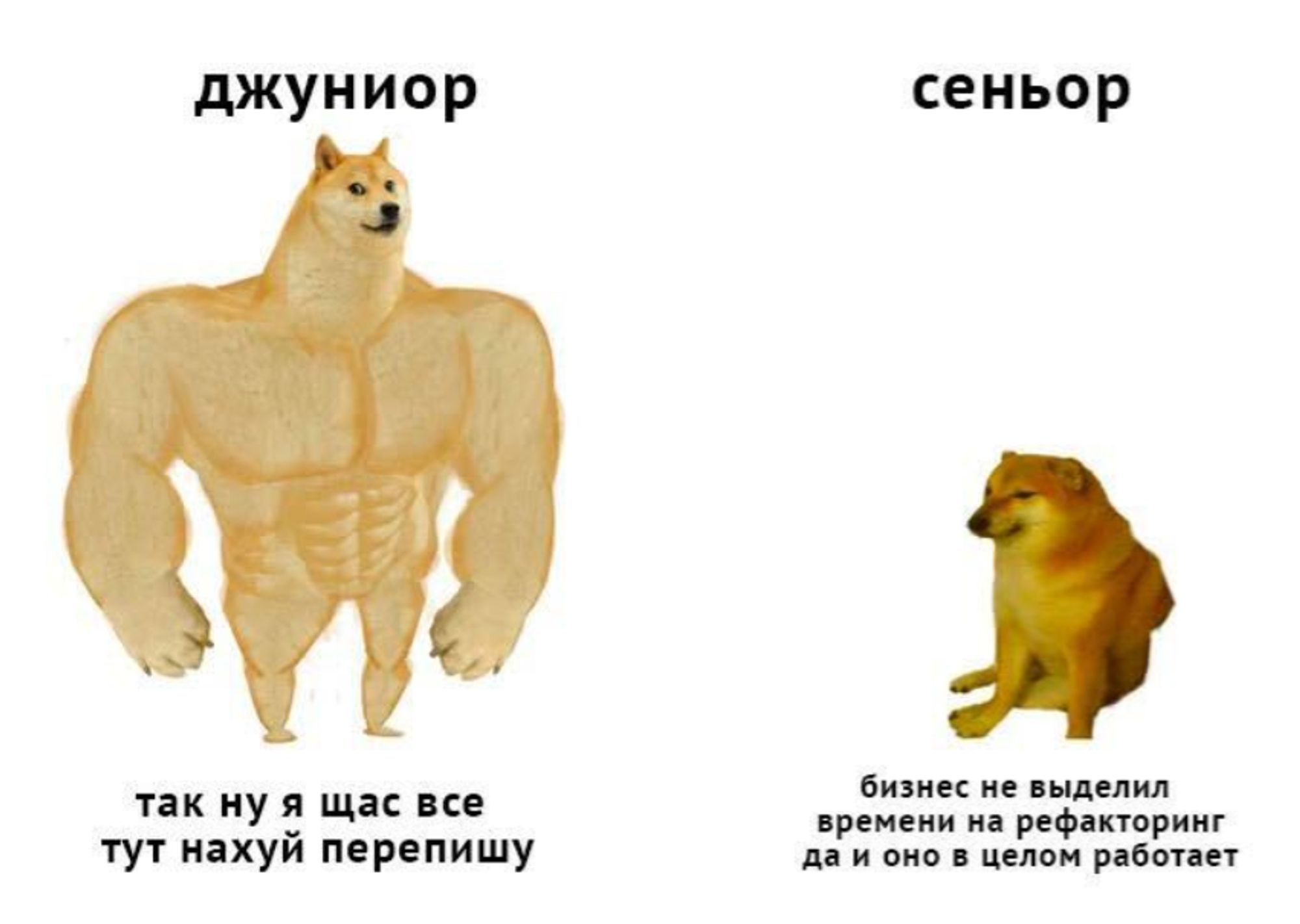
Забавно что в реальных проектах подход кагла не работает где важно построить звездолет помощнее и побольше. Ведь на кагле важна твоя позиция на лидерборде. На работе успех проекта сильно больше многограннее
Экономика тоже важно: нужно сразу трезво оценить сколько ресурсов займет разметка, какие данные уже есть, а какие данные отдельно придется тащить в прод. Нужна ли будет поддержка модели и тд. В таких случаях ищите золотую середину
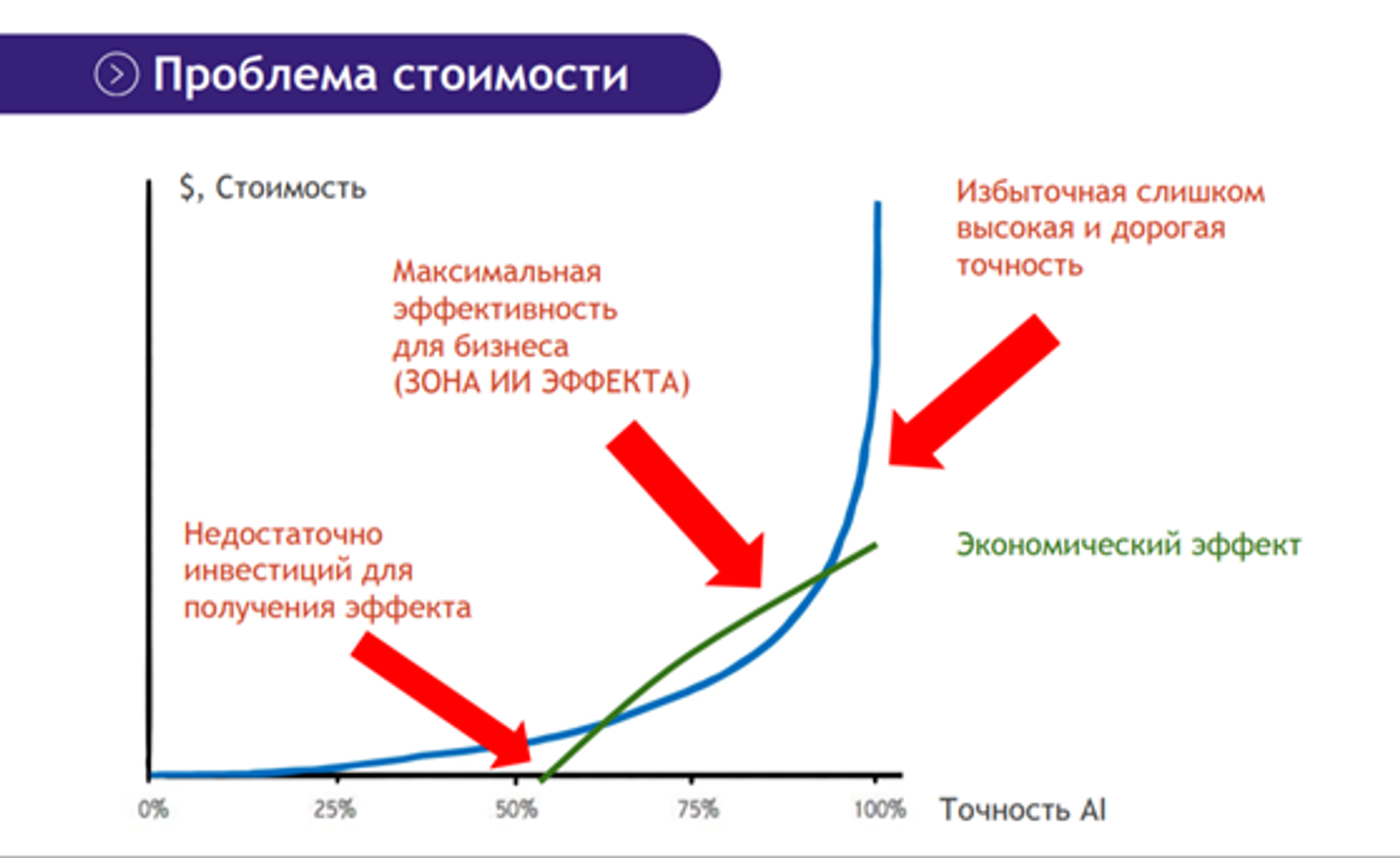
Картинка выше и ведьмаком по горам из докладов LeanDS (tg t.me/leands)
Если вдруг нужно найти причины провала можно посмотреть здесь github.com/xLaszlo/datasc…
Для успеха проекта важен хороший менеджмент, и не важно какая у вас позиция джун или сеньор - в ваших интересах проявить инициативу. Как это делать лучше крайне рекомендую прочитать книжку Rise, ее много рекомендуют в ODS. Она и про построение карьеры goodreads.com/book/show/1283…
Красивая презентация, довольный бизнес, проект в проде и реальные пользователи

Четверг
Тред про GANы
Еще одна в CV в которую я верю - это GANы. Лица людей , собак и кошек - они генерируют просто не отличимых от настоящих. При этом это не просто комбинация картинок в трейне, генерируются в действительно что-то новое.
Пример сгенерированных изображений, правда выбранных вручную. Но обратите на фон:
Cтоит ганам усложнить задачу - добавить нестандартный фон - и тут GANы теряются. Обратите внимание на картинки, которые генерируют sota в ганах, фон можно сказать всегда размыт.
Много чего придумали безумно крутого в цифровых аватарах и во всей этой теме. Pose estimation и тд
Но мне особенно понравилась работа от nvidia Gaugan, в целом это такое наследие от pix2pix. Когда по входной маске нужно предсказать исходную картинку. У них крутое демо - попробойте nvidia-research-mingyuliu.com/gaugan
Я здесь просто нарисовал море и мост к горе, с цветочками и деревом. Огрехи видны, но если посмотреть что было на входе, то очень неплохо

Тема мало форситься, но оказывается можно ганы использовать и для табличных данных. Работают, скажу честно - не так хорошо. Сложности с специфичным распределениями, при использовании большого кол-ва признаков, свои сложности с категориальными признаками
Ключевые работы следующие
Lei Xu LIDS, Kalyan Veeramachaneni. Synthesizing Tabular Data using Generative Adversarial Networks (2018). arXiv:1811.11264v1 [cs.LG]
Lei Xu, Maria Skoularidou, etc. Modeling Tabular Data using Conditional GAN (2019). arXiv:1907.00503v2
Зачем нужны такие данные:
сгенерировать анонимизированные данные, но с аналогичным распределением исходного датасета
генерация новых данных для использования с псевдолейблами и тд
в целом чтобы на сгенерированых данных модель в итоге обучалась не хуже
Я даже по тебе набил статью на архиве arxiv.org/pdf/2010.00638… который приняли на noname конфу. Она же на медиуме towardsdatascience.com/review-of-gans…
И на гитхабе github.com/Diyago/GAN-for…
Если хотите изучать ганы - очень советую книгу GANs in Action: Deep Learning with Generative Adversarial Networks
Там начиная с основ до вполне современных решений, код на tf, но его при желании можно перебить на pytorch amazon.com/GANs-Action-le…
Пятница
Срочные важные задачи на работе, и не удалось написать в течение дня. В целом такого быть не должно. Хорошее планирование с правильной приоритезацией должно помощь избежать такого.
Открываю тред по планированию
Устранения бутылочного горлышка в проектах как чуть ли не самый важный фактор в увеличении производительности проектов, и про планирование. Все это очень хорошо описано в книге "Критическая цепь", написано в стиле бизнес-романа, крайне рекомендую go-gl.com/xZH
Еще один бизнес-роман уже про DevOps и соответственно приближенный к IT проектам в книге "Проект "Феникс". Роман о том, как DevOps меняет бизнес к лучшему"
livelib.ru/book/100111989…
Последний бизнес-роман на сегодня, но возможно еще интереснее предыдущих. Задача глобальнее, и на первый взгляд кажется, что герою никак не решить. Нужно буквально построить звездолет в пустыне.
Все в книге "Deadline. Роман об управлении проектами" goo.su/2O09
*Бизнес-роман это как обычный роман со своими героями, обычной жизнью. Но которые решают свою бизнес задачу, делают ошибки, но верно идут к цели. Как итог обычный научпол получает немного эмоциальности, легче сопоставить сухие советы с реальной жизнью
Прокрастинация - зло, укреплять силу воли как решение. Кому-то помогает медитация, новый способ организации работы и тд. Большая часть книг по тему безумно скучные, но это очень рекомендую livelib.ru/book/100207027…
Быть может на работе не хватает эмоционального драйва, правильной отдачи. Почитайте "Эмоциональная гибкость. Как научиться радоваться переменам и получать удовольствие от работы и жизни"
livelib.ru/book/100231070…
Если хочет немного больше физиологических подробностей силы воли, то это есть в книге "Воля и самоконтроль. Как гены и мозг мешают нам бороться с соблазнами". Быть может все дело в генах 😅
livelib.ru/book/100267179…
Про концентрацию рекомендую книгу "Максимальная концентрация. Как сохранить эффективность в эпоху клипового мышления". Кажется что актуально, ну и название книги говорящее livelib.ru/book/100105908…
Как часто читаете книги? Не важно художественная/научпол или техническая
@dsunderhood Когда уже дсандерхуд буду вести простые пацаны из лестеха, а не гении из физтеха? Требую больше простых работяг, которые будут рассказывать о карьере простого работяги
Приглашаются еще авторы: участвуйте сами, приглашайте друзей и интересных вам людей twitter.com/cocoryse/statu…
Суббота
Новый тред про собеседования. Кажется в качестве собеседующего я провел сильно больше чем был сам собеседуемым.
Дальше немного советов как пройти успешно собеседования и найти работу, которая будет интересна
Любой поиск работы начинается обычно с hh.ru Но не забывайте и альтернативные источники ods, сообщения в linkedIn.
Рефералы увеличивают вероятность попасть на собеседования , поищите в linkedIn - возможно кто-то уже работает в компании вашей мечты
Если нет знакомых, напишите рандондым чувакам, с просьбой прокинуть резюме. Это работает
Первый этап - hr. Бывают внешние(внештатники) или внутренние. Не скажу что внешние хуже, они сговорчивее и могут сразу выдать вилку по позиции.
При общении с ними нужно быть просто адекватным и уметь повторить то, что написано в резюме. Если позвонили, значит опыт уже подходит
Уже с этапа hr - важно понимать сколько хотите денег. Вилку можно оценить по форумам, ods и тд. Но нужно иметь ввиду премиальную часть, которая ваше чем выше собеседуемая позиция
Ах да до общения с hr - сделайте хорошее резюме. Уместите все на одну страницу, если не влезает - уберите нерелевантный список, уменьшите отступы. Как вариант вот этот сайт cvmkr.com - там есть лаконичные шаблоны.
В резюме акцентируйте на готовых проектах, особенно тех которые принесли результат и/или дошли до прома. При составлении резюме в начале про текущую работу, и далее прошлый опыт.
Кратко можно указать с чем умеешь работать, например python, sql, spark, ml.
Не нужно указывать что умеешь в deep learning, а в опыте только обучение сеток на mnist`e и курс на степике.
Фотография в резюме. Сейчас тренд что это не нужно. Мой совет - пусть лучше будет. Через несколько недель + 10 кандидатов, вспомнить без фоток по резюме бывает сложно
Помните резюме не только для hr, оно нужно и для технического собеседования.
И так вам предстоит техническое собеседование на позицию ds или аналитика. Что можно повторить:
sql, питон, ml. Если первые два используете на работе - сложностей не должно возникнуть.
Мало кто спрашивает задачи с leetcode, еще меньше применяет на работе.
Что нужно знать в SQL:
- базовые операторы select, from join, having where group by, sum
- оконные функции
Как изучить: первые 50+ задач с sql-ex.ru последующие задачи из-за кривых схем БД не очень
- советую книгу T-SQL Fundamentals - для изучения с 0
Забавно что большая часть кандидатов не может ответить на вопрос: сколько записей (min и max) можно получить после inner join двух таблиц размерами 5 и 10 строк соответственно.
Питон - можно изучать долго, просто посоветую хороших книг:
Python cookbook
The programmatic programmer
the clean coder
Fluent Python
Working Effectively with Legacy Code by by Michael C. Feathers
Agile Principles, Patterns, and Practices in C# язык другой но не суть
На собеседовании если сможете развернуть список, написать пару циклов, работать со словарем - уже неплохо. Многие не могут и такого
Расскажите по паттерны программирования с ООП - будете на коне 😅😅
На самом собеседовании будьте честны и адекватны. Не нужно отвечать односложно, но и говорить не умолкая тоже не стоит. Вы удивитесь как много людей готовы чуть ли не самим собой час разговаривать.
Некоторые вопросы предполагают однозначный ответ, на некоторые важен не ответ, а рассуждения. Если не знаете ответа на первый тип вопросов лучше сразу сказать об этом.
В целом если понимаете что работа не для вас - собеседование можно закончить досрочно, сэкономите время всем
Не стоит быть излишне вальяжным. Один раз собеседуемый пил колу и закинул ноги на соседней стул.
Пожалуйста - не надо так 😅
Take home или домашка после собеса - обычная практика. Их не очень любят, но это все равно лучший способ оценить технические навыки кандата.
Если вас просят что-то доделать, советую сделать, ведь значит в вас заинтересованы
Если больше недели нет обратной связи имеет смысл спросить у HR про ваш статус. Но могу сказать что хороших кандидатов не забывают
Использовать аргумент, что у вас оффер и хотелось бы решение по вам быстрее - я бы не советовал
К тому что вас не возьмут - надо быть готовым. И на это могут разные причины, и в том числе самые неочевидные
Так что я советовал бы собеседоваться сразу во много мест
Для полноты докину примеры вопросов про ML
- схемы валидации, как использовать кросс-валидацию
- отбор признаков
- гиперпараметры бустинга
- беггинг, блендинг, стекинг
- метрики vs loss функции
и тд
Воскресенье
Какие вопросы задать на собеседование самому. Они про то, чтобы понимать самому куда, с кем и над чем идете работать:
- какой размер команды, какие роли
- последние успешные проекты команды
- какие задачи будут у нового сотрудника
- кто ставит задачи, откуда они приходят
Возможно у вас в компании не построена адекватный процесс управления проектами. Переходите на гибкие методологии. Идейно очень крутая вещь. Рекомендую книгу "Scrum. Революционный метод управления проектами
" - от самого создателя Scrum goo.su/2OHH
Чем выше собеседуемая вами позиция - тем большую роль начинают играть софт скилы: общение с бизнесом, да просто правильно рассказать про свой проект. Без общения никак
Развивайте софт скилы
Как писать письма - изучите книгу Как писать письма - изучите книгу "Новые правила деловой переписки" - livelib.ru/book/100286102…
Ее нужно включать в школьную программу 😅
Для понимания основ лаконичного текста-Пиши и Сокращай. Как создавать сильный текст
Общение это так или иначе про переговоры. Могу по теме посоветовать:
- Договориться можно обо всем! Как добиваться максимума в любых переговорах livelib.ru/book/100153526…
- Переговоры с монстрами. Как договориться с сильными мира сего livelib.ru/book/100287080…
На датафесте по теме могу посоветовать доклад Артура Кузина youtube.com/watch?v=dkp3we…
Здесь главное не закончить так

Всем спасибо кто был на этой неделе в коллективном ds твиттере. В следующие недели уже будут новые авторы
Подписывайтесь на меня:
- twitter.com/IAshrapov
- linkedin.com/in/iashrapov/
- github.com/Diyago
- medium.com/@insafashrapov
Статистика за неделю:
- 130+ тыс. просмотров
- 130+ твитов
- 600+ лайков
- 70+ подписчиков